Det här blogginlägget är en fortsättning på föregående del 1, där vi har täckt grunderna för SNMP-integrering med ClusterControl.
I det här blogginlägget kommer vi att fokusera på SNMP-fällor och varningar. SNMP-fällor är de mest använda varningsmeddelandena som skickas från en fjärransluten SNMP-enhet (en agent) till en central samlare, "SNMP-hanteraren". I fallet med ClusterControl kan en fälla vara en varning efter att det kritiska larmet för ett kluster inte är 0, vilket indikerar att något dåligt händer.
Som visades i det tidigare blogginlägget, för detta proof-of-concept, har vi två definitioner av SNMP-fällan:
criticalAlarmNotification NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification if critical alarm is not 0"
::= { alarmNotification 1 }
criticalAlarmNotificationEnded NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification ended - Critical alarm is 0"
::= { alarmNotification 2 }Aviserna (eller fällorna) är kritiska AlarmNotifikation och kritiska AlarmNotifikationEnded. Båda aviseringshändelserna kan användas för att signalera vår Nagios-tjänst, oavsett om klustret aktivt har kritiska larm eller inte. I Nagios är termen för detta passiv kontroll, varvid Nagios inte försöker avgöra om eller värd/tjänst är NED eller OÅTKOMST. Vi kommer också att konfigurera de aktiva kontrollerna, där kontrollerna initieras av kontrolllogiken i Nagios-demonen genom att använda tjänstdefinitionen för att även övervaka de kritiska/varningslarm som rapporteras av vårt kluster.
Observera att detta blogginlägg kräver att Severalnines MIB- och SNMP-agenten är korrekt konfigurerad som visas i den första delen av den här bloggserien.
Installera Nagios Core
Nagios Core är den kostnadsfria versionen av Nagios övervakningssvit. Först och främst måste vi installera det och alla nödvändiga paket, följt av Nagios plugins, snmptrapd och snmptt. Observera att instruktionerna i det här blogginlägget förutsätter att alla noder körs på CentOS 7.
Installera de nödvändiga paketen för att köra Nagios:
$ yum -y install httpd php gcc glibc glibc-common wget perl gd gd-devel unzip zip sendmail net-snmp-utils net-snmp-perlSkapa en nagios-användare och nagcmd-grupp för att tillåta externa kommandon att utföras via webbgränssnittet, lägg till nagios- och apache-användaren för att vara en del av nagcmd-gruppen:
$ useradd nagios
$ groupadd nagcmd
$ usermod -a -G nagcmd nagios
$ usermod -a -G nagcmd apacheLadda ner den senaste versionen av Nagios Core härifrån, kompilera och installera den:
$ cd ~
$ wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.6.tar.gz
$ tar -zxvf nagios-4.4.6.tar.gz
$ cd nagios-4.4.6
$ ./configure --with-nagios-group=nagios --with-command-group=nagcmd
$ make all
$ make install
$ make install-init
$ make install-config
$ make install-commandmodeInstallera Nagios webbkonfiguration:
$ make install-webconfValfritt kan du installera Nagios exfolieringstema (eller så kan du hålla dig till standardtemat):
$ make install-exfoliationSkapa ett användarkonto (nagiosadmin) för att logga in på Nagios webbgränssnitt. Kom ihåg lösenordet som du tilldelar den här användaren:
$ htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminStarta om Apache-webbservern för att få de nya inställningarna att träda i kraft:
$ systemctl restart httpd
$ systemctl enable httpdLadda ner Nagios Plugins härifrån, kompilera och installera det:
$ cd ~
$ wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
$ tar -zxvf nagios-plugins-2.3.3.tar.gz
$ cd nagios-plugins-2.3.3
$ ./configure --with-nagios-user=nagios --with-nagios-group=nagios
$ make
$ make installVerifiera Nagios standardkonfigurationsfiler:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Nagios Core 4.4.6
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 2020-04-28
License: GPL
Website: https://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking objects...
Checked 8 services.
Checked 1 hosts.
Checked 1 host groups.
Checked 0 service groups.
Checked 1 contacts.
Checked 1 contact groups.
Checked 24 commands.
Checked 5 time periods.
Checked 0 host escalations.
