När det gäller att analysera minnesanvändningen för en Redis-instans, finns det massor av gratis och öppen källkodsverktyg på marknaden, tillsammans med en hel del betalda produkter. Några av de mest populära är Jacks (av alla branscher berömmelse), men om du letar efter en djupare analys av dina minnesproblem, kanske du har det bättre med ett av de mer riktade och mindre kända verktygen.
I det här inlägget har vi sammanställt en lista över de sex bästa gratisverktygen som vi tyckte var mest användbara för att analysera minnesanvändning för våra Redis-instanser:
- Redis Memory Analyzer (RMA)
- Redis Sampler
- RDB-verktyg
- Redis-Audit
- Redis Toolkit
- Skörda
1) Redis Memory Analyzer

Redis Memory Analyzer (RMA) är en av de mest omfattande FOSS-minnesanalysatorerna som finns tillgängliga för Redis. Den stöder tre olika detaljnivåer:
- Global – Översikt över minnesanvändningsinformation.
- Skanner – Minnesanvändningsinformation på högsta nivå på tangentrymd/prefixnivå – med andra ord, det kortaste vanliga prefixet används.
- RAM – Tangentrymd/prefix på lägsta nivå – med andra ord, det längsta vanliga prefixet används.
Varje läge har sina egna användningsområden - du kan få mer information i RMA ReadMe.

RMA – Globalt läge
I det globala läget tillhandahåller RMA en del statistik på hög nivå, som antalet nycklar, systemminne, storlek på inbyggd uppsättning, storlek på tangentutrymme, etc. En unik funktion är " keyspace overhead” vilket är minnet som används av Redis-systemet för att lagra nyckelrymdsrelaterad information, som pekare för listdatastrukturerna.
RMA – skannerläge

I skannerläget får vi en överblick över vårt tangentutrymme. Det ger namnrymden på hög nivå (så a:b:1 och a:c:1 klubbas ihop som en:*), tillsammans med typerna av dess objekt och procentandelen minne som förbrukas av namnutrymmet. Det är användbart att börja med denna information och sedan använda "RAM"-beteendet tillsammans med namnutrymmesmönstret för att göra en detaljerad analys.
RMA – RAM-läge
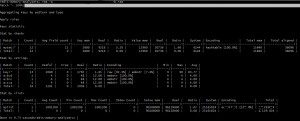
I RAM-läget får vi minnesförbrukning på nyckelrymdsnivå, vilket tillhandahålls av de flesta andra FOSS-minnesanalysatorer. Så här tas a:b:1 och a:c:1 separat som a:b:* och a:c:* och vi får detaljerad information om använt minne, faktisk datastorlek, overhead, kodning, min och max TTL , etc. Detta hjälper till att lokalisera de största minnesproblemen i vårt system.
Tyvärr är det här verktyget inte alltid uppdaterat (den senaste commit på GitHub är mer än ett år sedan). Trots det är detta en av de bästa vi hittade för detaljerad analys.
RMA-installation och användning:
RMA kräver att Python och PIP är installerade på systemet (båda är tillgängliga för alla större operativsystem). När de väl är installerade kan du köra ett enda kommando för att installera RDB-verktygen – `pip install rma`
Det är ganska enkelt att använda från kommandoraden. Syntaxen är `rma [-s HOST] [-p PORT] [-a LÖSENORD] [-d DB] [-m mönster-att-matcha] [-l antal-nycklar-att-skanna] [-b BEHAVIOUR] [-t kommaseparerad-lista-över-data-typer-att-skanna]`
RMA-proffs:
- Fungerar i realtid.
- Använder scan-kommandot för att gå igenom databasen, därför är prestandapåverkan begränsad och analysen är mycket exakt.
- Väldokumenterad – det är lätt att hitta användningsexempel.
- Stöder robusta anpassnings- och filtreringsalternativ, inklusive att endast analysera specifika datatyper, eller bara ta hänsyn till nycklar som matchar ett specifikt mönster).
- Kan ge detaljer på olika nivåer – namnrymder, nycklar eller globala värden.
- Unikt bland alla verktyg vi granskade genom att det visar datastrukturens overhead (det vill säga hur mycket minne som används för att lagra intern Redis-information som pekarna för en listdatatyp ).
RMA-nackdelar:
- Stöder inte probabilistiskt urval. Linjär scanning av databasen kan vara mycket långsam för stora databaser; det finns möjlighet att stoppa skanningen när ett visst antal nycklar har returnerats för att förbättra prestandan.
- Det finns många detaljer i utdata; även om det är användbart för experter, kan det bara tjäna till att förvirra nybörjare.
2) Redis Sampler

