Python och SQL är två av de viktigaste språken för dataanalytiker.
I den här artikeln kommer jag att gå igenom allt du behöver veta för att ansluta Python och SQL.
Du kommer att lära dig hur du drar data från relationsdatabaser rakt in i dina maskininlärningspipelines, lagrar data från din Python-applikation i en egen databas eller vilket annat användningsfall du kan komma på.
Tillsammans täcker vi:
- Varför lära sig hur man använder Python och SQL tillsammans?
- Hur du ställer in din Python-miljö och MySQL-server
- Ansluter till MySQL Server i Python
- Skapa en ny databas
- Skapa tabeller och tabellrelationer
- Fylla tabeller med data
- Läser data
- Uppdatera poster
- Ta bort poster
- Skapa poster från Python-listor
- Skapa återanvändbara funktioner för att göra allt detta åt oss i framtiden
Det är mycket mycket användbart och väldigt coolt. Låt oss komma in i det!
En snabb notering innan vi börjar:det finns en Jupyter Notebook som innehåller all kod som används i denna handledning tillgänglig i detta GitHub-förråd. Kodning rekommenderas starkt!
Databasen och SQL-koden som används här är allt från min tidigare Introduktion till SQL-serie som publicerades på Towards Data Science (kontakta mig om du har några problem med att se artiklarna så kan jag skicka en länk för att se dem gratis).
Om du inte är bekant med SQL och koncepten bakom relationsdatabaser, skulle jag peka dig mot den serien (plus att det såklart finns en enorm mängd bra saker tillgängliga här på freeCodeCamp!)
Varför Python med SQL?
För dataanalytiker och dataforskare har Python många fördelar. Ett stort utbud av öppen källkodsbibliotek gör det till ett otroligt användbart verktyg för alla dataanalytiker.
Vi har pandor, NumPy och Vaex för dataanalys, Matplotlib, seaborn och Bokeh för visualisering, och TensorFlow, scikit-learn och PyTorch för maskininlärningsapplikationer (plus många, många fler).
Med sin (relativt) lätta inlärningskurva och mångsidighet är det inte konstigt att Python är ett av de snabbast växande programmeringsspråken där ute.
Så om vi använder Python för dataanalys är det värt att fråga - var kommer all denna data ifrån?
Även om det finns en enorm mängd källor för datauppsättningar, kommer data i många fall - särskilt i företagsföretag - att lagras i en relationsdatabas. Relationsdatabaser är ett extremt effektivt, kraftfullt och allmänt använt sätt att skapa, läsa, uppdatera och radera data av alla slag.
De mest använda relationsdatabashanteringssystemen (RDBMS) - Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 - använder alla Structured Query Language (SQL) för att komma åt och göra ändringar i data.
Observera att varje RDBMS använder en lite olika variant av SQL, så SQL-kod som skrivits för en kommer vanligtvis inte att fungera i en annan utan (normalt ganska små) ändringar. Men koncepten, strukturerna och verksamheten är i stort sett identiska.
Detta innebär för en arbetande dataanalytiker att en stark förståelse för SQL är oerhört viktig. Att veta hur man använder Python och SQL tillsammans kommer att ge dig ännu mer fördel när det gäller att arbeta med dina data.
Resten av den här artikeln kommer att ägnas åt att visa dig exakt hur vi kan göra det.
Komma igång
Krav och installation
För att koda tillsammans med den här handledningen behöver du din egen Python-miljö konfigurerad.
Jag använder Anaconda, men det finns många sätt att göra detta på. Googla bara på "hur man installerar Python" om du behöver ytterligare hjälp. Du kan också använda Binder för att koda tillsammans med den tillhörande Jupyter Notebook.
Vi kommer att använda MySQL Community Server eftersom den är gratis och används ofta i branschen. Om du använder Windows hjälper den här guiden dig att komma igång. Här är guider för Mac- och Linux-användare också (även om det kan variera beroende på Linux-distribution).
När du har ställt in dem måste vi få dem att kommunicera med varandra.
För det måste vi installera MySQL Connector Python-biblioteket. För att göra detta, följ instruktionerna, eller använd bara pip:
pip install mysql-connector-pythonVi kommer också att använda pandor, så se till att du har det installerat också.
pip install pandasImportera bibliotek
Som med alla projekt i Python är det allra första vi vill göra att importera våra bibliotek.
Det är bästa praxis att importera alla bibliotek vi ska använda i början av projektet, så att folk som läser eller granskar vår kod vet ungefär vad som kommer upp så att det inte blir några överraskningar.
