Bygga hög tillgänglighet, ett steg i taget
När det gäller databasinfrastruktur vill vi alla ha det. Vi strävar alla efter att bygga en mycket tillgänglig installation. Redundans är nyckeln. Vi börjar implementera redundans på den lägsta nivån och fortsätter upp i stacken. Det börjar med hårdvara - redundant strömförsörjning, redundant kylning, hot-swap-diskar. Nätverkslager - flera nätverkskort sammanfogade och anslutna till olika switchar som använder redundanta routrar. För lagring använder vi diskar inställda i RAID, vilket ger bättre prestanda men också redundans. Sedan, på mjukvarunivå, använder vi klustringsteknik:flera databasnoder som arbetar tillsammans för att implementera redundans:MySQL Cluster, Galera Cluster.
Allt detta är inte bra om du har allt i ett enda datacenter:när ett datacenter går ner, eller en del av tjänsterna (men viktiga sådana) går offline, eller även om du förlorar anslutningen till datacentret, kommer din tjänst att gå ner - oavsett mängden redundans i de lägre nivåerna. Och ja, de sakerna händer.
- S3-tjänstavbrott orsakade förödelse i USA-Öst-1-regionen i februari 2017
- EC2- och RDS-tjänstavbrott i USA-östra regionen i april 2011
- EC2, EBS och RDS stördes i EU-West-regionen i augusti 2011
- Strömavbrott orsakade Rackspace Texas DC i juni 2009
- UPS-fel fick hundratals servrar att gå offline i Rackspace London DC i januari 2010
Detta är inte på något sätt en komplett lista över misslyckanden, det är bara resultatet av en snabb Google-sökning. Dessa fungerar som exempel på att saker kan och kommer att gå fel om du lägger alla dina ägg i samma korg. Ytterligare ett exempel skulle vara orkanen Sandy, som orsakade en enorm utvandring av data från USA-öst till USA-västra DC - vid den tiden kunde man knappast spinna upp instanser i USA-väst när alla skyndade sig att flytta sin infrastruktur till den andra kusten i förväntan. att North Virginia DC kommer att påverkas allvarligt av vädret.
Så, multi-datacenter-inställningar är ett måste om du vill bygga en miljö med hög tillgänglighet. I det här blogginlägget kommer vi att diskutera hur man bygger en sådan infrastruktur med Galera Cluster för MySQL/MariaDB.
Galerakoncept
Innan vi tittar på specifika lösningar, låt oss ägna lite tid åt att förklara två koncept som är mycket viktiga i högt tillgängliga, multi-DC Galera-uppsättningar.
Quorum
Hög tillgänglighet kräver resurser – man behöver nämligen ett antal noder i klustret för att göra det högt tillgängligt. Ett kluster kan tolerera förlusten av några av sina medlemmar, men bara i viss utsträckning. Utöver en viss misslyckandefrekvens, kanske du tittar på ett scenario med split-brain.
Låt oss ta ett exempel med en 2-nodsinställning. Om en av noderna går ner, hur kan den andra veta att dess peer kraschade och att det inte är ett nätverksfel? I så fall kan den andra noden lika gärna vara igång och betjäna trafik. Det finns inget bra sätt att hantera sådana fall... Det är därför feltolerans vanligtvis börjar från tre noder. Galera använder en kvorumberäkning för att avgöra om det är säkert för klustret att hantera trafik, eller om det ska upphöra. Efter ett misslyckande försöker alla återstående noder att ansluta till varandra och avgöra hur många av dem som är uppe. Det jämförs sedan med det tidigare tillståndet för klustret, och så länge som mer än 50 % av noderna är uppe kan klustret fortsätta att fungera.
Detta resulterar i följande:
2 nodkluster - ingen feltolerans
3 nodkluster - upp till 1 krasch
4 nodkluster - upp till 1 krasch (om två noder skulle krascha, bara 50 % av klustret skulle vara tillgängligt, du behöver mer än 50 % noder för att överleva)
5 nodkluster - upp till 2 krascher
6 nodkluster - upp till 2 krascher
Du ser förmodligen mönstret - du vill att ditt kluster ska ha ett udda antal noder - vad gäller hög tillgänglighet är det ingen idé att flytta från 5 till 6 noder i klustret. Om du vill ha bättre feltolerans bör du välja 7 noder.
Segment
I ett Galera-kluster följer vanligtvis all kommunikation mönstret från allt till alla. Varje nod pratar med alla andra noder i klustret.