Checked 0 service escalations.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 5 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
If everything looks okay, start Nagios and configure it to start on boot:
$ systemctl start nagios
$ systemctl enable nagiosÖppna webbläsaren och gå till https://{IPaddress}/nagios och du bör se en grundläggande HTTP-autentisering dyker upp där du måste ange användarnamnet som nagiosadmin med ditt valda lösenord skapat tidigare.
Lägger till ClusterControl-server i Nagios
Skapa en Nagios-värddefinitionsfil för ClusterControl:
$ vim /usr/local/nagios/etc/objects/clustercontrol.cfgOch lägg till följande rader:
define host {
use linux-server
host_name clustercontrol.local
alias clustercontrol.mydomain.org
address 192.168.10.50
}
define service {
use generic-service
host_name clustercontrol.local
service_description Critical alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.2 -c0
}
define service {
use generic-service
host_name clustercontrol.local
service_description Warning alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.3 -w0
}
define service {
use snmp_trap_template
host_name clustercontrol.local
service_description Critical alarm traps
check_interval 60 ; Don't clear for 1 hour
}
Några förklaringar:
-
I det första avsnittet definierar vi vår värd, med värdnamnet och adressen till ClusterControl-servern.
-
Servicesektionerna där vi lägger våra tjänstdefinitioner för att övervakas av Nagios. De två första säger i princip åt tjänsten att kontrollera SNMP-utgången för ett visst objekt-ID. Den första tjänsten handlar om det kritiska larmet, därför lägger vi till -c0 i kommandot check_snmp för att indikera att det ska vara en kritisk varning i Nagios om värdet går över 0. Medan för varningslarmen kommer vi att indikera det med en varning om värdet är 1 och högre.
-
Den sista tjänstdefinitionen handlar om de SNMP-fällor som vi förväntar oss kommer från ClusterControl-servern om det kritiska larmet höjt är högre än 0. Det här avsnittet kommer att använda snmp_trap_template-definitionen, som visas i nästa steg.
Konfigurera snmp_trap_template genom att lägga till följande rader i /usr/local/nagios/etc/objects/templates.cfg:
define service {
name snmp_trap_template
service_description SNMP Trap Template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized
process_perf_data 0
obsess_over_service 0 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
