I den här artikeln ska vi bygga en skrapa för en faktisk frilansspelning där klienten vill ha ett Python-program för att skrapa data från Stack Overflow för att fånga nya frågor (frågans titel och URL). Skrapad data ska sedan lagras i MongoDB. Det är värt att notera att Stack Overflow har ett API, som kan användas för att komma åt den exakta samma data. Kunden ville dock ha en skrapa, så en skrapa fick han.
Gratis bonus: Klicka här för att ladda ner ett Python + MongoDB-projektskelett med fullständig källkod som visar hur du kommer åt MongoDB från Python.
Uppdateringar:
- 01/03/2014 - Refaktorerade spindeln. Tack, @kissgyorgy.
- 02/18/2015 - Lade till del 2.
- 09/06/2015 - Uppdaterad till den senaste versionen av Scrapy och PyMongo - heja!
Som alltid, se till att läsa webbplatsens användarvillkor/service och respektera robots.txt fil innan du påbörjar något skrapjobb. Se till att följa etiska skrapningsmetoder genom att inte översvämma webbplatsen med många förfrågningar under en kort tidsperiod. Behandla alla webbplatser du skrapar som om de vore din egen .
Installation
Vi behöver Scrapy-biblioteket (v1.0.3) tillsammans med PyMongo (v3.0.3) för att lagra data i MongoDB. Du måste installera MongoDB också (inte täckt).
Scrapy
Om du kör OSX eller en variant av Linux, installera Scrapy med pip (med din virtualenv aktiverad):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Om du använder en Windows-maskin måste du installera ett antal beroenden manuellt. Se den officiella dokumentationen för detaljerade instruktioner samt den här Youtube-videon som jag skapade.
När Scrapy har konfigurerats, verifiera din installation genom att köra det här kommandot i Python-skalet:
>>>>>> import scrapy
>>>
Om du inte får ett fel är du bra att gå!
PyMongo
Installera sedan PyMongo med pip:
$ pip install pymongo
$ pip freeze > requirements.txt
Nu kan vi börja bygga sökroboten.
Scrapy Project
Låt oss starta ett nytt Scrapy-projekt:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Detta skapar ett antal filer och mappar som innehåller en grundläggande planlösning så att du snabbt kan komma igång:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Ange data
items.py fil används för att definiera lagrings "behållare" för data som vi planerar att skrapa.
StackItem() klass ärver från Item (docs), som i princip har ett antal fördefinierade objekt som Scrapy redan har byggt åt oss:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Låt oss lägga till några föremål som vi faktiskt vill samla in. För varje fråga behöver klienten titel och URL. Så uppdatera items.py som så:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Skapa spindeln
Skapa en fil som heter stack_spider.py i katalogen "spindlar". Det är här magin händer – t.ex. där vi berättar för Scrapy hur man hittar den exakta data vi letar efter. Som du kan föreställa dig är detta specifikt till varje enskild webbsida som du vill skrapa.
Börja med att definiera en klass som ärver från Scrapys Spider och lägg sedan till attribut efter behov:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
De första variablerna är självförklarande (docs):
namedefinierar namnet på spindeln.allowed_domainsinnehåller bas-URL:erna för de tillåtna domänerna för spindeln att genomsöka.start_urlsär en lista över webbadresser som spindeln kan börja krypa från. Alla efterföljande webbadresser börjar från data som spindeln laddar ner från webbadresserna istart_urls.
XPath-väljare
Därefter använder Scrapy XPath-väljare för att extrahera data från en webbplats. Med andra ord kan vi välja vissa delar av HTML-data baserat på en given XPath. Som det står i Scrapys dokumentation, "XPath är ett språk för att välja noder i XML-dokument, som även kan användas med HTML."
