Introduktion
Ganska nu kan dina matchningsvillkor vara för breda. Däremot kan du använda levenshtein avstånd för att kontrollera dina ord. Det kanske inte är så lätt att uppfylla alla önskade mål med den, som ljudlikhet. Därför föreslår jag att du delar upp ditt problem i några andra problem.
Du kan till exempel skapa en anpassad checker som använder skickad anropsbar indata som tar två strängar och sedan svara på frågan om är de samma (för levenshtein som kommer att vara avstånd mindre än något värde, för similar_text - någon procent av likheten e t.c. - det är upp till dig att definiera regler).
Likhet, baserad på ord
Tja, alla inbyggda funktioner kommer att misslyckas om vi pratar om fall när du letar efter partiell matchning - speciellt om det handlar om icke-beställd matchning. Därför måste du skapa ett mer komplext jämförelseverktyg. Du har:
- Datasträng (som kommer att finnas i DB, till exempel). Det ser ut som D =D0 D1 D2 ... Dn
- Söksträng (det kommer att vara användarinmatning). Det ser ut som S =S0 S1 ... Sm
Här betyder mellanslagssymboler vilket mellanslag som helst (jag antar att mellanslagssymboler inte påverkar likheten). Även n > m . Med denna definition handlar ditt problem om - att hitta en uppsättning m ord i D som kommer att likna S . Med set Jag menar vilken oordnad sekvens som helst. Därför, om vi hittar någon sådan sekvens i D , sedan S liknar D .
Uppenbarligen, om n < m då innehåller input fler ord än datasträng. I det här fallet kan du antingen tro att de inte är lika eller agera som ovan, men byter data och indata (som dock ser lite udda ut, men är tillämpligt i någon mening)
Implementering
För att göra sakerna måste du kunna skapa en uppsättning strängar som är delar från m ord från D . Baserat på min denna fråga
du kan göra detta med:
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-så för vilken array som helst, getAssoc() kommer att returnera en rad oordnade val som består av m artiklar vardera.
Nästa steg handlar om ordning i producerat urval. Vi bör söka både Niels Andersen och Andersen Niels i vår D sträng. Därför måste du kunna skapa permutationer för array. Det är ett mycket vanligt problem, men jag lägger min version här också:
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
Efter detta kommer du att kunna skapa urval av m ord och sedan, genom att permutera vart och ett av dem, hämta alla varianter för jämförelse med söksträngen S . Den jämförelsen varje gång kommer att göras via någon återuppringning, såsom levenshtein . Här är ett exempel:
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
Detta kommer att kontrollera likheten, baserat på användaråteruppringning, som måste acceptera minst två parametrar (d.v.s. jämförda strängar). Du kanske också vill returnera en sträng som utlöste positiv återuppringning. Observera att den här koden inte skiljer sig åt med versaler och gemener - men du kanske inte vill ha sådant beteende (byt sedan bara ut strtolower() ).
Exempel på fullständig kod finns i denna lista (Jag använde inte sandlåda eftersom jag inte är säker på hur länge kodlistan kommer att vara tillgänglig där). Med detta exempel på användning:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
du får resultat som:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
-här är demo för den här koden, för säkerhets skull.
Komplexitet
Eftersom du inte bara bryr dig om vilka metoder som helst, utan också om - hur bra det är, kanske du märker att sådan kod kommer att producera ganska överdrivna operationer. Jag menar åtminstone generation av strängdelar. Komplexiteten består här av två delar:
- Genereringsdel för strängar. Om du vill generera alla strängdelar - måste du göra detta som jag har beskrivit ovan. Möjlig punkt att förbättra - generering av oordnade stränguppsättningar (som kommer före permutation). Men jag tvivlar fortfarande på att det kan göras eftersom metoden i tillhandahållen kod kommer att generera dem inte med "brute-force", utan eftersom de är matematiskt beräknade (med kardinalitet av
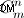 )
) - Del för likhetskontroll. Här beror din komplexitet på given likhetskontroll. Till exempel,
similar_text()har O(N)-komplexitet, så med stora jämförelsemängder blir det extremt långsamt.
Men du kan fortfarande förbättra nuvarande lösning genom att kolla i farten. Nu kommer den här koden först att generera alla strängundersekvenser och sedan börja kontrollera dem en efter en. I vanliga fall behöver du inte göra det, så du kanske vill ersätta det med beteende, när det efter generering av nästa sekvens kommer att kontrolleras omedelbart. Då kommer du att öka prestandan för strängar som har positivt svar (men inte för de som inte har någon matchning).