En av de största problemen när man hanterar och hanterar databaser är dess data- och storlekskomplexitet. Ofta blir organisationer bekymrade över hur de ska hantera tillväxt och hantera tillväxtpåverkan eftersom databashanteringen misslyckas. Komplexitet kommer med problem som inte togs upp från början och som inte sågs eller kunde förbises eftersom tekniken som används för närvarande ska kunna hantera av sig själv. Hantera en komplex och stor databas måste planeras i enlighet därmed, särskilt när den typ av data du hanterar eller hanterar förväntas växa massivt, antingen förväntat eller på ett oförutsägbart sätt. Huvudmålet med planering är att undvika oönskade katastrofer, eller ska vi säga att inte gå upp i rök! I den här bloggen kommer vi att ta upp hur man effektivt hanterar stora databaser.
Datastorlek spelar roll
Storleken på databasen har betydelse eftersom den påverkar prestandan och dess hanteringsmetodik. Hur uppgifterna bearbetas och lagras kommer att bidra till hur databasen kommer att hanteras, vilket gäller både i transit och vilande data. För många stora organisationer är data guld, och tillväxt i data kan få en drastisk förändring i processen. Därför är det viktigt att ha tidigare planer för att hantera växande data i en databas.
I min erfarenhet av att arbeta med databaser har jag sett kunder som har problem med att hantera prestationspåföljder och hantera extrem datatillväxt. Frågor uppstår om man ska normalisera tabellerna kontra denormalisera tabellerna.
Normalisering av tabeller
Normalisering av tabeller bibehåller dataintegriteten, minskar redundans och gör det enkelt att organisera data på ett mer effektivt sätt att hantera, analysera och extrahera. Att arbeta med normaliserade tabeller ger effektivitet, särskilt när man analyserar dataflödet och hämtar data antingen med SQL-satser eller arbetar med programmeringsspråk som C/C++, Java, Go, Ruby, PHP eller Python-gränssnitt med MySQL-anslutningarna.
Även om problem med normaliserade tabeller har prestandastraff och kan sakta ner frågorna på grund av serier av joins när data hämtas. Medan denormaliserade tabeller, allt du behöver tänka på för optimering förlitar sig på indexet eller primärnyckeln för att lagra data i bufferten för snabbare hämtning än att utföra flera disksökningar. Denormaliserade tabeller kräver inga kopplingar, men det offras dataintegritet och databasstorleken tenderar att bli större och större.
När din databas är stor, överväg att ha en DDL (Data Definition Language) för din databastabell i MySQL/MariaDB. Att lägga till en primär eller unik nyckel för ditt bord kräver en ombyggnad av tabellen. Ändring av en kolumndatatyp kräver också en ombyggnad av tabellen eftersom den algoritm som ska tillämpas endast är ALGORITHM=COPY.
Om du gör detta i din produktionsmiljö kan det vara utmanande. Dubbla utmaningen om ditt bord är stort. Föreställ dig en miljon eller en miljard antal rader. Du kan inte tillämpa en ALTER TABLE-sats direkt på din tabell. Det kan blockera all inkommande trafik som behöver komma åt tabellen för närvarande du använder DDL. Detta kan dock mildras genom att använda pt-online-schema-change eller great gh-ost. Ändå kräver det övervakning och underhåll samtidigt som DDL-processen utförs.
Skärning och partitionering
Med sharding och partitionering hjälper det till att segregera eller segmentera data enligt deras logiska identitet. Till exempel genom att segregera baserat på datum, alfabetisk ordning, land, stat eller primärnyckel baserat på det givna intervallet. Detta hjälper din databasstorlek att vara hanterbar. Håll din databasstorlek upp till gränsen så att den är hanterbar för din organisation och ditt team. Lätt att skala vid behov eller lätt att hantera, särskilt när en katastrof inträffar.
När vi säger hanterbar, överväg också kapacitetsresurserna på din server och även ditt teknikteam. Du kan inte arbeta med stor och stor data med få ingenjörer. Att arbeta med big data såsom 1000 databaser med ett stort antal datamängder kräver ett enormt tidsbehov. Skicklighet och expertis är ett måste. Om kostnaden är ett problem, är det den tid som du kan utnyttja tredjepartstjänster som erbjuder hanterade tjänster eller betald konsultation eller support för sådant tekniskt arbete som ska tillgodoses.
Teckenuppsättningar och sortering
Teckenuppsättningar och sorteringar påverkar datalagring och prestanda, särskilt på den givna teckenuppsättningen och de valda sorteringarna. Varje teckenuppsättning och sortering har sitt syfte och kräver oftast olika längder. Om du har tabeller som kräver andra teckenuppsättningar och sorteringar på grund av teckenkodning, data som ska lagras och bearbetas för din databas och tabeller eller till och med med kolumner.