check_command check-host-alive ; This will be used to reset the service to "OK"
is_volatile 1
check_period 24x7
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
contact_groups admins ; Modify this to match your Nagios contactgroup definitions
register 0
}
Inkludera ClusterControl-konfigurationsfilen i Nagios genom att lägga till följande rad i
/usr/local/nagios/etc/nagios.cfg:
cfg_file=/usr/local/nagios/etc/objects/clustercontrol.cfgKör en konfigurationskontroll före flygning:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgSe till att du får följande rad i slutet av utdata:
"Things look okay - No serious problems were detected during the pre-flight check"Starta om Nagios för att ladda ändringen:
$ systemctl restart nagiosOm vi nu tittar på Nagios-sidan under Service-sektionen (menyn till vänster), skulle vi se något sånt här:
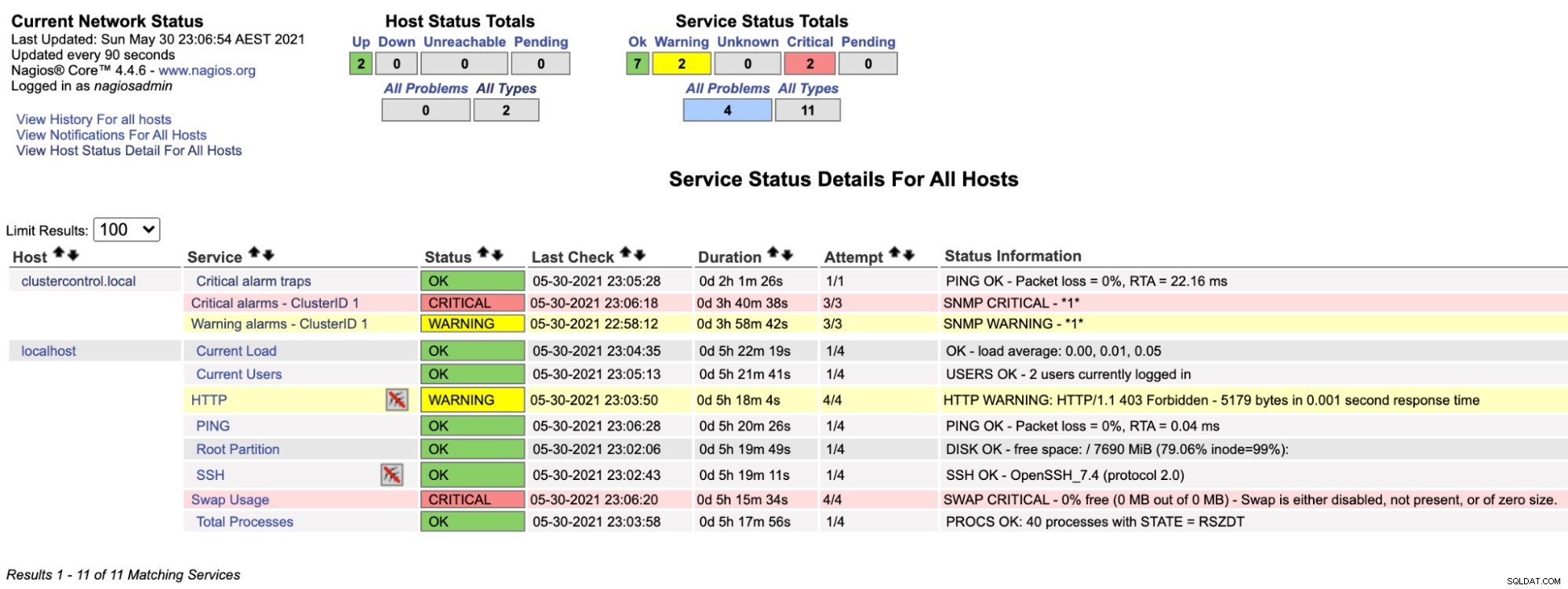
Lägg märke till att raden "Kritiska larm - ClusterID 1" blir röd om det kritiska larmvärdet som rapporteras av ClusterControl är större än 0, medan "Varningslarm - ClusterID 1" är gult, vilket indikerar att ett varningslarm har aktiverats. Om inget intressant händer, skulle du se att allt är grönt för clustercontrol.local.
Konfigurera Nagios för att ta emot en fälla
Fällor skickas av fjärrenheter till Nagios-servern, detta kallas en passiv kontroll. Helst vet vi inte när en fälla kommer att skickas eftersom det beror på att den sändande enheten bestämmer sig för att skicka en fälla. Till exempel med en UPS (batteribackup), så snart enheten tappar ström, kommer den att skicka en fälla för att säga "hej, jag tappade ström". På så sätt informeras Nagios omedelbart.
För att ta emot SNMP-fällor måste vi konfigurera Nagios-servern med följande saker:
-
snmptrapd (SNMP trap-mottagardemon)
-
snmptt (SNMP Trap Translator, traphanterarens daemon)
Efter att snmptrapd tar emot en fälla kommer den att skicka den till snmptt där vi konfigurerar den för att uppdatera Nagios-systemet och sedan skickar Nagios ut varningen enligt kontaktgruppens konfiguration.
Installera EPEL-förvaret, följt av de nödvändiga paketen:
$ yum -y install epel-release
$ yum -y install net-snmp snmptt net-snmp-perl perl-Sys-SyslogKonfigurera SNMP trap-demonen på /etc/snmp/snmptrapd.conf och ställ in följande rader:
disableAuthorization yes
traphandle default /usr/sbin/snmptthandlerOvanstående betyder helt enkelt att fällor som tas emot av snmptrapd-demonen kommer att skickas över till /usr/sbin/snmptthandler.