För den här handledningen kommer vi bara att använda två bibliotek - MySQL Connector och pandor.
import mysql.connector
from mysql.connector import Error
import pandas as pdVi importerar felfunktionen separat så att vi har enkel tillgång till den för våra funktioner.
Ansluter till MySQL Server
Vid det här laget bör vi ha MySQL Community Server inställd på vårt system. Nu måste vi skriva lite kod i Python som låter oss upprätta en anslutning till den servern.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionAtt skapa en återanvändbar funktion för kod som denna är bästa praxis, så att vi kan använda denna om och om igen med minimal ansträngning. När detta är skrivet när du kan återanvända det i alla dina projekt i framtiden också, så i framtiden kommer du att vara tacksam!
Låt oss gå igenom detta rad för rad så att vi förstår vad som händer här:
Den första raden är att vi namnger funktionen (create_server_connection) och namnger argumenten som den funktionen kommer att ta (värdnamn, användarnamn och användarlösenord).
Nästa rad stänger alla befintliga anslutningar så att servern inte förväxlas med flera öppna anslutningar.
Därefter använder vi ett Python try-except-block för att hantera eventuella fel. Den första delen försöker skapa en anslutning till servern med metoden mysql.connector.connect() med de detaljer som specificeras av användaren i argumenten. Om detta fungerar skriver funktionen ut ett glatt litet framgångsmeddelande.
Utom delen av blocket skriver ut felet som MySQL Server returnerar, i den olyckliga omständigheten att det finns ett fel.
Slutligen, om anslutningen lyckas, returnerar funktionen ett anslutningsobjekt.
Vi använder detta i praktiken genom att tilldela funktionens utdata till en variabel, som sedan blir vårt kopplingsobjekt. Vi kan sedan använda andra metoder (som markör) på den och skapa andra användbara objekt.
connection = create_server_connection("localhost", "root", pw)Detta bör ge ett framgångsmeddelande:

Skapa en ny databas
Nu när vi har upprättat en anslutning är vårt nästa steg att skapa en ny databas på vår server.
I den här handledningen kommer vi bara att göra detta en gång, men återigen kommer vi att skriva detta som en återanvändbar funktion så att vi har en bra användbar funktion som vi kan återanvända för framtida projekt.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")Denna funktion tar två argument, anslutning (vårt anslutningsobjekt) och fråga (en SQL-fråga som vi kommer att skriva i nästa steg). Den exekverar frågan på servern via anslutningen.
Vi använder markörmetoden på vårt anslutningsobjekt för att skapa ett markörobjekt (MySQL Connector använder ett objektorienterat programmeringsparadigm, så det finns massor av objekt som ärver egenskaper från överordnade objekt).
Detta markörobjekt har metoder som exekvera, köra (som vi kommer att använda i denna handledning) tillsammans med flera andra användbara metoder.
Om det hjälper kan vi tänka på markörobjektet som ger oss tillgång till den blinkande markören i ett MySQL Server-terminalfönster.
Därefter definierar vi en fråga för att skapa databasen och anropar funktionen:

Alla SQL-frågor som används i denna handledning förklaras i min Introduktion till SQL-handledningsserier, och den fullständiga koden kan hittas i den associerade Jupyter Notebook i detta GitHub-förråd, så jag kommer inte att ge förklaringar av vad SQL-koden gör i detta handledning.
Det här är kanske den enklaste möjliga SQL-frågan. Om du kan läsa engelska kan du förmodligen ta reda på vad den gör!
Att köra create_database-funktionen med argumenten enligt ovan resulterar i att en databas som heter 'skola' skapas på vår server.
Varför heter vår databas "skola"? Nu skulle det kanske vara ett bra tillfälle att titta mer i detalj på exakt vad vi ska implementera i den här handledningen.