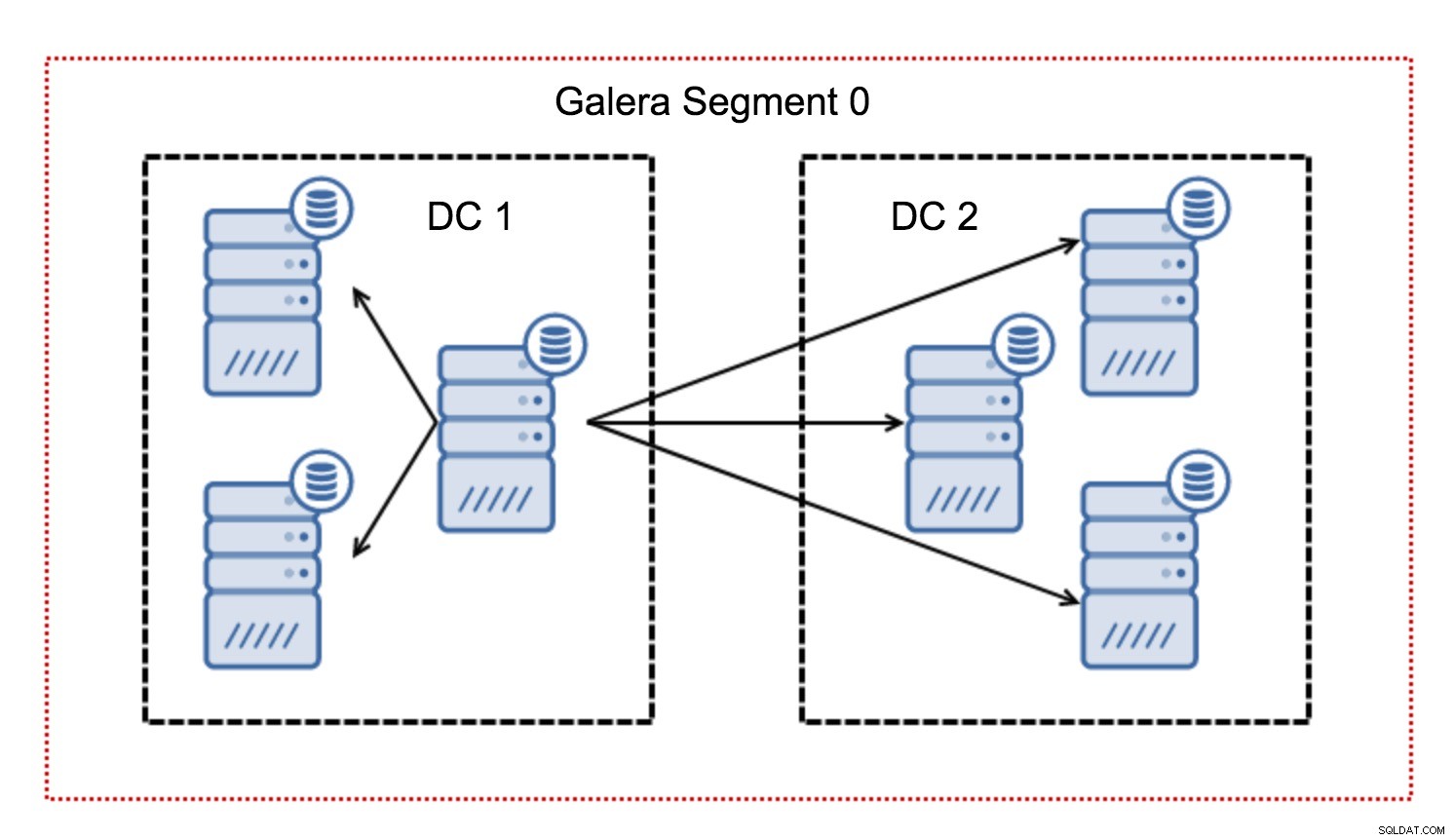
Som du kanske vet måste varje skrivuppsättning i Galera certifieras av alla noder i klustret - därför måste varje skrivning som hände på en nod överföras till alla noder i klustret. Detta fungerar ok i en miljö med låg latens. Men om vi pratar om multi-DC-inställningar måste vi överväga mycket högre latens än i ett lokalt nätverk. För att göra det mer uthärdligt i kluster som spänner över Wide Area Networks, introducerade Galera segment.
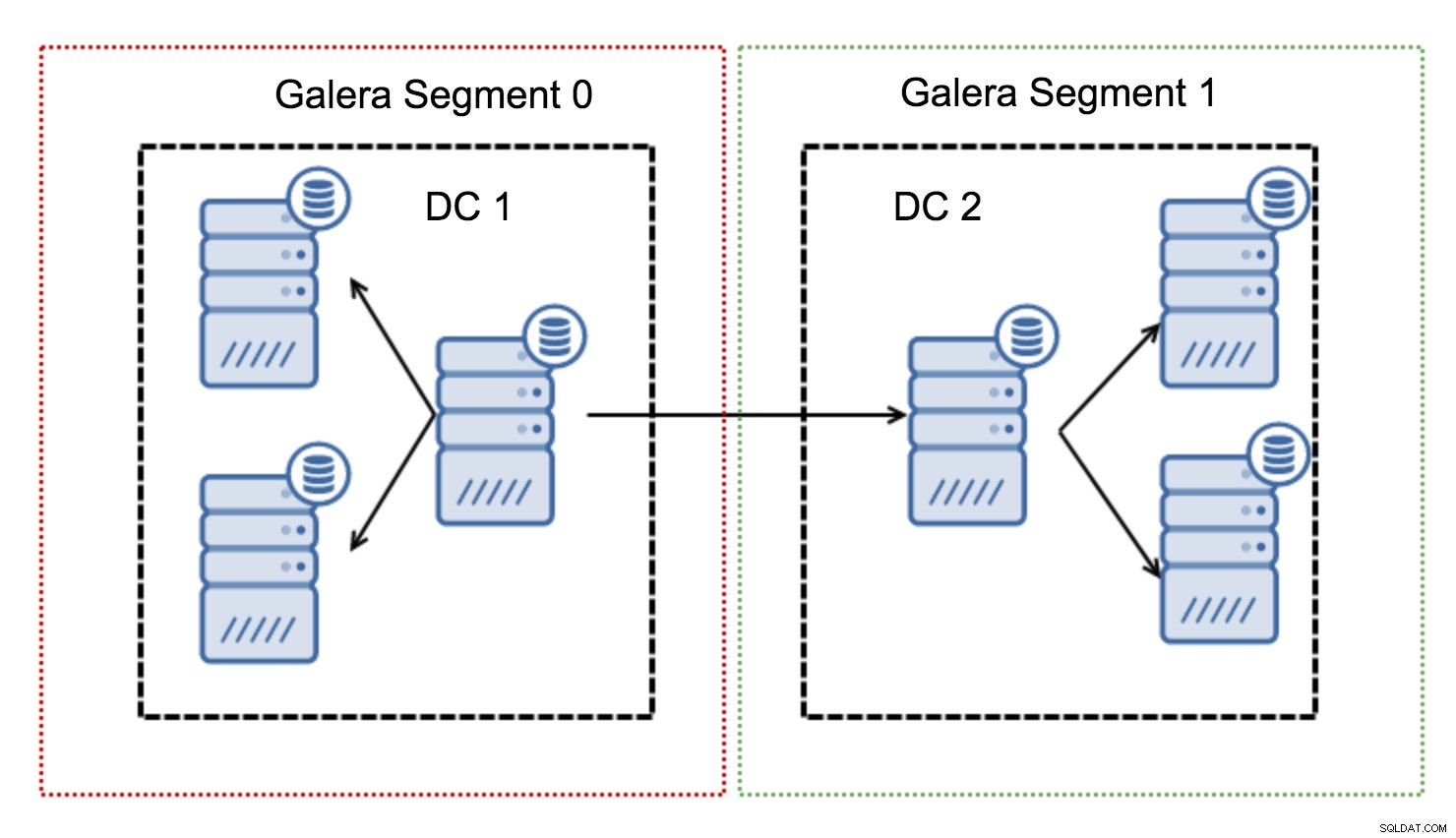
De fungerar genom att innehålla Galera-trafiken inom en grupp av noder (segment). Alla noder inom ett enskilt segment fungerar som om de vore i ett lokalt nätverk - de antar en till all kommunikation. För tvärsegmentstrafik är saker och ting annorlunda - i vart och ett av segmenten väljs en "relä"-nod, all tvärsegmentstrafik går genom dessa noder. När en relänod går ner väljs en annan nod. Detta minskar inte latensen mycket - trots allt kommer WAN-latensen att förbli densamma oavsett om du gör en anslutning till en fjärrvärd eller till flera fjärrvärdar, men med tanke på att WAN-länkar tenderar att vara begränsade i bandbredd och det kan finnas en ta betalt för mängden data som överförs, ett sådant tillvägagångssätt låter dig begränsa mängden data som utbyts mellan segment. Ett annat tids- och kostnadsbesparande alternativ är det faktum att noder i samma segment prioriteras när en donator behövs - återigen, detta begränsar mängden data som överförs över WAN och, med största sannolikhet, snabbar upp SST som ett lokalt nätverk nästan alltid kommer att vara snabbare än en WAN-länk.