Lägg till SEVERALNINES-CLUSTERCONTROL-MIB.txt i /usr/share/snmp/mibs genom att skapa /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt:
$ ll /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt
-rw-r--r-- 1 root root 4029 May 30 20:08 /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txtSkapa /etc/snmp/snmp.conf (notiser utan "d") och lägg till vår anpassade MIB där:
mibs +SEVERALNINES-CLUSTERCONTROL-MIBStarta snmptrapd-tjänsten:
$ systemctl start snmptrapd
$ systemctl enable snmptrapdDärefter måste vi konfigurera följande konfigurationsrader inuti /etc/snmp/snmptt.ini:
net_snmp_perl_enable = 1
snmptt_conf_files = <<END
/etc/snmp/snmptt.conf
/etc/snmp/snmptt-cc.conf
ENDObservera att vi aktiverade net_snmp_perl-modulen och har lagt till en annan konfigurationssökväg, /etc/snmp/snmptt-cc.conf inuti snmptt.ini. Vi måste definiera ClusterControl snmptt-händelser här så att de kan skickas till Nagios. Skapa en ny fil på /etc/snmp/snmptt-cc.conf och lägg till följande rader:
MIB: SEVERALNINES-CLUSTERCONTROL-MIB (file:/usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt) converted on Sun May 30 19:17:33 2021 using snmpttconvertmib v1.4.2
EVENT criticalAlarmNotification .1.3.6.1.4.1.57397.1.1.3.1 "Status Events" Critical
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 2 "Critical - Critical alarm is $1 for cluster ID $2"
SDESC
Notification if critical alarm is not 0
Variables:
1: totalCritical
2: clusterId
EDESC
EVENT criticalAlarmNotificationEnded .1.3.6.1.4.1.57397.1.1.3.2 "Status Events" Normal
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 0 "Normal - Critical alarm is $1 for cluster ID $2"
SDESC
Notification ended - critical alarm is 0
Variables:
1: totalCritical
2: clusterId
EDESCNågra förklaringar:
-
Vi har två fällor definierade - criticalAlarmNotification och criticalAlarmNotificationEnded.
-
CriticalAlarmNotification ger helt enkelt en kritisk varning och skickar den till tjänsten "Kritiska larmfällor" definierad i Nagios. $aA betyder att returnera trapagentens IP-adress. Värdet 2 är kontrollresultatvärdet som i detta fall är kritiskt (0=OK, 1=VARNING, 2=KRITISK, 3=OKÄNT).
-
The criticalAlarmNotificationEnded ger helt enkelt en OK-varning och skickar den till tjänsten "Kritiska larmfällor" för att avbryta föregående fälla efter att allt återgår till det normala. $aA betyder att returnera trapagentens IP-adress. Värdet 0 är kontrollresultatvärdet som i det här fallet är OK. För mer information om strängbyten som känns igen av snmptt, kolla in den här artikeln under "FORMAT".
-
Du kan använda snmpttconvertmib för att generera en snmptt-händelsehanterarfil för en viss MIB.
Observera att händelsehanterarens sökväg som standard inte tillhandahålls av Nagios Core. Därför måste vi kopiera den händelsehanterarens katalog från Nagios-källan under bidragskatalogen, som visas nedan:
$ cp -Rf nagios-4.4.6/contrib/eventhandlers /usr/local/nagios/share/
$ chown -Rf nagios:nagios /usr/local/nagios/share/eventhandlersVi måste också tilldela snmptt-gruppen som en del av nagcmd-gruppen, så att den kan köra nagios.cmd i submit_check_result-skriptet:
$ usermod -a -G nagcmd snmpttStarta snmptt-tjänsten:
$ systemctl start snmptt
$ systemctl enable snmpttSNMP-hanteraren (Nagios-servern) är nu redo att acceptera och bearbeta våra inkommande SNMP-fällor.
Skicka en trap från ClusterControl-servern
Anta att man vill skicka en SNMP-fälla till SNMP-hanteraren, 192.168.10.11 (Nagios-server) eftersom det totala antalet kritiska larm har nått 2 för kluster-ID 1, skulle man köra följande kommando på ClusterControl-servern (klientsidan), 192.168.10.50:
$ snmptrap -v2c -c private 192.168.10.11 '' SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification \
SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical i 2 \
SEVERALNINES-CLUSTERCONTROL-MIB::clusterId i 1Eller i OID-format (rekommenderas):
$ snmptrap -v2c -c private 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.1 \
.1.3.6.1.4.1.57397.1.1.1.2 i 2 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Där, .1.3.6.1.4.1.57397.1.1.3.1 är lika med criticalAlarmNotification trap-händelse, och de efterföljande OID är representationer av det totala antalet aktuella kritiska larm respektive kluster-ID:n .
