Det här blogginlägget kommer att presentera en enkel "hej värld" typ av exempel på hur man får data som lagras i S3 indexerad och serverad av en Apache Solr-tjänst som är värd i ett Data Discovery and Exploration-kluster i CDP. För den nyfikna:DDE är ett förtempleterat Solr-optimerat klusterdistributionsalternativ i CDP, och nyligen släppt i tech preview . Vi kommer endast att täcka AWS- och S3-miljöer i den här bloggen. Azure- och ADLS-distributionsalternativ är också tillgängliga i teknisk förhandsgranskning, men kommer att behandlas i ett framtida blogginlägg.
Vi kommer att skildra det enklaste scenariot för att göra det enkelt att komma igång. Det finns naturligtvis mer avancerade datapipeline-inställningar och fler rika scheman möjliga, men detta är en bra utgångspunkt för en nybörjare.
Antaganden:
- Du har redan ett CDP-konto och har avancerade användare eller administratörsrättigheter för miljön där du planerar att skapa den här tjänsten.
Om du inte har ett CDP AWS-konto, kontakta din favorit Cloudera-representant eller registrera dig för en CDP-provversion här. - Du har miljöer och identiteter mappade och konfigurerade. Mer uttryckligen, allt du behöver är att ha mappningen av CDP-användaren till en AWS-roll som ger åtkomst till den specifika s3-bucket du vill läsa från (och skriva till).
- Du har redan inställt ett lösenord för arbetsbelastning (FreeIPA).
- Du har ett DDE-kluster igång. Du kan också hitta mer information om hur du använder mallar i CDP Data Hub här.
- Du har CLI-åtkomst till det klustret.
- SSH-porten är öppen på AWS som för din IP-adress. Du kan få den offentliga IP-adressen för en av Solr-noderna inom Datahub-klusterdetaljerna. Lär dig här hur du SSH till ett AWS-kluster.
- Du har en loggfil i en S3-bucket som är tillgänglig för din användare (
/sample.log i det här exemplet). Om du inte har en, här är en länk till den vi använde.
Arbetsflöde
Följande avsnitt leder dig genom stegen för att få data indexerad med Crunch Indexer Tool som kommer ur kartongen med DDE.

Skapa en samling för att hålla ditt index
I HUE finns en indexdesigner; Men så länge som DDE är i Tech Preview kommer den att vara under ombyggnad något och rekommenderas inte i nuläget. Men snälla prova det efter att DDE går GA, och låt oss veta vad du tycker.
För närvarande kan du skapa ditt Solr-schema och konfigurationer med CLI-verktyget "solrctl". Skapa en konfiguration som heter 'my-own-logs-config' och en samling som heter 'my-own-logs'. Detta kräver att du har CLI-åtkomst.
1. SSH till någon av arbetarnoderna i ditt kluster.
2. kinit som en användare med behörighet att skapa samlingskonfigurationen:
kinit
3. Se till att miljövariabeln SOLR_ZK_ENSEMBLE är inställd i /etc/solr/conf/solr-env.sh. Spara dess värde eftersom detta kommer att krävas i ytterligare steg.
Tryck på Enter och skriv ditt lösenord för arbetsbelastning (FreeIPA).
Till exempel:
cat /etc/solr/conf/solr-env.sh
Förväntad utdata:
exportera SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Detta ställs automatiskt in på värdar med en Solr Server- eller Gateway-roll i Cloudera Manager.
4. För att generera konfigurationsfiler för samlingen, kör följande kommando:
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate är en av standardmallarna som levereras med Solr i CDP, men eftersom den är en mall är den oföränderlig. För detta arbetsflöde måste du kopiera det och på så sätt skapa ett nytt som är föränderligt (detta är vad alternativet oföränderligt=falskt gör). Detta ger dig en flexibel, schemalös konfiguration. Att skapa ett väldesignat schema är något som är värt att lägga designtid på, men det är inte nödvändigt för utforskande användning. Av denna anledning ligger det utanför ramen för detta blogginlägg. I en verklig produktionsmiljö rekommenderar vi dock starkt att du använder väldesignade scheman – och vi tillhandahåller gärna experthjälp om det behövs!
5. Skapa en ny samling med följande kommando:
solrctl collection --skapa mina egna loggar -s 1 -c my-own-logs-config
Detta skapar samlingen "my-own-logs" baserat på "my-own-logs-config"-samlingskonfigurationen på en shard.
6. För att validera att samlingen har skapats kan du navigera till Solr Admin UI. Samlingen för "mina-egna-loggar" kommer att vara tillgänglig via rullgardinsmenyn till vänster.