Du kan enkelt hitta en specifik Xpath med hjälp av Chromes utvecklarverktyg. Inspektera helt enkelt ett specifikt HTML-element, kopiera XPath och justera sedan (efter behov):
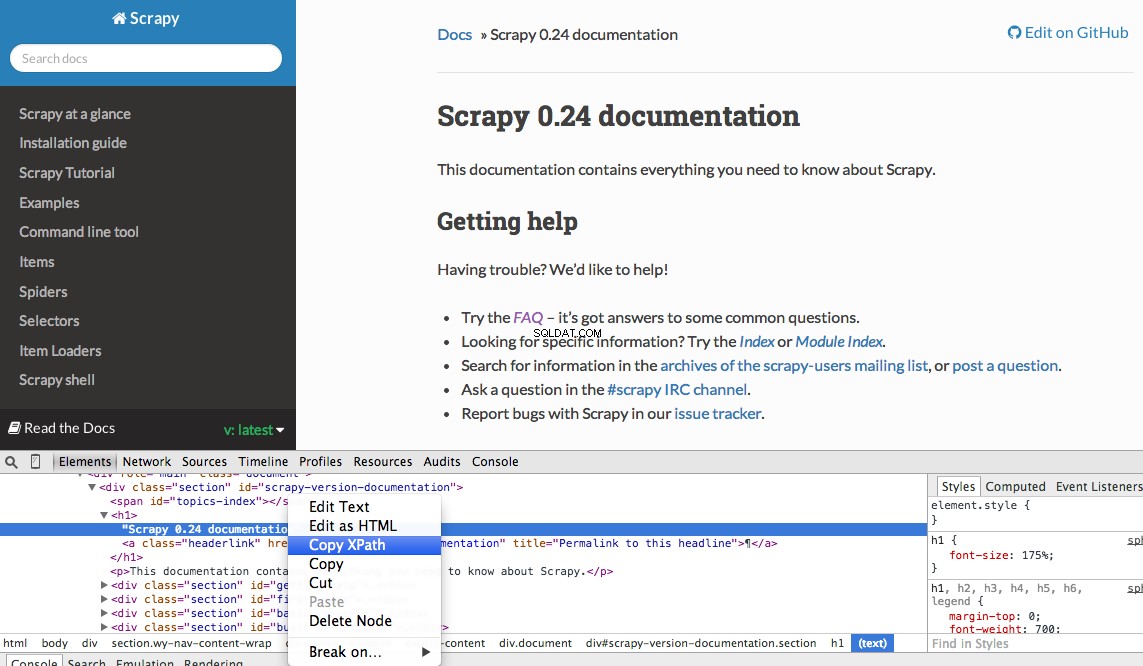
Utvecklarverktyg ger dig också möjlighet att testa XPath-väljare i JavaScript-konsolen genom att använda $x - dvs $x("//img") :
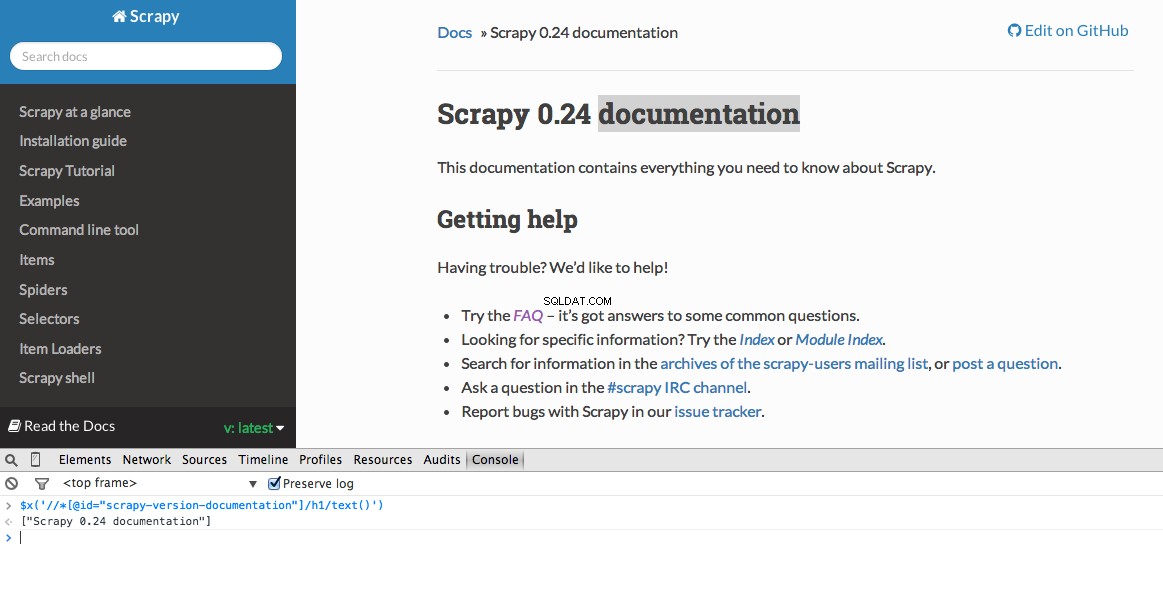
Återigen berättar vi i princip för Scrapy var man ska börja leta efter information baserat på en definierad XPath. Låt oss navigera till Stack Overflow-webbplatsen i Chrome och hitta XPath-väljarna.
Högerklicka på den första frågan och välj "Inspektera element":
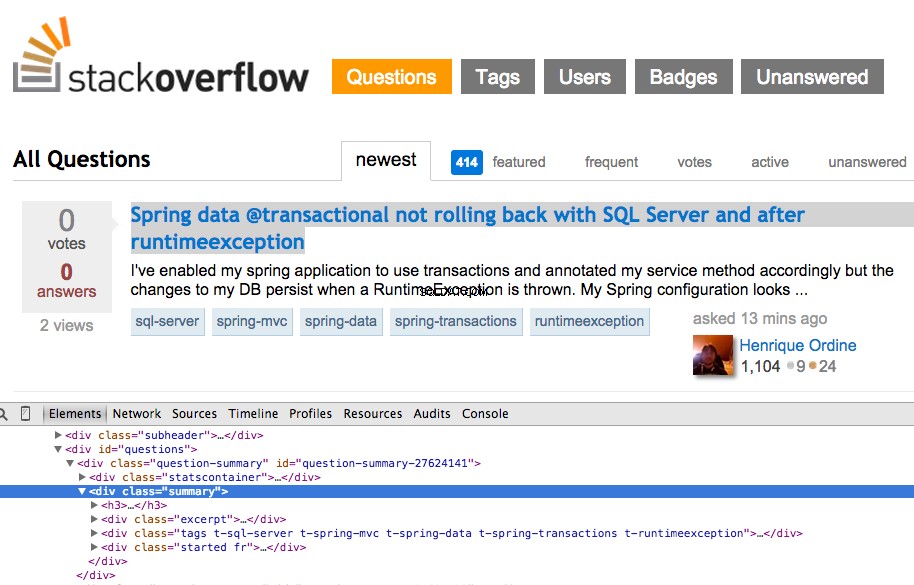
Ta nu XPath för <div class="summary"> , //*[@id="question-summary-27624141"]/div[2] , och testa det sedan i JavaScript-konsolen:
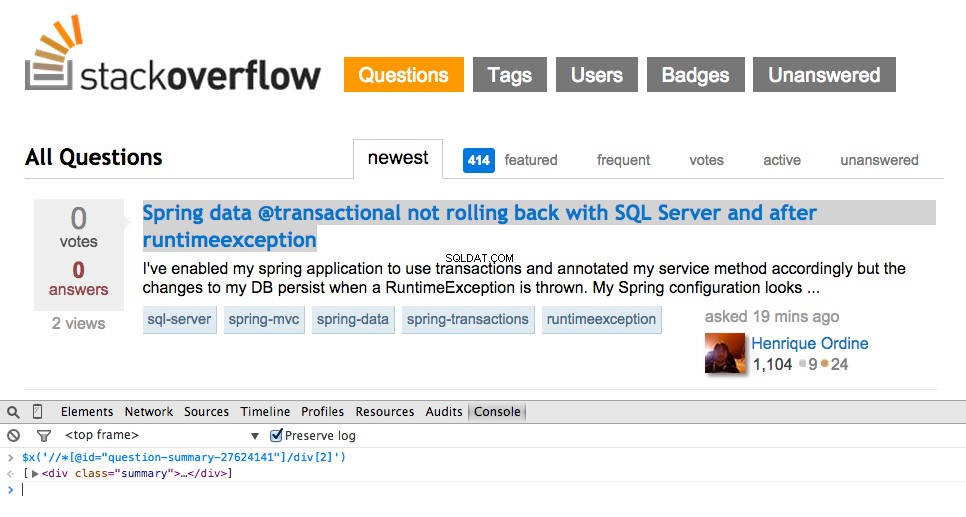
Som du märker väljer den bara den en fråga. Så vi måste ändra XPath för att få tag på alla frågor. Några idéer? Det är enkelt://div[@class="summary"]/h3 . Vad betyder det här? I huvudsak säger denna XPath:Grab all <h3> element som är barn till en <div> som har klassen summary . Testa denna XPath i JavaScript-konsolen.
Lägg märke till hur vi inte använder den faktiska XPath-utgången från Chrome Developer Tools. I de flesta fall är utdata bara en hjälpsam åtskillnad, som i allmänhet pekar dig i rätt riktning för att hitta den fungerande XPath.
Låt oss nu uppdatera stack_spider.py skript:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
Extrahera data
Vi behöver fortfarande analysera och skrapa den data vi vill ha, som faller inom <div class="summary"><h3> . Återigen, uppdatera stack_spider.py som så:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
Tillsammans med Scrapy-stackspårningen bör du se 50 frågetitlar och webbadresser utmatade. Du kan rendera utdata till en JSON-fil med detta lilla kommando:
$ scrapy crawl stack -o items.json -t json
Vi har nu implementerat vår Spider baserat på vår data som vi söker. Nu måste vi lagra skrapad data i MongoDB.
Lagra data i MongoDB
Varje gång en vara returneras vill vi validera data och sedan lägga till den i en Mongo-samling.