På Nagios-servern bör du märka att trap-tjänsten har blivit röd:
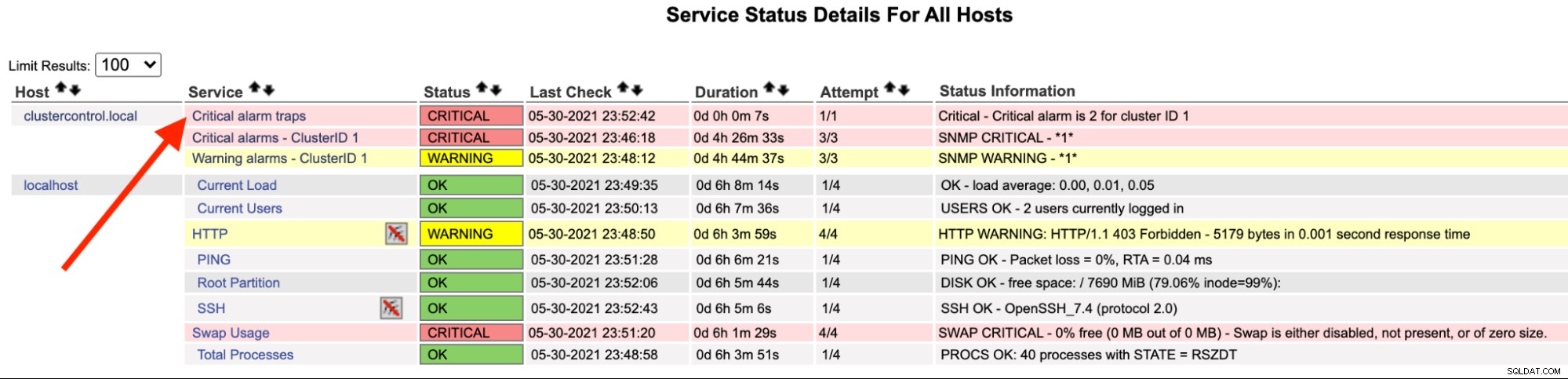
Du kan också se det i /var/log/messages på följande rad:
May 30 23:52:39 ip-10-15-2-148 snmptrapd[27080]: 2021-05-30 23:52:39 UDP: [192.168.10.50]:33151->[192.168.10.11]:162 [UDP: [192.168.10.50]:33151->[192.168.10.11]:162]:#012DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (2423020) 6:43:50.20#011SNMPv2-MIB::snmpTrapOID.0 = OID: SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification#011SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical = INTEGER: 2#011SEVERALNINES-CLUSTERCONTROL-MIB::clusterId = INTEGER: 1
May 30 23:52:42 nagios.local snmptt[29557]: .1.3.6.1.4.1.57397.1.1.3.1 Critical "Status Events" UDP192.168.10.5033151-192.168.10.11162 - Notification if critical alarm is not 0
May 30 23:52:42 nagios.local nagios: EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;192.168.10.50;Critical alarm traps;2;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: PASSIVE SERVICE CHECK: clustercontrol.local;Critical alarm traps;0;PING OK - Packet loss = 0%, RTA = 22.16 ms
May 30 23:52:42 nagios.local nagios: SERVICE NOTIFICATION: nagiosadmin;clustercontrol.local;Critical alarm traps;CRITICAL;notify-service-by-email;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: SERVICE ALERT: clustercontrol.local;Critical alarm traps;CRITICAL;HARD;1;Critical - Critical alarm is 2 for cluster ID 1När larmet har löst sig, för att skicka en normal fälla, kan vi utföra följande kommando:
$ snmptrap -c private -v2c 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.2 \
.1.3.6.1.4.1.57397.1.1.1.2 i 0 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Där, .1.3.6.1.4.1.57397.1.1.3.2 är lika med händelsen criticalAlarmNotificationEnded, och de efterföljande OID:erna representerar det totala antalet aktuella kritiska larm (ska vara 0 i detta fall ) respektive kluster-ID.