Nu när vi har fått några av dessa koncept ur vägen, låt oss titta på några andra viktiga aspekter av multi-DC-inställningar för Galera-klustret.
Problem som du är på väg att möta
När du arbetar i miljöer som sträcker sig över WAN finns det ett par frågor du måste ta hänsyn till när du utformar din miljö.
Quorumberäkning
I föregående avsnitt beskrev vi hur en kvorumberäkning ser ut i Galera-klustret – kort och gott vill man ha ett udda antal noder för att maximera överlevnadsförmågan. Allt detta är fortfarande sant i multi-DC-inställningar, men några fler element läggs till i mixen. Först och främst måste du bestämma om du vill att Galera automatiskt ska hantera ett datacenterfel. Detta kommer att avgöra hur många datacenter du kommer att använda. Låt oss föreställa oss två DC:er - om du delar upp dina noder 50% - 50%, om ett datacenter går ner, har det andra inte 50%+1 noder för att behålla sitt "primära" tillstånd. Om du delar upp dina noder på ett ojämnt sätt och använder majoriteten av dem i "huvuddatacentret", när det datacentret går ner, kommer "backup" DC inte att ha 50 % + 1 noder för att bilda ett kvorum. Du kan tilldela olika vikter till noder men resultatet blir exakt detsamma - det finns inget sätt att automatiskt överta mellan två DC utan manuellt ingripande. För att implementera automatisk failover behöver du mer än två DC:er. Återigen, idealiskt ett udda antal - tre datacenter är en perfekt inställning. Därefter är frågan - hur många noder behöver du ha? Du vill ha dem jämnt fördelade över datacentren. Resten är bara en fråga om hur många misslyckade noder din installation måste hantera.
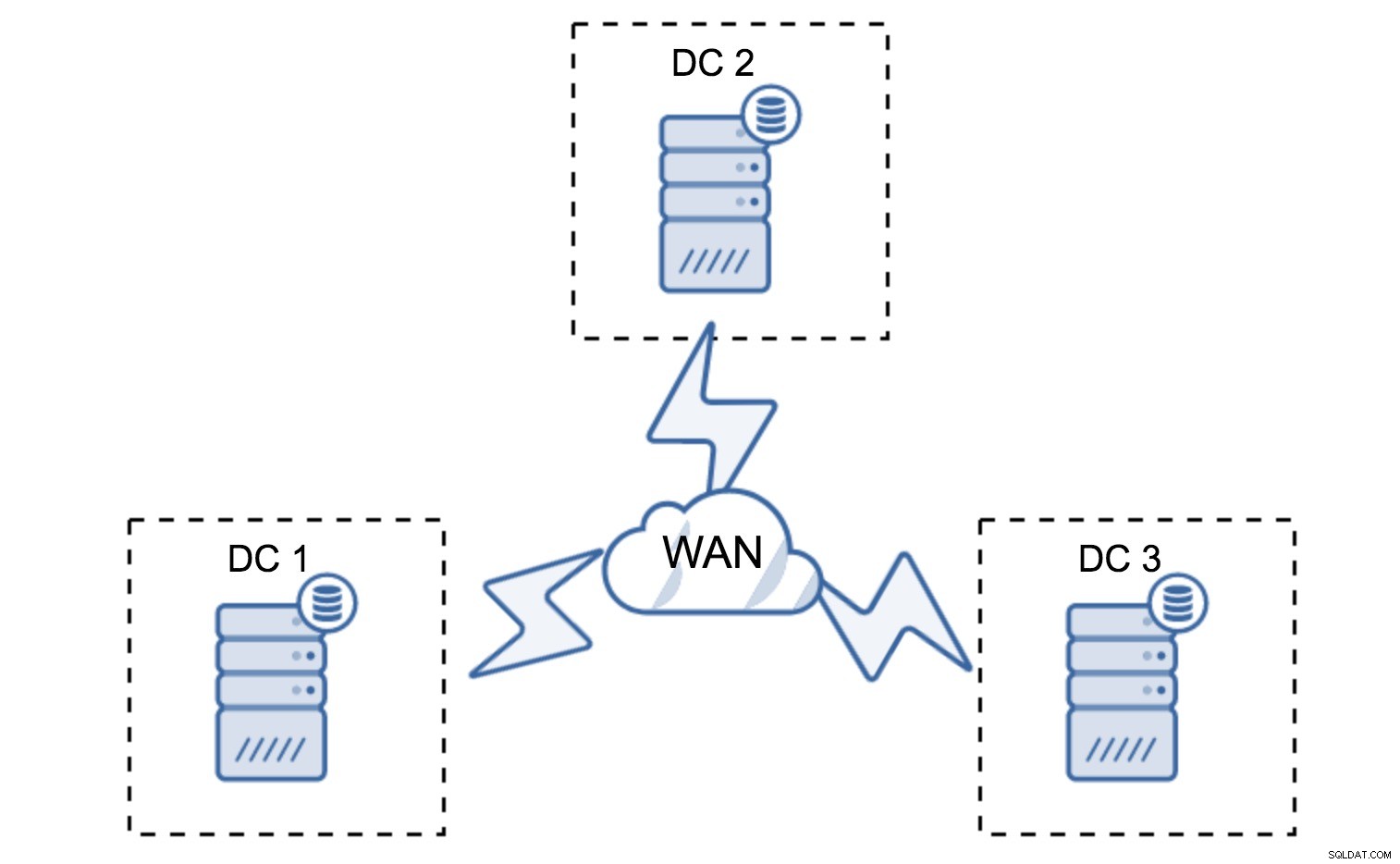
Minimal installation kommer att använda en nod per datacenter - det har dock allvarliga nackdelar. Varje tillståndsöverföring kommer att kräva att data flyttas över WAN och detta resulterar i antingen längre tid som krävs för att slutföra SST eller högre kostnader.
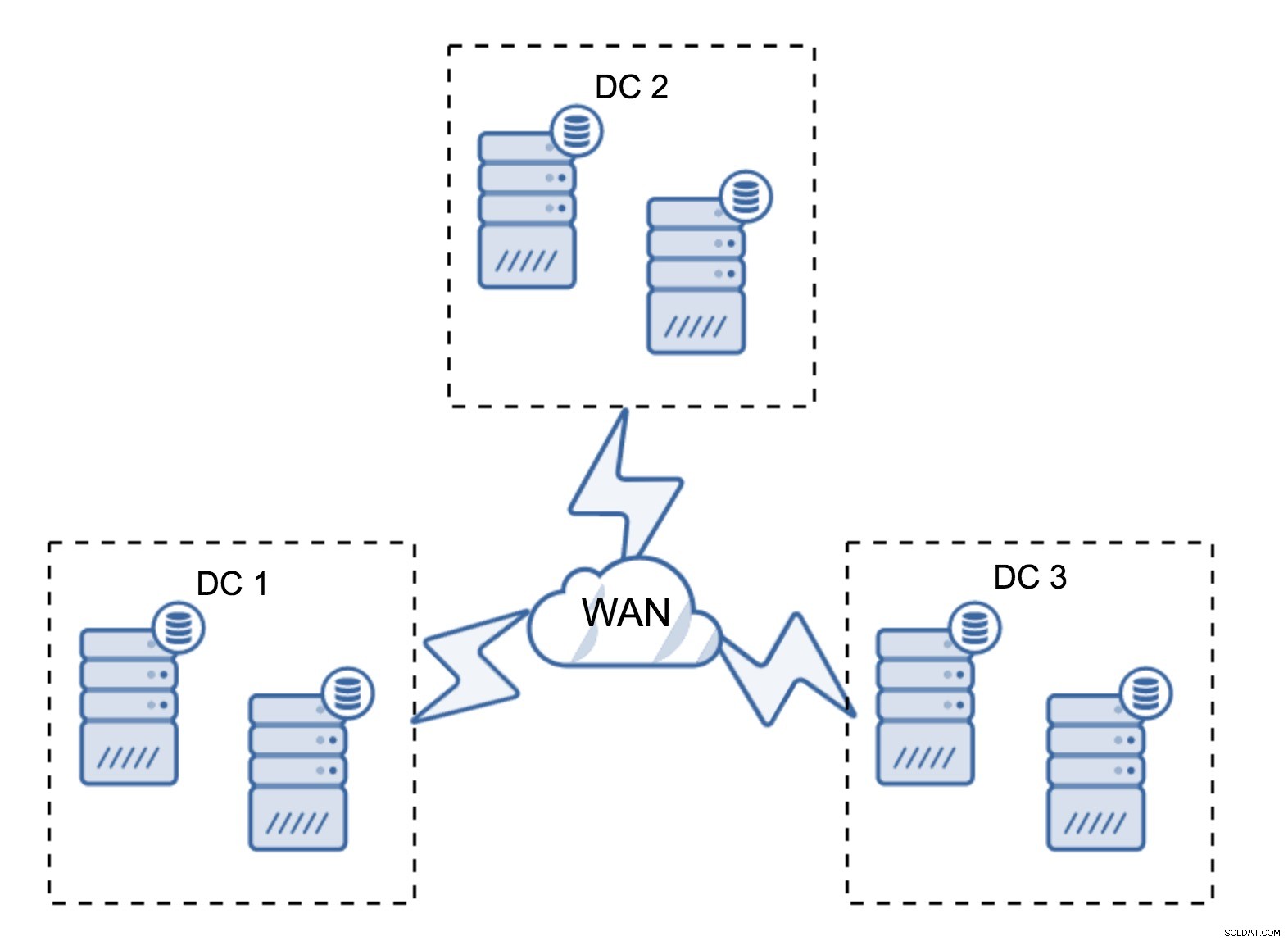
En ganska typisk installation är att ha sex noder, två per datacenter. Denna inställning verkar oväntad eftersom den har ett jämnt antal noder. Men när du tänker på det kanske det inte är så stort problem:det är ganska osannolikt att tre noder kommer att gå ner på en gång, och en sådan installation kommer att överleva en krasch på upp till två noder. Ett helt datacenter kan gå offline och två återstående DC:er kommer att fortsätta sin verksamhet. Det har också en stor fördel jämfört med den minimala installationen - när en nod går offline finns det alltid en andra nod i datacentret som kan fungera som en donator. För det mesta kommer WAN inte att användas för SST.