Vår databas
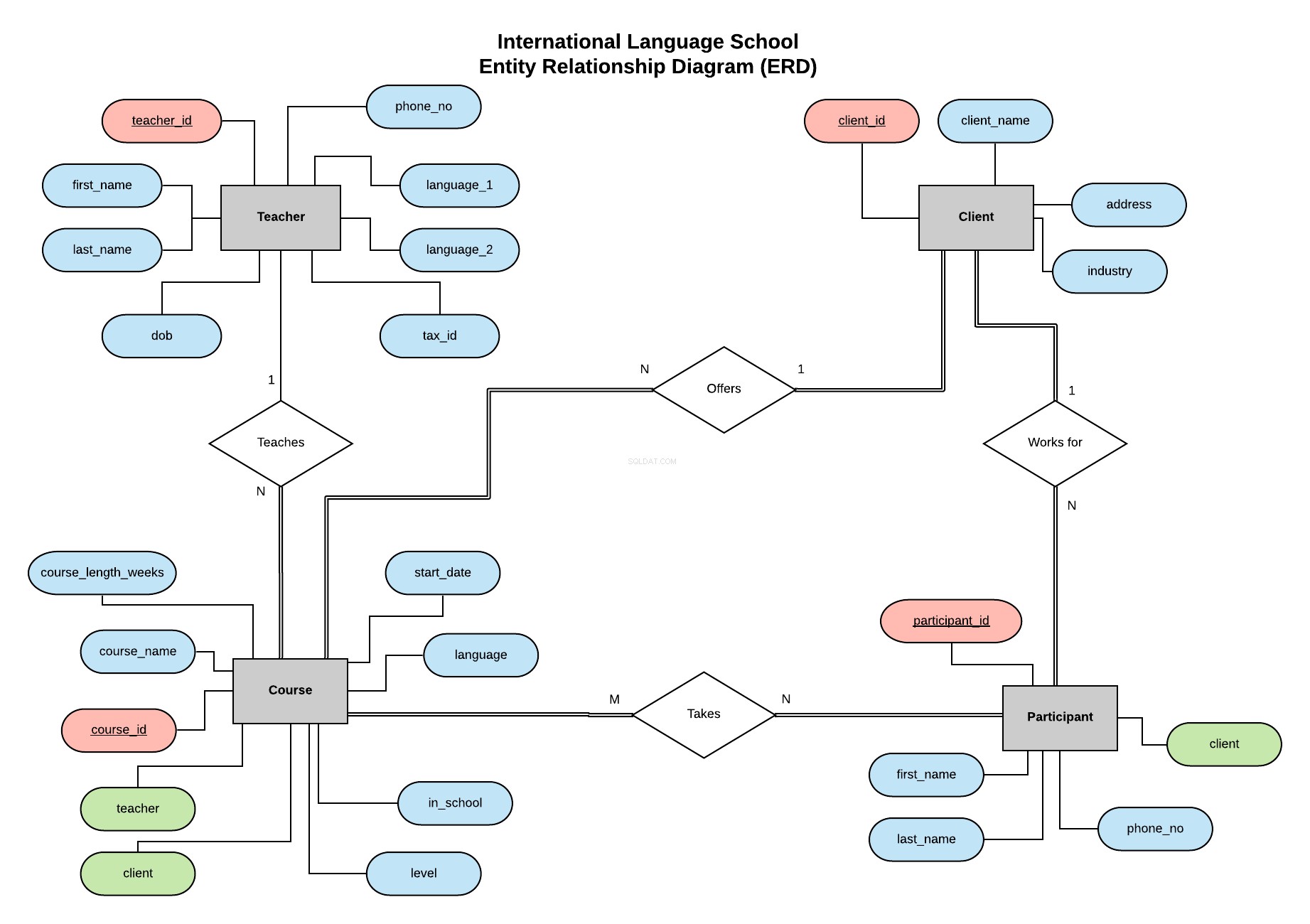
Efter exemplet i min tidigare serie kommer vi att implementera databasen för International Language School - en fiktiv språkutbildningsskola som ger professionella språklektioner till företagskunder.
Detta Entity Relationship Diagram (ERD) beskriver våra enheter (lärare, klient, kurs och deltagare) och definierar relationerna mellan dem.
All information om vad en ERD är och vad du ska tänka på när du skapar en och designar en databas finns i den här artikeln.
Den råa SQL-koden, databaskraven och data för att gå in i databasen finns alla i detta GitHub-förråd, men du kommer att se allt när vi går igenom den här handledningen också.
Ansluta till databasen
Nu när vi har skapat en databas i MySQL Server kan vi modifiera vår create_server_connection funktion för att ansluta direkt till denna databas.
Observera att det är möjligt - faktiskt vanligt - att ha flera databaser på en MySQL-server, så vi vill alltid och automatiskt ansluta till databasen vi är intresserade av.
Vi kan göra så här:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionDetta är exakt samma funktion, men nu tar vi ytterligare ett argument - databasnamnet - och skickar det som ett argument till metoden connect().
