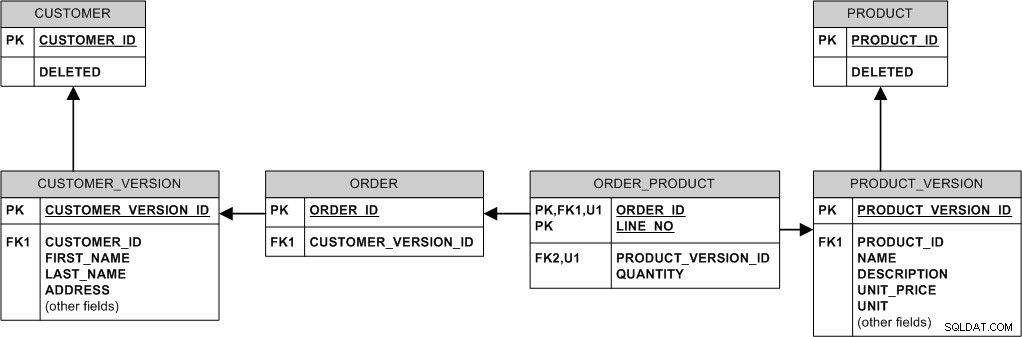
Här är ett sätt att göra det:
I huvudsak ändrar eller raderar vi aldrig befintliga data. Vi "modifierar" den genom att skapa en ny version. Vi "raderar" den genom att sätta flaggan DELETED.
Till exempel:
- Om produkten ändrar priset infogar vi en ny rad i PRODUCT_VERSION medan gamla beställningar hålls kopplade till den gamla PRODUCT_VERSION och det gamla priset.
- När köparen ändrar adress infogar vi helt enkelt en ny rad i CUSTOMER_VERSION och länkar nya beställningar till den, samtidigt som de gamla beställningarna är länkade till den gamla versionen.
- Om produkten raderas tar vi inte riktigt bort den - vi ställer bara in flaggan PRODUCT.DELETED, så att alla beställningar som historiskt gjorts för den produkten stannar i databasen.
- Om kunden raderas (t.ex. för att han/hon begärde att bli avregistrerad), ställ in flaggan CUSTOMER.DELETED.
Varningar:
- Om produktnamnet måste vara unikt kan det inte tillämpas deklarativt i modellen ovan. Du måste antingen "marknadsföra" NAMNET från PRODUCT_VERSION till PRODUCT, göra det till en nyckel där och ge upp möjligheten att "utveckla" produktens namn, eller framtvinga unikhet på endast senaste PRODUCT_VER (troligen genom utlösare).
- Det finns ett potentiellt problem med kundens integritet. Om en kund raderas från systemet kan det vara önskvärt att fysiskt ta bort dess data från databasen och bara att ställa in CUSTOMER.DELETED kommer inte att göra det. Om det är ett problem kan du antingen ta bort integritetskänsliga uppgifter i alla kundens versioner, eller alternativt koppla bort befintliga beställningar från den verkliga kunden och återansluta dem till en speciell "anonym" kund, och sedan fysiskt radera alla kundversioner.
Denna modell använder många identifierande relationer. Detta leder till "feta" främmande nycklar och kan vara lite av ett lagringsproblem eftersom MySQL inte stöder avancerad indexkomprimering (till skillnad från till exempel Oracle), men å andra sidan InnoDB alltid kluster data på PK och denna klustring kan vara fördelaktig för prestanda. Dessutom är JOINs mindre nödvändiga.
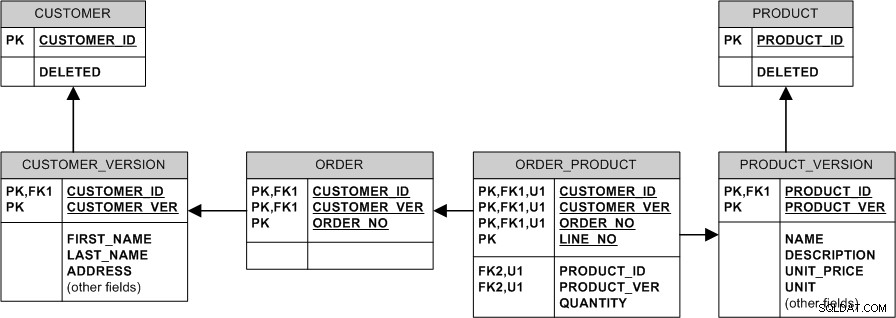
Motsvarande modell med icke-identifierande relationer och surrogatnycklar skulle se ut så här: