Percona XtraDB Cluster är en mycket välkänd lösning med hög tillgänglighet i MySQL-världen. Den är baserad på Galera Cluster och den ger praktiskt taget synkron replikering över flera noder. Som med varje databas är det avgörande att hålla reda på vad som händer i systemet, om prestandan är på förväntade nivåer och, om inte, vad är flaskhalsen. Detta är av yttersta vikt för att kunna reagera ordentligt i den situation där prestationen påverkas. Naturligtvis kommer Percona XtraDB Cluster med flera mätvärden och det är inte alltid klart vilka av dem som är de viktigaste för att spåra databasens tillstånd. I den här bloggen kommer vi att diskutera ett par av de nyckeltal du vill hålla ett öga på när du arbetar med PXC.
För att göra det tydligt kommer vi att fokusera på de mått som är unika för PXC och Galera, vi kommer inte att täcka mått för MySQL eller InnoDB. Dessa mätvärden har diskuterats i våra tidigare bloggar.
Låt oss ta en titt på en del av den viktigaste informationen som PXC presenterar för oss.
Flödeskontroll
Flödeskontroll är i stort sett det viktigaste måttet du kan övervaka i alla Galera-kluster, så låt oss ha lite bakgrund. Galera är ett multi-master, praktiskt taget synkront kluster. Det är möjligt att utföra skrivningar på vilken som helst av databasnoderna som bildar den. Varje skrivning måste skickas till alla noder i klustret för att säkerställa att den kan tillämpas - denna process kallas certifieringen. Ingen transaktion kan tillämpas innan alla noder är överens om att den kan utföras. Om någon av noderna har prestandaproblem som gör att den inte kan hantera trafiken kommer den att börja skicka flödeskontrollmeddelanden som är avsedda att informera resten av klustret om prestandaproblemen och be dem att minska arbetsbelastningen och hjälpa de försenade nod för att komma ikapp resten av klustret.
Du kan spåra när noder var tvungna att införa konstgjord paus för att låta sina eftersläpande kamrater komma ikapp med hjälp av pausade mätvärden för flödeskontroll (wsrep_flow_control_paused):

Du kan också spåra om noden skickar eller tar emot flödeskontrollmeddelanden (wsrep_flow_control_recv och wsrep_flow_control_sent).
Denna information hjälper dig att bättre förstå vilken nod som inte fungerar på samma nivå som sina kamrater. Du kan sedan fokusera på den noden och försöka förstå vad som är problemet och hur du tar bort flaskhalsen.
Skicka och ta emot köer
De här mätvärdena är typ relaterade till flödeskontrollen. Som vi har diskuterat kan en nod släpa efter andra noder i klustret. Det kan orsakas av en ojämn arbetsbelastningsdelning eller av andra orsaker (någon process som körs i bakgrunden, säkerhetskopiering eller några anpassade, tunga frågor). Innan flödeskontrollen sätts igång kommer eftersläpande noder att försöka lagra de inkommande skrivuppsättningarna i mottagningskön (wsrep_local_recv_queue) i hopp om att prestandapåverkan är övergående och den kommer att kunna komma ikapp mycket snart. Endast om kön blir för stor (den styrs av gcs.fc_limit-inställningen), börjar flödeskontrollmeddelanden skickas över klustret.

Du kan tänka dig en mottagningskö som den tidiga markören som visar att det finns är problem med prestandan och flödeskontrollen kan slå in.

Å andra sidan kommer sändkö (wsrep_local_send_queue) att berätta för dig att noden inte kan skicka skrivuppsättningarna till andra medlemmar i klustret, vilket kan indikera problem med nätverksanslutningen (att skjuta skrivuppsättningarna till nätverket är inte riktigt resurskrävande).
Parallelliseringsstatistik
Percona XtraDB-kluster kan konfigureras för att använda flera trådar för att applicera de inkommande skrivuppsättningarna - det gör att det bättre kan hantera flera trådar som ansluter till klustret och utfärdar skrivningar samtidigt. Det finns två huvudmått som du kanske vill hålla ett öga på.
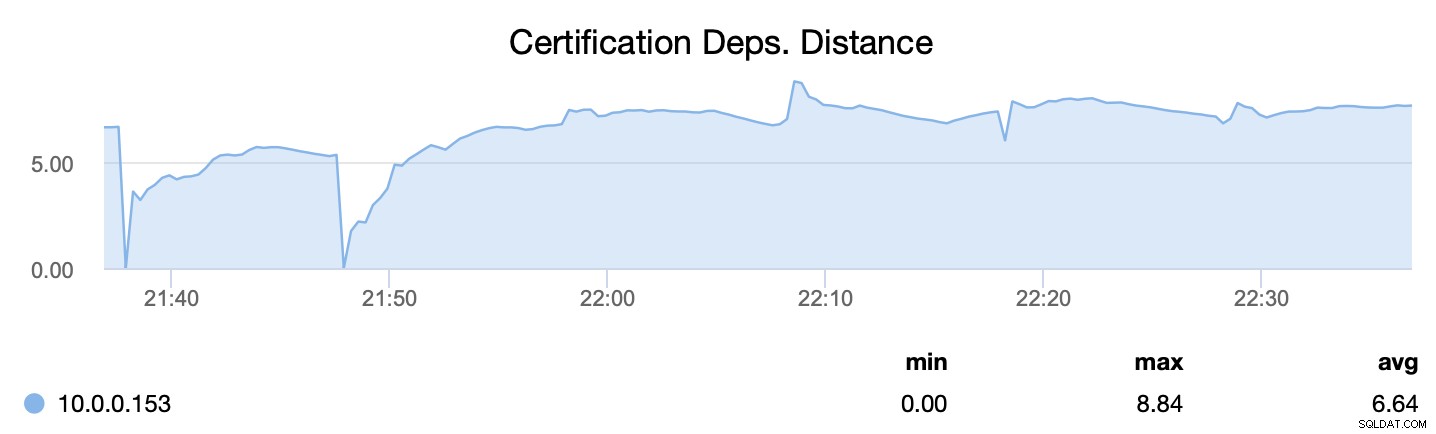
Först, wsrep_cert_deps_distance, berättar för oss vad som är parallelliseringspotentialen - hur många skrivuppsättningar som potentiellt kan användas samtidigt. Baserat på detta värde kan du konfigurera antalet parallella slavtrådar (wsrep_slave_threads) som kommer att fungera med att tillämpa inkommande skrivuppsättningar. Tumregeln är att det inte är någon idé att konfigurera fler trådar än värdet på wsrep_cert_deps_distance.
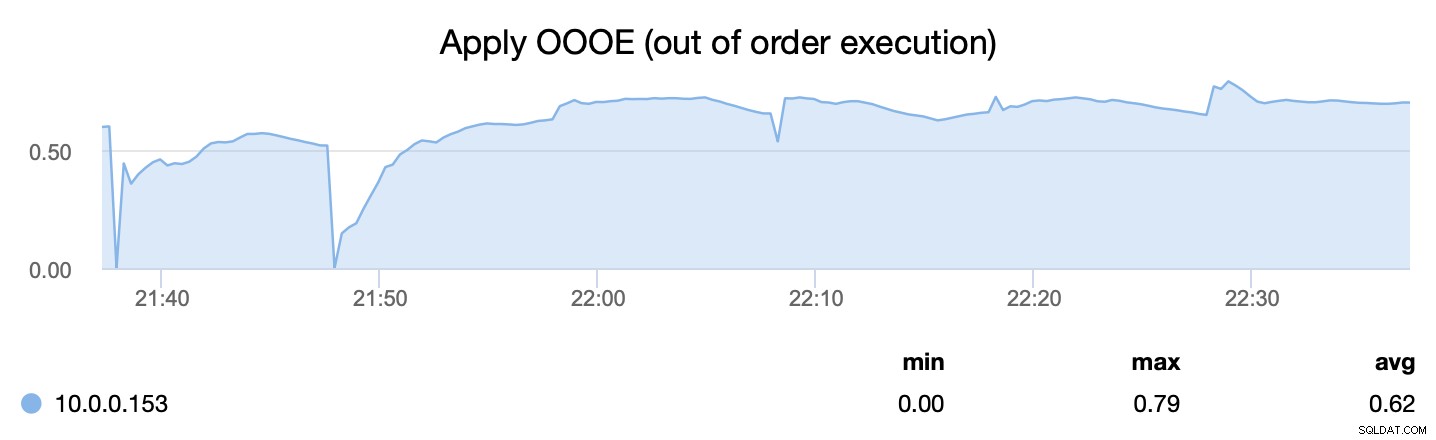
Andra måttet, å andra sidan, berättar för oss hur effektivt vi kunde parallellisera processen med att applicera skrivuppsättningar - wsrep_apply_oooe berättar hur ofta applikatorn började tillämpa skrivuppsättningar i oordning (vilket pekar mot bättre parallellisering ).
Slutsats
Som du kan se finns det ett par mätvärden värda att titta på i Percona XtraDB Cluster. Naturligtvis, som vi sa i början av den här bloggen, är dessa mätvärden strikt relaterade till PXC och Galera Cluster i allmänhet.
Du bör också hålla ett öga på vanliga MySQL- och InnoDB-mått för att få en bättre förståelse av tillståndet i din databas. Och kom ihåg att du kan övervaka den här tekniken gratis med ClusterControl Community Edition.