Indexera dina data
Här beskriver vi med ett enkelt exempel hur man konfigurerar och kör det inbyggda Crunch Indexer Tool för att snabbt indexera data i S3 och tjäna genom Solr i DDE. Eftersom säkrandet av klustret kan använda CM Auto TLS, Knox, Kerberos och Ranger, kan "Spark submit" vara beroende av aspekter som inte tas upp i det här inlägget.
Att indexera data från S3 är precis detsamma som att indexera från HDFS.
Utför dessa steg på Yarn worker-noden (kallad "Yarnworker" på Management Console webUI).
1. SSH till den dedikerade Yarn-arbetarnoden i DDE-klustret som en Solr-adminanvändare.
För att ta reda på IP-adressen för Yarn-arbetarnoden, klicka på Hårdvara fliken på klustrets informationssida och rulla sedan till noden "Yarnworker".

2. Gå till din resurskatalog (eller skapa en om du inte redan har den:
cd
Använd administratörsanvändarens hemmapp som resurskatalog (
3. Ändra din användare:
kinit
Tryck på Enter och skriv ditt lösenord för arbetsbelastning (FreeIPA).
4. Kör följande curl-kommando och ersätt
curl --negotiate -u:"https://: /solr/admin?op=GETDELEGATIONTOKEN" --insecure> tokenFile.txt
5. Skapa en Morphline-konfigurationsfil för Crunch Indexer Tool, read-log-morphline.conf i det här exemplet. Ersätt
SOLR_LOCATOR :{ # Namn på solr-samlingens samling :my-own-logs #zk ensemble zkHost :
Denna Morphline läser stackspåren från den givna loggfilen, skriver sedan en felsökningslogg och laddar den till den angivna Solr.
6. Skapa en log4j.properties-fil för loggkonfiguration:
log4j.rootLogger=INFO, A1# A1 är inställd på att vara en ConsoleAppender.log4j.appender.A1=org.apache.log4j.ConsoleAppender# A1 använder PatternLayout.log4j.appender.A1.layout=org.apache.log4j .PatternLayoutlog4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Kontrollera om filen som du vill läsa finns på S3 (om du inte har en, här är en länk till den vi använde för detta enkla exempel:
aws s3 ls s3://
8. Kör kommandot spark-submit:
Ersätt platshållare i och med de värden du har ställt in.
exportera myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunchexport myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunchexport myDriverJar=$(hitta $myDriverJarDir maxdepth 1 -name 'search-crunch-*.jar' ! -name '*-job.jar' ! -name '*-sources.jar')export myDependencyJarFiles=$(hitta $myDependencyJarDir -name '*.jar' | sort | tr '\n' ',' | head -c -1)export myDependencyJarPaths=$(hitta $myDependencyJarDir -name '*.jar' | sort | tr '\n' ':' | head -c -1) export myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ "export myResourcesDir="
Om du stöter på ett liknande meddelande kan du bortse från det:
WARN metadata.Hive:Det gick inte att registrera alla functions.org.apache.hadoop.hive.ql.metadata.HiveException:org.apache.thrift.transport.TTransportException
9. För att övervaka exekveringen av kommandot, gå till Resurshanteraren.

