Detta är den skrivna versionen av min nya YouTube-video ✍️ 🙂
I den här Redis-handledningen kommer du att lära dig om Redis och hur Redis kan användas som en primär databas för komplexa applikationer som behöver lagra data i flera format.
Översikt 📝
- Vad Redis är och dess användningsområden samt varför den är lämplig för moderna komplexa mikrotjänsttillämpningar?
- Hur Redis stöder lagring av flera dataformat för olika ändamål genom sina moduler ?
- Hur Redis som en minnesdatabas kan bevara data och återhämta sig från dataförlust ?
- Hur du skalar och replikerar Redis ?
- Äntligen eftersom en av de mest populära plattformarna för att köra mikrotjänster är Kubernetes och eftersom det är lite utmanande att köra stateful applikationer i Kubernetes, kommer vi att se hur du enkelt kan köra Redis i Kubernetes
Vad är Redis?
Redis står för re mote dic ordbok s erver
Redis är en minnesdatabas . Så många människor har använt det som en cache ovanpå andra databaser för att förbättra applikationens prestanda. 🤓
Men vad många inte vet är att Redis är en fullfjädrad primär databas som kan användas för att lagra och bevara flera dataformat för komplexa applikationer. 😎
Så låt oss se användningsfallen för det.
Varför Multi-Model Database?
Låt oss titta på en vanlig installation för en mikrotjänstapplikation.
Låt oss säga att vi har en komplex social medieapplikation med miljontals användare. För detta kan vi behöva lagra olika dataformat i olika databaser:
- Relationsdatabas , som Mysql, för att lagra vår data
- ElasticSearch för snabb sökning och filtrering
- Grafdatabas för att representera användarnas anslutningar
- Dokumentdatabas , som MongoDB för att lagra mediainnehåll som delas av våra användare dagligen
- Cachetjänst för bättre prestanda för applikationen
Det är uppenbart att detta är en ganska komplicerad installation.
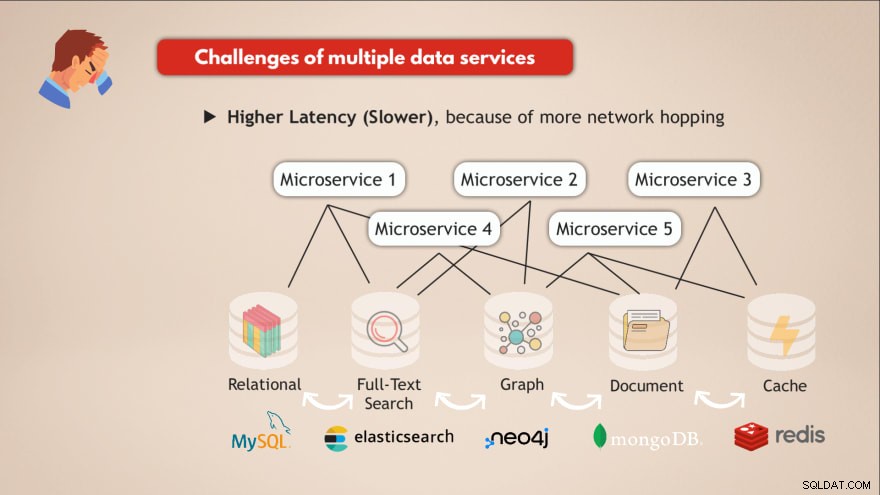
Utmaningar med att ha flera datatjänster
- ❌ Varje datatjänst måste distribueras och underhållas
- ❌ Know-How behövs för varje datatjänst
- ❌ Olika krav på skalning och infrastruktur
- ❌ Mer komplex applikationskod för att interagera med alla dessa olika DB:er
- ❌ Högre latens (långsammare), på grund av mer nätverkshoppning
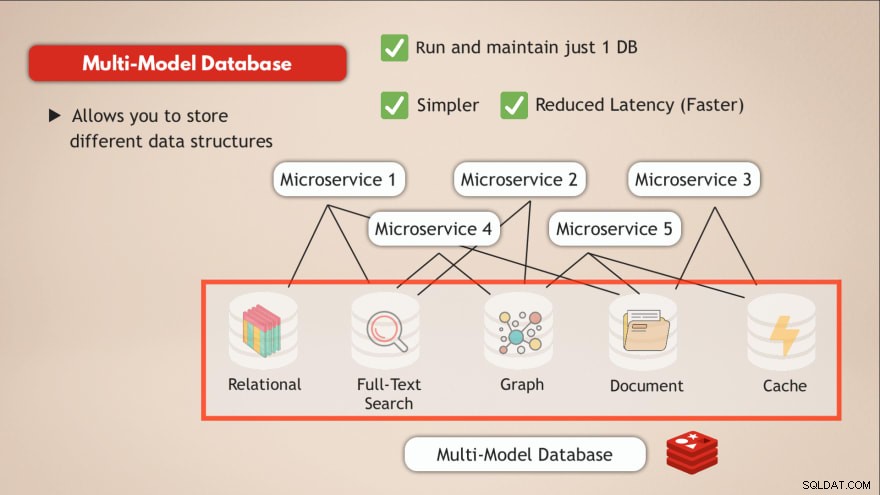
Att ha en databas med flera modeller
I jämförelse med en multimodelldatabas löser du de flesta av dessa utmaningar. Först och främst kör och underhåller du bara en datatjänst . Så din applikation behöver också prata med ett enda datalager och det kräver bara ett programmatiskt gränssnitt för den datatjänsten.