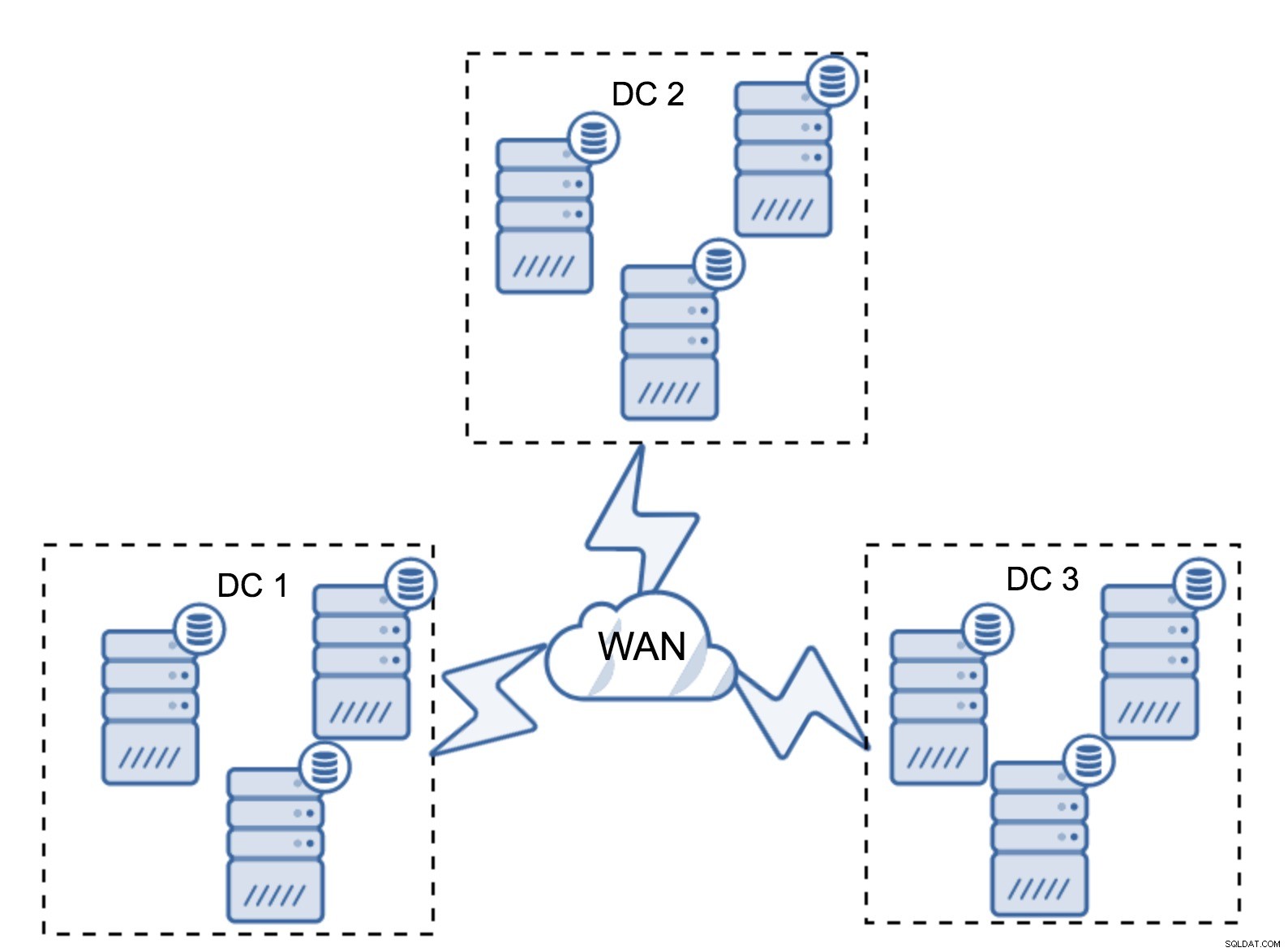
Naturligtvis kan du öka antalet noder till tre per kluster, nio totalt. Detta ger dig ännu bättre överlevnadsförmåga:upp till fyra noder kan krascha och klustret kommer fortfarande att överleva. Å andra sidan måste du komma ihåg att, även med användning av segment, innebär fler noder högre driftskostnader och att du bara kan skala ut Galera-klustret i viss utsträckning.
Det kan hända att det inte finns något behov av ett tredje datacenter eftersom, låt oss säga, din applikation finns i endast två av dem. Naturligtvis är kravet på tre datacenter fortfarande giltigt så du kommer inte att gå runt det, men det går alldeles utmärkt att använda en Galera Arbitrator (garbd) istället för fullastade databasservrar.
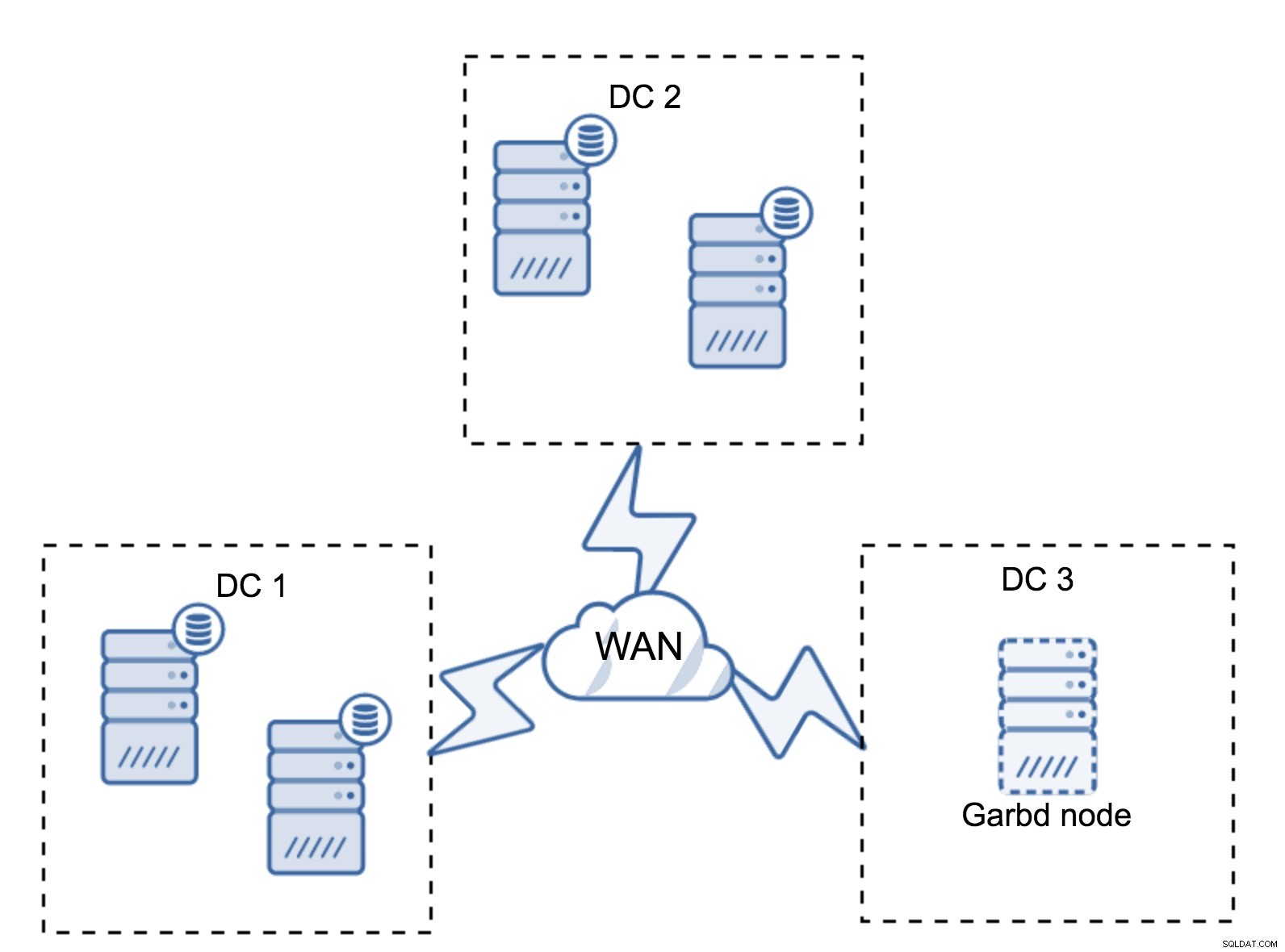
Garbd kan installeras på mindre noder, även virtuella servrar. Den kräver ingen kraftfull hårdvara, den lagrar ingen data eller använder någon av skrivuppsättningarna. Men den ser all replikeringstrafik och deltar i kvorumberäkningen. Tack vare det kan du distribuera inställningar som fyra noder, två per DC + garbd i den tredje - du har fem noder totalt, och ett sådant kluster kan acceptera upp till två fel. Så det betyder att den kan acceptera en fullständig avstängning av ett av datacenterna.
Vilket alternativ är bättre för dig? Det finns ingen bästa lösning för alla fall, allt beror på dina infrastrukturkrav. Lyckligtvis finns det olika alternativ att välja mellan:fler eller färre noder, full 3 DC eller 2 DC och garbd i den tredje - det är ganska troligt att du hittar något som passar dig.
Nätverkslatens
När du arbetar med multi-DC-inställningar måste du komma ihåg att nätverkslatens kommer att vara betydligt högre än vad du kan förvänta dig från en lokal nätverksmiljö. Detta kan allvarligt minska prestandan för Galera-klustret när du jämför det med en fristående MySQL-instans eller en MySQL-replikeringsinställning. Kravet på att alla noder måste certifiera en skrivuppsättning innebär att alla noder måste ta emot den, oavsett hur långt bort de är. Med asynkron replikering behöver du inte vänta innan en commit. Naturligtvis har replikering andra problem och nackdelar, men latens är inte den största. Problemet är särskilt synligt när din databas har hot spots - rader, som uppdateras ofta (räknare, köer, etc). Dessa rader kan inte uppdateras oftare än en gång per nätverk tur och retur. För kluster som spänner över hela världen kan detta lätt betyda att du inte kommer att kunna uppdatera en enda rad oftare än 2 - 3 gånger per sekund. Om detta blir en begränsning för dig kan det betyda att Galera-klustret inte passar för just din arbetsbelastning.
Proxylager i Multi-DC Galera Cluster
Det räcker inte att ha Galera-kluster som sträcker sig över flera datacenter, du behöver fortfarande din applikation för att komma åt dem. En av de populära metoderna för att dölja komplexiteten hos databaslagret från en applikation är att använda en proxy. Proxies används som en ingång till databaserna, de spårar databasnodernas tillstånd och ska alltid dirigera trafik till endast de noder som är tillgängliga. I det här avsnittet kommer vi att försöka föreslå en proxylagerdesign som kan användas för ett multi-DC Galera-kluster. Vi kommer att använda ProxySQL, vilket ger dig en hel del flexibilitet vid hantering av databasnoder, men du kan använda en annan proxy, så länge den kan spåra Galera-nodernas tillstånd.
Var hittar man proxyservrar?