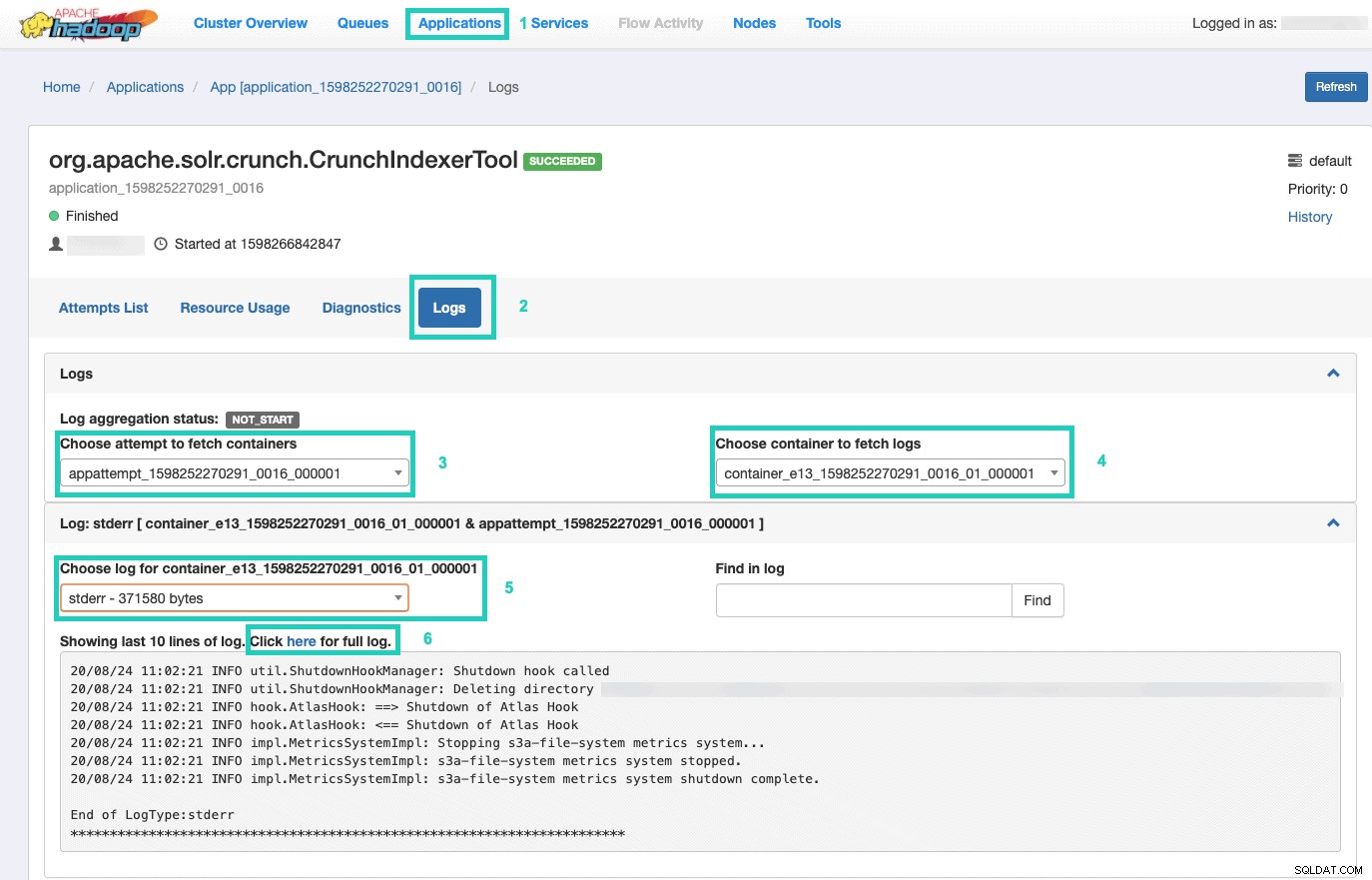
Väl där väljer du Applikationer fliken > Klicka på Applikations-ID av det programförsök du vill övervaka > Välj Loggar> Välj försök att hämta behållare> Välj behållare för att hämta loggar> Välj logg för behållare> Välj stderr log> Klicka på Klicka här för fullständig logg .
Visa ditt index
Du har många alternativ för hur du ska visa sökbara indexerade data till slutanvändare. Du kan bygga din egen rika applikation baserad på Solrs rika API:er (mycket vanligt). Du kan ansluta ditt favoritverktyg från tredje part, såsom Qlik, Tableau etc, över deras certifierade Solr-anslutningar. Du kan använda Hues enkla solr-instrumentpanel för att bygga prototypapplikationer.
För att göra det senare:
1. Gå till Hue.

2. I instrumentpanelsvyn, navigera till den valda indexfilen (t.ex. den du just skapade).
3. Börja dra och släppa olika instrumentpanelelement och välj fälten från indexet för att fylla i data för det visuella objektet.
En snabb instruktionsvideo från det förflutna finns här för inspiration.
Vi kommer att lämna en djupare dykning för ett framtida blogginlägg.
Sammanfattning
Vi hoppas att du har lärt dig mycket av det här blogginlägget om hur du får data i S3 indexerad av Solr i en DDE med Crunch Indexer Tool. Naturligtvis finns det många andra sätt (Spark i Data Engineering-upplevelsen, Nifi i Data Flow-upplevelsen, Kafka i Stream Management-upplevelsen och så vidare), men de kommer att behandlas i framtida blogginlägg. Vi hoppas att du är mycket framgångsrik i din fortsatta resa med att bygga kraftfulla insiktsapplikationer som involverar text och annan ostrukturerad data. Om du bestämmer dig för att testa DDE i CDP, vänligen berätta hur det gick!