Dessutom kommer latensen att minska genom att gå till en enda dataändpunkt och eliminera flera interna nätverkshubbar.
Så att ha en databas, som Redis, som låter dig lagra olika typer av data eller i princip gör att du kan ha flera typer av databaser i en samt fungera som en cache löser sådana utmaningar.
- ✅ Kör och underhåll bara en databas
- ✅ Enklare
- ✅ Reducerad latens (snabbare)
Hur fungerar Redis?
Redis-moduler 📦
Sättet det fungerar på är att du har Redis Core, som är ett nyckelvärde som redan stöder lagring av flera typer av data och sedan kan du utöka den kärnan med vad som kallas moduler för olika datatyper , som din applikation behöver för olika ändamål. Så till exempel RediSearch för sökfunktioner som ElasticSearch eller Redis Graph för grafdatalagring och så vidare:

Och en bra sak med detta är att det är modulärt . Så dessa olika typer av databasfunktioner är inte tätt integrerade i en databas, utan du kan välja och vraka exakt vilken datatjänstfunktionalitet du behöver för din applikation och sedan i princip lägga till den modulen.
Out-of-the-box cache ⚡️
Naturligtvis när du använder Redis som en primär databas behöver du inte en extra cache, eftersom du har det automatiskt ur lådan med Redis. Det betyder återigen mindre komplexitet i din applikation, eftersom du inte behöver implementera logiken för att hantera fyllning och ogiltigförklaring av cache.
Redis är snabb 🚀
Som en databas i minnet (data lagras i RAM) är Redis supersnabb och prestanda, vilket naturligtvis gör själva applikationen snabbare.
Men vid det här laget kanske du undrar:
Hur kan en databas i minnet bevara data? 🤔
Hur Redis kan bevara data och återställa från dataförlust? 🧐
Om Redis-processen eller servern som Redis körs på misslyckas, är all data i minnet borta eller hur? Så hur bevaras data och i princip hur kan jag vara säker på att min data är säker? 👀
Replikerar Redis?
Tja, det enklaste sättet att säkerhetskopiera data är genom att replikera Redis . Så om Redis master-instansen går ner kommer replikerna fortfarande att köras och har all data. Så om du har en replikerad Redis kommer replikerna att ha data.
Men om alla Redis-instanser går ner kommer du naturligtvis att förlora data, eftersom det inte kommer att finnas någon replik kvar. 🤯Så vi behöver verklig uthållighet .
Snapshotting &AOF
Redis har flera mekanismer för att bevara data och hålla data säker.
Ögonblicksbilder
Den första:ögonblicksbilderna, som du kan konfigurera baserat på tid, antal förfrågningar etc. Så ögonblicksbilder av dina data kommer att lagras på en disk , som du kan använda för att återställa din data om hela Redis-databasen är borta.
Men observera att du kommer att förlora de sista minuterna av data , eftersom du vanligtvis gör ögonblicksbilder var femte minut eller en timme beroende på dina behov. 😐
AOF
Så som ett alternativ använder Redis något som kallas AOF , som står för A ppend O endast F ile.
I det här fallet sparas varje ändring på disken för beständighet kontinuerligt . Och när Redis startas om eller efter ett avbrott, kommer Redis att spela upp loggarna för endast Lägg till fil igen för att återuppbygga tillståndet.
Så AOF är mer hållbart , men kan vara långsammare än att ta ögonblicksbilder.
Bästa alternativet 💡 :Använd en kombination av både AOF och ögonblicksbilder, där AOF behåller data från minne till disk kontinuerligt plus att du har vanliga ögonblicksbilder emellan för att spara datatillståndet ifall du behöver återställa det:

Hur skalar man en Redis-databas?