Detta påverkar hur du hanterar din databas effektivt. Det påverkar din datalagring och prestanda som tidigare nämnts. Om du har förstått vilken typ av tecken som ska behandlas av din ansökan, notera vilken teckenuppsättning och sortering som ska användas. LATIN-typer av teckenuppsättningar räcker mestadels för att den alfanumeriska typen av tecken ska lagras och bearbetas.
Om det är oundvikligt, hjälper fragmentering och partitionering att åtminstone mildra och begränsa data för att undvika att för mycket data sväller upp i din databasserver. Att hantera mycket stora data på en enda databasserver kan påverka effektiviteten, särskilt för säkerhetskopieringsändamål, katastrofer och återställning, eller dataåterställning i händelse av datakorruption eller förlorad data.
Databaskomplexitet påverkar prestanda
En stor och komplex databas tenderar att ha en faktor när det kommer till prestationsstraff. Komplex, i det här fallet, betyder att innehållet i din databas består av matematiska ekvationer, koordinater eller numeriska och finansiella poster. Blandade nu dessa poster med frågor som aggressivt använder de matematiska funktionerna som är inbyggda i dess databas. Ta en titt på SQL-exemplet (MySQL/MariaDB-kompatibel)-fråga nedan,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Tänk på att den här frågan tillämpas på en tabell som sträcker sig från en miljon rader. Det finns en stor möjlighet att detta kan stoppa servern, och det kan vara resurskrävande och orsaka fara för stabiliteten i ditt produktionsdatabaskluster. Inblandade kolumner tenderar att indexeras för att optimera och göra denna fråga presterande. Att lägga till index i de refererade kolumnerna för optimal prestanda garanterar dock inte effektiviteten i att hantera dina stora databaser.
När man hanterar komplexitet är det mer effektiva sättet att undvika rigorös användning av komplexa matematiska ekvationer och aggressiv användning av denna inbyggda komplexa beräkningskapacitet. Detta kan drivas och transporteras genom komplexa beräkningar med hjälp av backend-programmeringsspråk istället för att använda databasen. Om du har komplexa beräkningar, varför inte lagra dessa ekvationer i databasen, hämta frågorna, organisera dem till en mer lättanalyserad eller felsöka när det behövs.
Använder du rätt databasmotor?
En datastruktur påverkar databasserverns prestanda baserat på kombinationen av den angivna frågan och de poster som läses eller hämtas från tabellen. Databasmotorerna inom MySQL/MariaDB stödjer InnoDB och MyISAM som använder B-Trees, medan NDB eller Memory databasmotorer använder Hash Mapping. Dessa datastrukturer har sin asymptotiska notation som den senare uttrycker prestandan för de algoritmer som används av dessa datastrukturer. Vi kallar dessa inom datavetenskap som Big O-notation som beskriver prestandan eller komplexiteten hos en algoritm. Med tanke på att InnoDB och MyISAM använder B-Trees, använder den O(log n) för sökning. Medan Hash-tabeller eller Hash-kartor använder O(n). Båda delar genomsnittet och värsta fallet för dess prestanda med dess notation.
Nu tillbaks till den specifika motorn, givet motorns datastruktur, påverkar frågan som ska tillämpas baserat på måldata som ska hämtas naturligtvis prestandan för din databasserver. Hash-tabeller kan inte göra intervallhämtning, medan B-Trees är mycket effektiv för att göra dessa typer av sökningar och den kan också hantera stora mängder data.
Genom att använda rätt motor för den data du lagrar måste du identifiera vilken typ av fråga du använder för dessa specifika data du lagrar. Vilken typ av logik som dessa data ska formulera när de omvandlas till en affärslogik.
Att hantera 1000-tals eller tusentals databaser, använda rätt motor i kombination med dina frågor och data som du vill hämta och lagra ska ge bra prestanda. Med tanke på att du har förutbestämt och analyserat dina krav för dess syfte för rätt databasmiljö.
Rätt verktyg för att hantera stora databaser
Det är mycket svårt och svårt att hantera en mycket stor databas utan en solid plattform som du kan lita på. Även med bra och skickliga databasingenjörer, tekniskt sett är databasservern du använder benägen för mänskliga fel. Ett misstag av eventuella ändringar av dina konfigurationsparametrar och variabler kan resultera i en drastisk förändring som kan försämra serverns prestanda.
Att utföra säkerhetskopiering till din databas på en mycket stor databas kan ibland vara utmanande. Det finns tillfällen där säkerhetskopieringen kan misslyckas av några konstiga skäl. Vanligtvis orsakar frågor som kan stoppa servern där säkerhetskopieringen körs att misslyckas. Annars måste du undersöka orsaken till det.
Att använda automation som Chef, Puppet, Ansible, Terraform eller SaltStack kan användas som din IaC för att ge snabbare uppgifter att utföra. Medan du använder andra verktyg från tredje part också för att hjälpa dig att övervaka och tillhandahålla grafbilder av hög kvalitet. Varnings- och larmaviseringssystem är också mycket viktiga för att meddela dig om problem som kan uppstå från varning till kritisk statusnivå. Det är här ClusterControl är mycket användbart i den här typen av situationer.
ClusterControl gör det enkelt att hantera ett stort antal databaser eller till och med med sönderdelade typer av miljöer. Det har testats och installerats tusen gånger och har körts in i produktioner som ger larm och meddelanden till DBA:er, ingenjörer eller DevOps som driver databasmiljön. Allt från iscensättning eller utveckling, QAs, till produktionsmiljö.
ClusterControl kan också utföra en säkerhetskopiering och återställning. Även med stora databaser kan det vara effektivt och enkelt att hantera eftersom gränssnittet tillhandahåller schemaläggning och även har alternativ för att ladda upp det till molnet (AWS, Google Cloud och Azure).
Det finns också en backupverifiering och många alternativ som kryptering och komprimering. Se skärmdumpen nedan till exempel (att skapa en säkerhetskopia för MySQL med Xtrabackup):
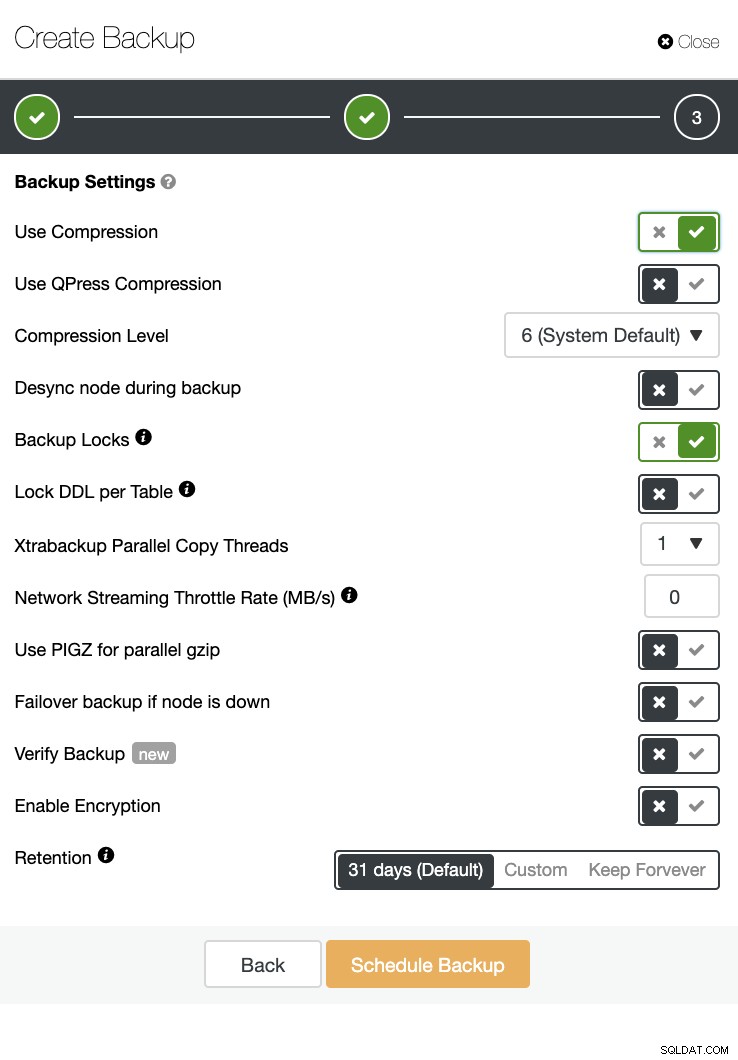
Slutsats
Hantera stora databaser som tusen eller fler kan göras effektivt, men det måste fastställas och förberedas i förväg. Att använda rätt verktyg som automatisering eller till och med prenumerera på hanterade tjänster hjälper drastiskt. Även om det medför kostnader kan vändningen av tjänsten och budgeten som ska läggas till för att skaffa skickliga ingenjörer minskas så länge som rätt verktyg finns tillgängliga.