På Nagios-servern bör du märka att trap-tjänsten är tillbaka till grön:
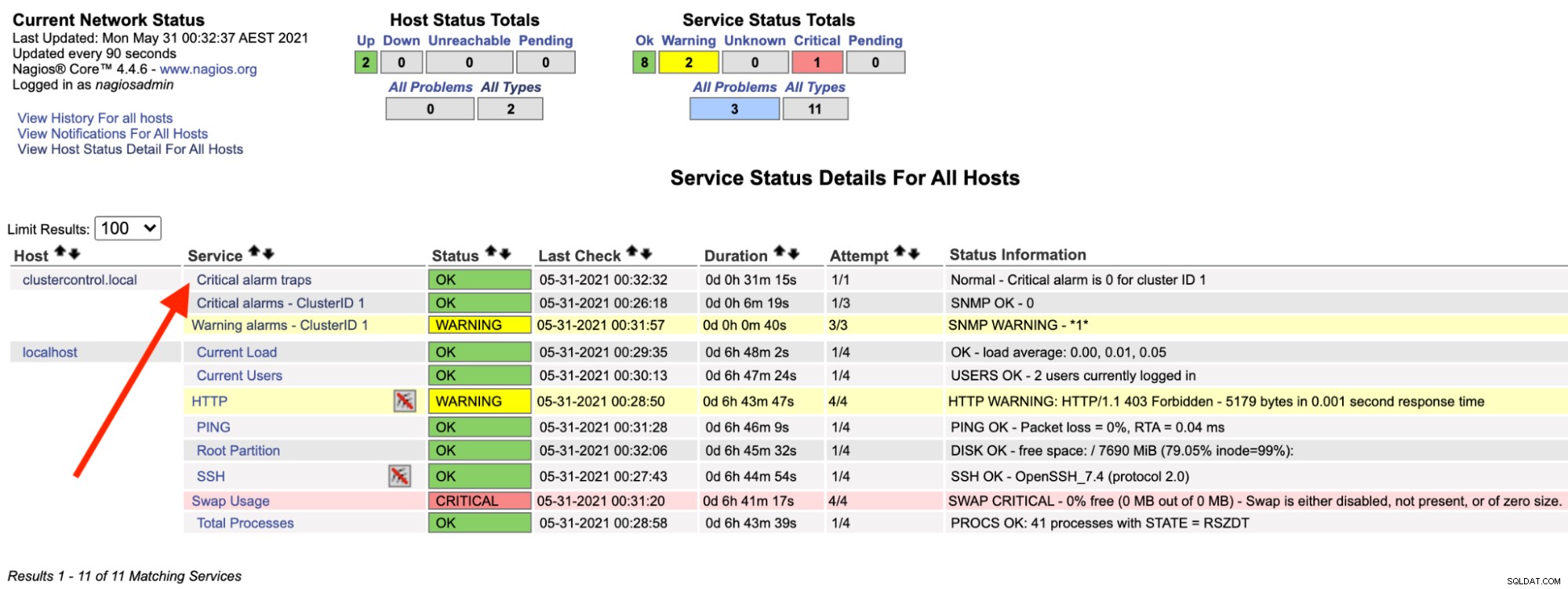
Ovanstående kan automatiseras med ett enkelt bash-skript:
#!/bin/bash
# alarmtrapper.bash - SNMP trapper for ClusterControl alarms
CLUSTER_ID=1
SNMP_MANAGER=192.168.10.11
INTERVAL=10
send_critical_snmp_trap() {
# send critical trap
local val=$1
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.1 .1.3.6.1.4.1.57397.1.1.1.1 i ${val} .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
send_zero_critical_snmp_trap() {
# send OK trap
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.2 .1.3.6.1.4.1.57397.1.1.1.1 i 0 .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
while true; do
count=$(s9s alarm --list --long --cluster-id=${CLUSTER_ID} --batch | grep CRITICAL | wc -l)
[ $count -ne 0 ] && send_critical_snmp_trap $count || send_zero_critical_snmp_trap
sleep $INTERVAL
doneFör att köra skriptet i bakgrunden gör du helt enkelt:
$ bash alarmtrapper.bash &Vid denna tidpunkt bör vi kunna se Nagios "Kritiska larmfällor"-tjänst i aktion om det blir fel i vårt kluster automatiskt.
Sluta tankar
I den här bloggserien har vi visat ett proof-of-concept om hur ClusterControl kan konfigureras för övervakning, generering/bearbetning av fällor och larm med SNMP-protokoll. Detta markerar också början på vår resa för att införliva SNMP i våra framtida utgåvor. Håll utkik eftersom vi kommer att ge fler uppdateringar om denna spännande funktion.