Redis Sampler är ett mycket kraftfullt verktyg som kan ge djupa insikter om minnesanvändningen i en Redis-instans. Det underhålls av antirez, utvecklaren bakom Redis, och den djupa kunskapen om Redis visar sig i det här verktyget. Verktyget uppdateras inte särskilt ofta – men det har inte rapporterats många problem ändå.

Redis Sampler gör en probabilistisk genomsökning av databasen och rapporterar följande information:
- Den procentuella fördelningen av nycklar mellan olika datatyper – baserat på antalet nycklar, snarare än storleken på objekt.
- De största nycklarna av typen sträng, baserat på strlen, och procentandelen minne de förbrukar.
- För alla andra datatyper beräknas de största nycklarna och visas som två separata listor:en baserad på objektets storlek och en annan baserad på antalet objekt i objekt.
- För varje datatyp visar den också en "Power of 2-distribution". Detta är verkligen användbart för att förstå storleksfördelningen inom en datatyp. Utdata visar i princip hur stor procentandel av nycklar av en given typ som har storleken i intervallet> 2^x och <=2^x+1.
Installation och användning av Redis Sampler:
Detta är ett enda Ruby-skript. Det kräver att Ruby redan är installerad. Du behöver också 'rubygems' och 'redis' ädelstenar för att installeras. Användningen är ganska enkel – från kommandoraden, kör `./redis-sampler.rb `
Proffs för Redis Sampler:
- Mycket enkel att använda – inga alternativ att undersöka och förstå.
- Resultatet är lätt att förstå, även för nybörjare, men har tillräckligt med information för mycket detaljerade analyser av en Redis-instans av experter. Avsnitten är tydligt avgränsade och lätta att filtrera bort.
- Fungerar på alla Redis-versioner.
- Använder inga privilegierade kommandon som DEBUG OBJECT, så det kan användas på alla system, inklusive Amazons ElastiCache.
- Den använder datatypspecifika längdkommandon för att identifiera datastorlek, så den rapporterade användningen påverkas inte av serialisering.
- Fungerar med livedata. Även om rekommendationen är att köra på loopback-gränssnitt, stöder det sampling av fjärrsystem.
Redis Sampler Nackdelar:
- Om provstorleken är högre än databaskardinalitet kommer den fortfarande att använda RANDOMKEYS istället för SCAN.
- Ingen paket- eller Docker-bild tillgänglig. Du måste installera beroenden manuellt (men på den ljusa sidan finns det bara två beroenden).
- Rapporterar datastorleken, som inte exakt matchar utrymmet som tas upp på RAM-minnet på grund av lagringskostnader för datastruktur.
- Fungerar inte direkt om din Redis-instans kräver autentisering. Du måste ändra skriptet för att ta ett lösenord; i enklaste form kan du söka efter:
redis =Redis.new(:host => ARGV[0], :port => ARGV[1].to_i, :db => ARGV[2].to_i)
och ändra det till:
redis =Redis.new(:host => ARGV[0], :port => ARGV[1].to_i, :db => ARGV[2].to_i, :lösenord => “lägg till-ditt-lösenord-här”)
3) RDB-verktyg

RDB Tools är en mycket användbar uppsättning verktyg för alla seriösa Redis-administratörer. Det finns ett verktyg för nästan alla användningsfall vi kan tänka oss, men i det här inlägget kommer vi enbart att koncentrera oss på minnesanalysverktyget.
Även om det inte är i närheten av så omfattande som RMA eller Redis Sampler, ger RDB Tools 3 viktig information:

1) Alla nycklar där värdet har (serialiserat) storlek större än B byte [B specificeras av användare].

2) De största N-tangenterna [N specificeras av användaren].

3) Storleken på en viss nyckel:den läses live från databasen.
Denna svit har många aktiva bidragsgivare på GitHub och uppdateras ganska ofta. RDB Tools är också väldokumenterat på internet. Underhållaren sripathikrishnan är välkänd i Redis-gemenskapen för de många verktyg han har tillhandahållit genom åren.
RDB-verktyg Installation och användning:
RDB-verktyg kräver att Python och PIP är installerade på systemet (båda är tillgängliga för alla större operativsystem). När de väl är installerade kan du köra ett enda kommando för att installera RDB-verktygen – `pip install rdbtools python-lz`
Användningen är ganska enkel:
- För att få 200 största nycklar:rdb -c memory /var/redis/6379/dump.rdb –largest 200 -f memory.csv
- För att få alla nycklar större än 128 byte:rdb -c memory /var/redis/6379/dump.rdb –bytes 128 -f memory.csv
- För att få storleken på en nyckel:redis-memory-for-key -s localhost -p 6379 -a mypassword person:1
Proffs för RDB-verktyg:
- Matar ut en CSV-fil, som kan användas med andra FOSS-verktyg för att enkelt skapa datavisualiseringar, och kan även importeras till RDBMS-er för att köra analyser.
- Mycket väldokumenterad.
- Stöder anpassnings- och filtreringsalternativ, så att du kan få mer användbara rapporter.
RDB Tools Nackdelar:
- Deras analys fungerar inte på livedata; du måste ta en RDB-dump. Som ett resultat av detta är den rapporterade minnesanvändningen det serialiserade minnet, vilket inte är exakt detsamma som minnet som upptas på RAM.
- Den har inget inbyggt stöd för gruppering, så det kan inte hitta de största namnrymden.
4) Redis-Audit

Redis-Audit är ett probabilistiskt verktyg som är användbart för att få en snabb överblick över din minnesanvändning. Den matar ut användbar information om nyckelgrupper, som total minnesförbrukning, maximal TTL i gruppen, genomsnittlig senaste åtkomsttid, procentandelen nycklar i gruppen som löper ut, etc. Detta är det perfekta verktyget om du behöver hitta mest minne- hogging nyckelgrupp i din applikation.

Redis-Audit Installation och användning:
Du måste ha Ruby och Bundle redan installerade. När det väl är installerat kan du antingen klona Redis-Audit-förrådet till en mapp eller ladda ner zip-filen och packa upp den till en mapp. Kör `bundle install` från den mappen för att slutföra installationen.
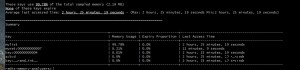
Användningen är ganska enkel:från kommandoraden, kör ` redis-audit.rb värdnamn [port] [lösenord] [dbnum] [sample_size]`

Redis-Audit-proffs:
- Låter dig definiera ditt eget regex för gruppering av tangentsteg/prefix.
- Fungerar på alla Redis-versioner.
- Om provstorleken är större än det faktiska antalet nycklar går den igenom alla nycklar. Å andra sidan använder den här operationen nycklar * istället för att skanna – eventuellt blockerar andra operationer.
Redis-Audit Nackdelar:
- Använder kommandot DEBUG OBJECT (inte tillgängligt i ElastiCache); som ett resultat rapporterar den om serialiserad storlek – som skiljer sig från den faktiska storleken som upptas på RAM.
- Utdata är inte särskilt lätt att analysera snabbt, eftersom det inte är tabellformat.
5) Redis Toolkit

Redis Toolkit är en nakna övervakningslösning som kan användas för att analysera två nyckelmått:träfffrekvens och minnesförbrukning. Projektet uppdateras med jämna mellanrum för buggfixar men har inte communitystödet som några av de mer kända verktygen har.
Installation och användning av Redis Toolkit:

Du måste ha Docker installerat på ditt system. Klona sedan GitHub-förvaret (eller ladda ner som zip och packa upp till en mapp). Från den mappen är installationen lika enkel som att köra `./redis-toolkit install`.
Användningen sker enbart via kommandoraden, genom en rad enkla kommandon.
- För att börja övervaka träfffrekvens:./redis-toolkit monitor
- Så här rapporterar du träfffrekvens:./redis-toolkit report -name NAME -type hitrate
- För att sluta övervaka träfffrekvensen:./redis-toolkit stop
- Så här skapar du dumpfilen på det lokala systemet:./redis-toolkit dump
- Så här rapporterar du minnesanvändning:./redis-toolkit rapport -typ minne -namn NAMN
Redis Toolkit-proffs:
- Lätt att förstå gränssnitt som ger dig exakt den information du behöver.
- Kan gruppera prefix till vilken nivå som helst som är användbar för dig (så om du väljer a:b:1 och a:c:1, räknas de som a:* eller separat) .
- Fungerar på alla Redis-versioner; kräver inte åtkomst till privilegierade kommandon som DEBUG OBJECT.
- Väl dokumenterad.
Redis Toolkit Nackdelar:
- Minnesanalysen är inte aktiv; eftersom det fungerar på den serialiserade dumpen kommer den rapporterade minnesanvändningen inte att vara lika med den faktiska RAM-förbrukningen.
- En dump måste skapas på datorn där Redis Toolkit körs. Om du har en fjärransluten Redis-instans kan detta ta ett tag.
- Övervakning av träfffrekvensen använder kommandot MONITOR för att fånga alla kommandon som har körts på servern. Detta kan försämra prestandan och är en möjlig säkerhetsrisk i produktionen.
- Träfffrekvensen beräknas som |GET| / (|GET| + |SET|). Så om ett värde ändras ofta, kommer dess träfffrekvens att vara lägre, även om det aldrig har skett en faktisk cachemiss.
6) Skörd

Detta är ett probabilistiskt samplingsverktyg som kan användas för att identifiera de 10 största namnrymden/prefixen, vad gäller antalet nycklar. Det är ett av de senaste verktygen och har inte sett mycket dragkraft på GitHub. Men om du är en Redis-novis som vill identifiera vilken typ av applikationsdata som täpper till din instans, kan du inte få något enklare än Harvest.
Installation och användning av skörd:
Detta är nedladdningsbart som en Docker-bild. När bilden är klar kan du köra verktyget med kommandot 'docker run –link redis:redis -it –rm 31z4/harvest redis://redis-URL' från CLI.
Skördefördelar:
- Fungerar med livedata.
- Använder kommandot "minnesanvändning" för att få information om storlek; därav:
- Ger korrekt storleksinformation (snarare än serialiserad storlek).
- Kräver inte åtkomst till kommandot DEBUG OBJECT.
- Dina namnområden behöver inte vara:(kolon) avgränsade. Harvest identifierar vanliga prefix, snarare än beroende på regex-baserad namnområdesigenkänning.
Skördenackdelar:
- Det är en etttricksponny – svårt att anpassa den för alla andra användningsfall.
- Verktyget fungerar endast med Redis v4.0 och senare.
- Minimal dokumentation.
Begränsningar för kostnadsfria verktyg
Medan vi tyckte att dessa verktyg var mycket användbara för att felsöka minnesproblem i våra Redis-instanser, bör du vara medveten om begränsningarna med dessa gratisverktyg.
De betalda verktygen har nästan alltid någon form av datavisualisering, som inte är tillgänglig direkt med något av verktygen vi granskade. Det bästa du får är en CSV-utdata som du kan använda andra FOSS-verktyg för att visualisera, och många verktyg har inte ens det alternativet. Det ger en brant inlärningskurva, särskilt för nybörjare Redis-användare. Om du sannolikt kommer att göra minnesanalys ofta kan det vara värt att titta på betalverktyg som ger bra visualisering.
En annan begränsning är möjligheten att lagra historisk information. I enlighet med den allmänna *nix-filosofin att tillverka små verktyg som bara gör en sak, men som gör det bra, vågar verktygen sällan in i övervakningsutrymmet. Inte ens ett minnesförbrukningsdiagram över tid, och många kan inte ens analysera livedata.
Slutet
Ett enda verktyg kommer förmodligen inte att räcka för alla dina behov, men de är ganska bra vapen att ha i din arsenal, parat med övervakningsmöjligheterna tillhandahålls av DBaaS-lösningar som ScaleGrids hosting för Redis™*! Om du vill veta mer om de fantastiska verktygen som finns tillgängliga med våra helt hanterade värdtjänster för Redis™, kolla in vår ScaleGrid-funktioner för Redis™ efter plan.