Det första steget är att skapa databasen som vi planerar att använda för att spara all vår genomsökta data. Öppna settings.py och ange pipeline och lägg till databasinställningarna:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Pipeline Management
Vi har ställt in vår spindel för att genomsöka och analysera HTML, och vi har ställt in våra databasinställningar. Nu måste vi koppla ihop de två genom en pipeline i pipelines.py .
Anslut till databas
Låt oss först definiera en metod för att faktiskt ansluta till databasen:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
Här skapar vi en klass, MongoDBPipeline() , och vi har en konstruktorfunktion för att initiera klassen genom att definiera Mongo-inställningarna och sedan ansluta till databasen.
Bearbeta data
Därefter måste vi definiera en metod för att bearbeta den analyserade datan:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
Vi upprättar en anslutning till databasen, packar upp informationen och sparar den sedan i databasen. Nu kan vi testa igen!
Testa
Återigen, kör följande kommando i "stack"-katalogen:
$ scrapy crawl stack
OBS :Se till att du har Mongo-demonen -
mongod- körs i ett annat terminalfönster.
Hurra! Vi har framgångsrikt lagrat vår genomsökta data i databasen:
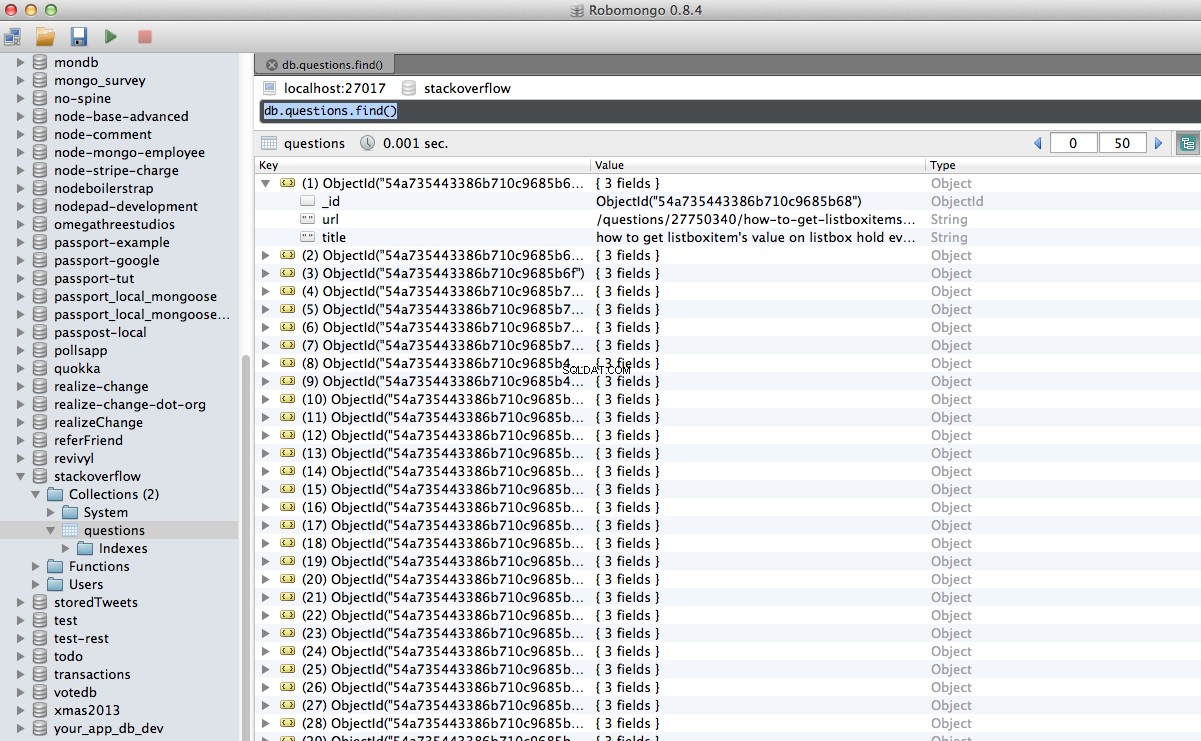
Slutsats
Det här är ett ganska enkelt exempel på att använda Scrapy för att genomsöka och skrapa en webbsida. Själva frilansprojektet krävde att skriptet följde pagineringslänkarna och skrapa varje sida med CrawlSpider (docs), vilket är superlätt att implementera. Försök att implementera detta på egen hand och lämna en kommentar nedan med länken till Github-förvaret för en snabb kodgranskning.
Behövs hjälp? Börja med det här skriptet, som nästan är klart. Se sedan del 2 för hela lösningen!
Gratis bonus: Klicka här för att ladda ner ett Python + MongoDB-projektskelett med fullständig källkod som visar hur du kommer åt MongoDB från Python.
Du kan ladda ner hela källkoden från Github-förvaret. Kommentera nedan med frågor. Tack för att du läser!