Kort sagt, det finns två vanliga mönster här:du kan antingen distribuera ProxySQL på en separat nod eller så kan du distribuera dem på applikationsvärdarna. Låt oss ta en titt på för- och nackdelar med var och en av dessa inställningar.
Proxylager som en separat uppsättning värdar
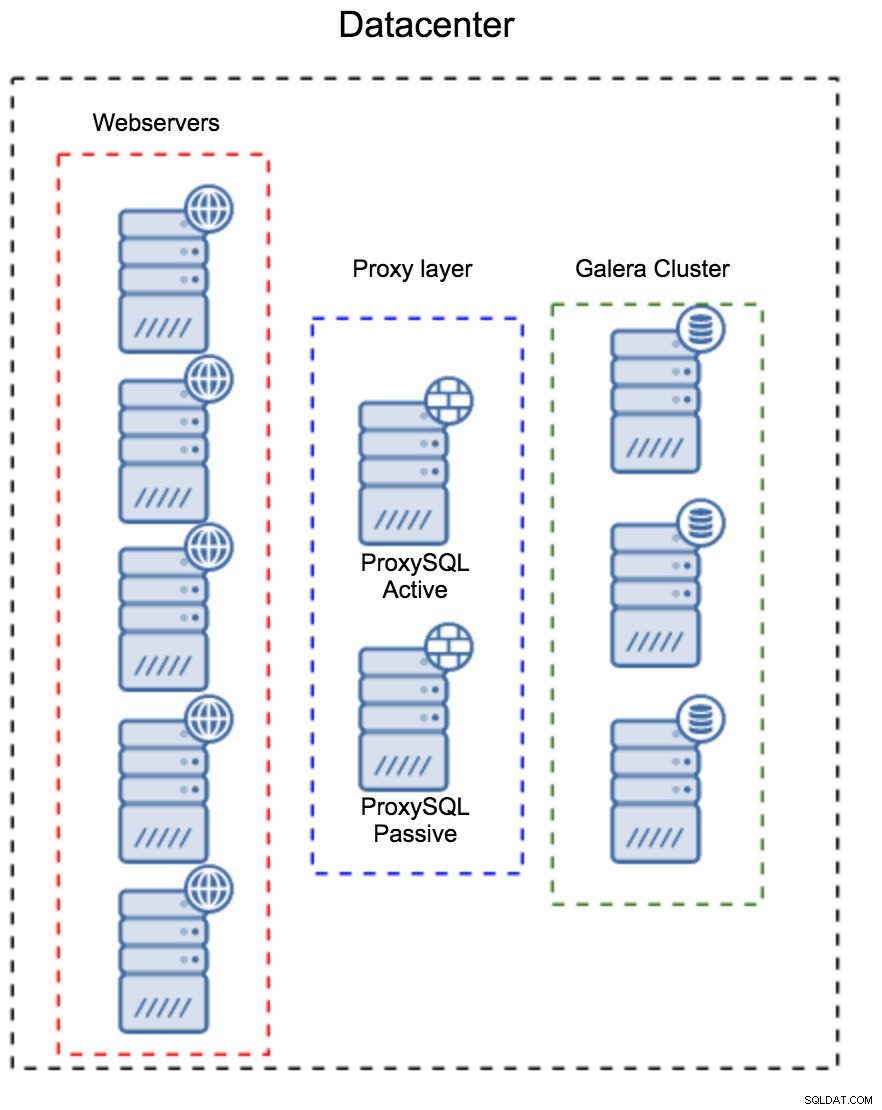
Det första mönstret är att bygga ett proxylager med hjälp av separata, dedikerade värdar. Du kan distribuera ProxySQL på ett par värdar och använda virtuell IP och keepalive för att upprätthålla hög tillgänglighet. En applikation kommer att använda VIP för att ansluta till databasen, och VIP kommer att se till att förfrågningar alltid kommer att dirigeras till en tillgänglig ProxySQL. Huvudproblemet med den här installationen är att du använder högst en av ProxySQL-instanserna - alla standbynoder används inte för att dirigera trafiken. Detta kan tvinga dig att använda kraftfullare hårdvara än du vanligtvis använder. Å andra sidan är det lättare att underhålla inställningen - du måste tillämpa konfigurationsändringar på alla ProxySQL-noder, men det kommer bara att finnas en handfull av dem. Du kan också använda ClusterControls alternativ för att synkronisera noderna. Sådana inställningar måste dupliceras på varje datacenter som du använder.