Låt oss säga att min 1 Redis-instans får slut på minne, så data blir för stor för att lagra i minnet eller så blir Redis en flaskhals och kan inte hantera fler förfrågningar. Hur ökar jag i så fall kapaciteten och minnesstorleken för min Redis-databas? 🤔
Vi har flera alternativ för det:
1. Klustring
Först och främst stöder Redis klustring . Det betyder att du kan ha en primär eller master Redis-instans, som kan användas för att läsa och skriva data och att du kan ha flera repliker av den primära instansen för att läsa data :
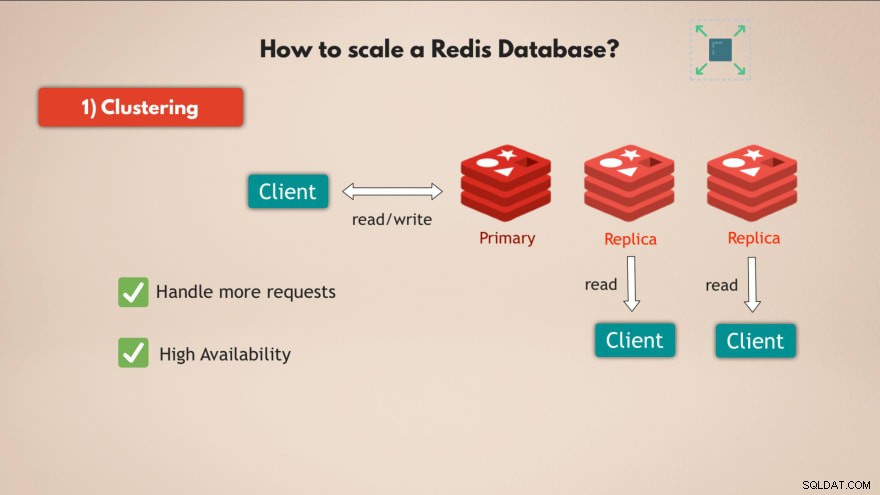
På så sätt kan du skala Redis för att hantera fler förfrågningar och dessutom öka den höga tillgängligheten av din databas, för om master misslyckas kan 1 av replikerna ta över och din Redis-databas kan i princip fortsätta fungera utan problem.
2. Sharding
Det verkar bra nog, men tänk om
- din datauppsättning blir för stor för att få plats i ett minne på en enda server .
- Dessutom har vi skalat läsningarna i databasen, så alla förfrågningar som i princip bara frågar efter data. Men vår masterinstans är fortfarande ensam och måste fortfarande hantera alla skrivningar .
Så vad är lösningen här? 🤔
För det använder vi konceptet sharding , som är ett allmänt begrepp i databaser och som Redis också stödjer.
Så skärning betyder i grunden att du tar din fullständiga datamängd och delar upp den i mindre bitar eller delmängder av data , där varje skärva är ansvarig för sin egen delmängd av data.
Så det betyder att istället för att ha en huvudinstans som hanterar alla skrivningar till hela datamängden, kan du dela upp den i t.ex. fyra skärvor, var och en av dem ansvarar för läsning och skrivning till en delmängd av datan . 💡
Och varje skärva behöver också mindre minneskapacitet , eftersom de bara har en fjärdedel av datan. Detta innebär att du kan distribuera och köra skärvor på mindre noder och i princip skala ditt kluster horisontellt:
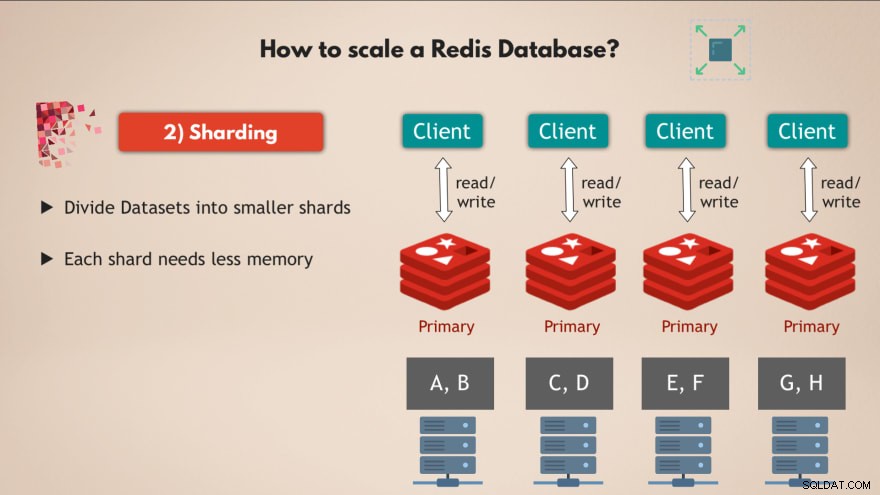
Så att ha flera noder , som kör flera repliker av Redis som är alla klippta ger dig en mycket presterande högt tillgänglig Redis-databas som kan hantera mycket fler förfrågningar utan att skapa några flaskhalsar 👍
Fler ämnen...
Kolla in min video nedan för de två senaste ämnena och scenarierna:
- Appar som behöver ännu högre tillgänglighet och prestanda över flera geografiska platser
- Den nya standarden för att köra mikrotjänster är Kubernetes-plattformen, så kör Redis i Kubernetes är ett mycket intressant och vanligt användningsfall
Hela videon finns här:🤓
Hoppas detta var till hjälp och intressant för några av er! 😊
Gilla, dela och följ mig 😍 för mer innehåll:
- Instagram – Lägger upp många saker bakom scenen
- Privat FB-grupp