Proxy installerad på applikationsinstanser
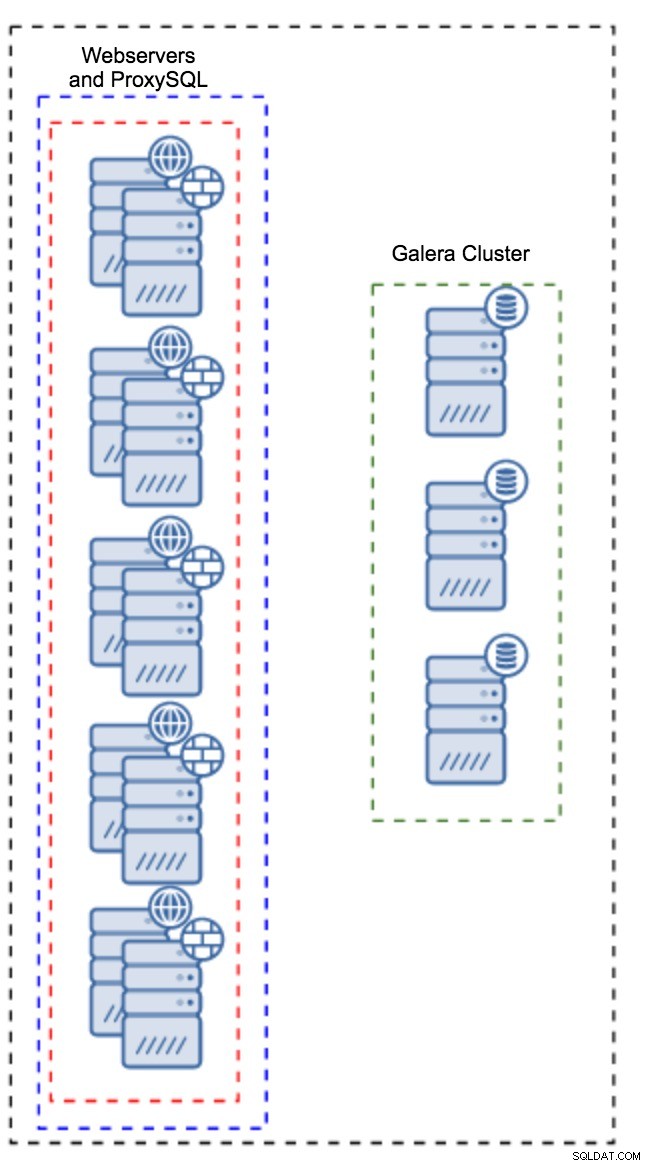
Istället för att ha en separat uppsättning värdar kan ProxySQL också installeras på applikationsvärdarna. Applikationen kommer att ansluta direkt till ProxySQL på localhost, den kan till och med använda unix-socket för att minimera TCP-anslutningens overhead. Den största fördelen med en sådan installation är att du har ett stort antal ProxySQL-instanser, och belastningen är jämnt fördelad över dem. Om en går ner kommer bara den applikationsvärden att påverkas. De återstående noderna kommer att fortsätta att fungera. Det allvarligaste problemet att möta är konfigurationshantering. Med ett stort antal ProxySQL-noder är det avgörande att komma på en automatiserad metod för att hålla sina konfigurationer synkroniserade. Du kan använda ClusterControl, eller ett konfigurationshanteringsverktyg som Puppet.
Inställning av Galera i en WAN-miljö
Galera standardinställningar är designade för lokala nätverk och om du vill använda det i en WAN-miljö krävs viss justering. Låt oss diskutera några av de grundläggande justeringarna du kan göra. Kom ihåg att den exakta justeringen kräver produktionsdata och trafik - du kan inte bara göra några ändringar och anta att de är bra, du bör göra korrekt benchmarking.
Konfiguration av operativsystem
Låt oss börja med operativsystemets konfiguration. Alla ändringar som föreslås här är inte WAN-relaterade, men det är alltid bra att påminna oss själva om vad som är en bra utgångspunkt för alla MySQL-installationer.
vm.swappiness = 1Swappiness styr hur aggressivt operativsystemet kommer att använda swap. Det bör inte ställas in på noll eftersom det i nyare kärnor förhindrar operativsystemet från att använda swap alls och det kan orsaka allvarliga prestandaproblem.
/sys/block/*/queue/scheduler = deadline/noopSchemaläggaren för blockenheten, som MySQL använder, bör ställas in på antingen deadline eller noop. Det exakta valet beror på riktmärkena men båda inställningarna bör ge liknande prestanda, bättre än standardschemaläggaren, CFQ.
För MySQL bör du överväga att använda EXT4 eller XFS, beroende på kärnan (prestandan för dessa filsystem ändras från en kärnversion till en annan). Utför några riktmärken för att hitta det bättre alternativet för dig.
Utöver detta kanske du vill titta på sysctl nätverksinställningar. Vi kommer inte att diskutera dem i detalj (du kan hitta dokumentation här) men den allmänna idén är att öka buffertar, eftersläpningar och timeouts, för att göra det lättare att ta emot stall och instabil WAN-länk.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0Förutom OS-justering bör du överväga att justera Galera nätverksrelaterade inställningar.
evs.suspect_timeout
evs.inactive_timeoutDu kanske vill överväga att ändra standardvärdena för dessa variabler. Båda timeouts styr hur klustret vräker misslyckade noder. Misstänkt timeout äger rum när alla noder inte kan nå den inaktiva medlemmen. Inaktiv timeout definierar en hård gräns för hur länge en nod kan stanna i klustret om den inte svarar. Vanligtvis kommer du att upptäcka att standardvärdena fungerar bra. Men i vissa fall, särskilt om du kör ditt Galera-kluster över WAN (till exempel mellan AWS-regioner), kan ökning av dessa variabler resultera i mer stabil prestanda. Vi föreslår att du ställer in båda på PT1M för att göra det mindre troligt att instabilitet i WAN-länken kommer att kasta ut en nod ur klustret.
evs.send_window
evs.user_send_windowDessa variabler, evs.send_window och evs.user_send_window , definiera hur många paket som kan skickas via replikering samtidigt (evs.send_window ) och hur många av dem som kan innehålla data (evs.user_send_window ). För anslutningar med hög latens kan det vara värt att öka dessa värden avsevärt (till exempel 512 eller 1024).
evs.inactive_check_periodOvanstående variabel kan också ändras. evs.inactive_check_period , som standard, är inställd på en sekund, vilket kan vara för ofta för en WAN-installation. Vi föreslår att du ställer in den på PT30S.
gcs.fc_factor
gcs.fc_limitHär vill vi minimera chanserna att flödeskontroll kommer att slå in, därför föreslår vi att du ställer in gcs.fc_factor till 1 och öka gcs.fc_limit till till exempel 260.
gcs.max_packet_sizeEftersom vi arbetar med WAN-länken, där latensen är betydligt högre, vill vi öka storleken på paketen. En bra utgångspunkt skulle vara 2097152.
Som vi nämnde tidigare är det praktiskt taget omöjligt att ge ett enkelt recept på hur man ställer in dessa parametrar eftersom det beror på för många faktorer - du måste göra dina egna benchmarks, använda data så nära dina produktionsdata som möjligt, innan du kan säga att ditt system är inställt. Med det sagt borde dessa inställningar ge dig en utgångspunkt för den mer exakta inställningen.
Det var allt för nu. Galera fungerar ganska bra i WAN-miljöer, så prova det och låt oss veta hur du går vidare.