Skapa en frågekörningsfunktion
Den sista funktionen vi kommer att skapa (för nu) är en extremt viktig - en query execution funktion. Detta kommer att ta våra SQL-frågor, lagrade i Python som strängar, och skicka dem till metoden cursor.execute() för att exekvera dem på servern.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Den här funktionen är exakt samma som vår create_database-funktion från tidigare, förutom att den använder metoden connection.commit() för att säkerställa att kommandona som beskrivs i våra SQL-frågor implementeras.
Detta kommer att bli vår arbetshästfunktion, som vi kommer att använda (vid sidan av create_db_connection) för att skapa tabeller, upprätta relationer mellan dessa tabeller, fylla tabellerna med data och uppdatera och ta bort poster i vår databas.
Om du är en SQL-expert låter den här funktionen dig utföra alla de komplexa kommandon och frågor du kan ha liggande, direkt från ett Python-skript. Detta kan vara ett mycket kraftfullt verktyg för att hantera dina data.
Skapa tabeller
Nu är vi redo att börja köra SQL-kommandon i vår server och börja bygga vår databas. Det första vi vill göra är att skapa de nödvändiga tabellerna.
Låt oss börja med vårt Lärarbord:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryFörst och främst tilldelar vi vårt SQL-kommando (förklaras i detalj här) till en variabel med ett lämpligt namn.
I det här fallet använder vi Pythons tredubbla citattecken för flerradiga strängar för att lagra vår SQL-fråga, sedan matar vi in den i vår execute_query-funktion för att implementera den.
Observera att denna flerradsformatering enbart är till nytta för människor som läser vår kod. Varken SQL eller Python "bryr sig" om SQL-kommandot är utspritt så här. Så länge syntaxen är korrekt kommer båda språken att acceptera den.
Till förmån för människor som kommer att läsa din kod, men (även om det bara kommer att vara framtiden-du!) är det mycket användbart att göra detta för att göra koden mer läsbar och begriplig.
Detsamma gäller för STORA VERKSAMHETEN av operatorer i SQL. Detta är en allmänt använd konvention som rekommenderas starkt, men den faktiska programvaran som kör koden är skiftlägesokänslig och kommer att behandla "CREATE TABLE teacher" och "create table teacher" som identiska kommandon.

Att köra den här koden ger oss våra framgångsmeddelanden. Vi kan också verifiera detta i MySQL Server Command Line Client:
Bra! Låt oss nu skapa de återstående tabellerna.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)Detta skapar de fyra tabeller som behövs för våra fyra enheter.
Nu vill vi definiera relationerna mellan dem och skapa ytterligare en tabell för att hantera många-till-många-relationen mellan deltagar- och kurstabellerna (se här för mer information).
Vi gör detta på exakt samma sätt:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Nu skapas våra tabeller, tillsammans med lämpliga begränsningar, primärnyckel och främmande nyckelrelationer.
Fylla tabellerna
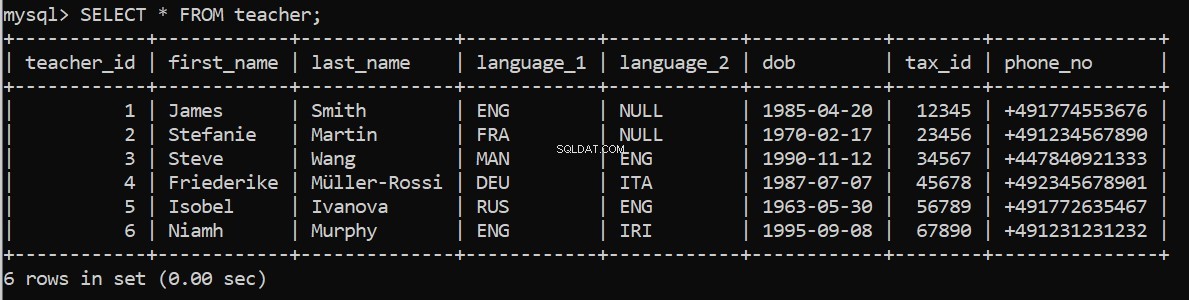
Nästa steg är att lägga till några poster i tabellerna. Återigen använder vi execute_query för att mata in våra befintliga SQL-kommandon till servern. Låt oss återigen börja med Lärartabellen.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)Fungerar det här? Vi kan kontrollera igen i vår MySQL Command Line Client:
Nu för att fylla i de återstående tabellerna.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)Fantastisk! Nu har vi skapat en databas komplett med relationer, begränsningar och poster i MySQL, med inget annat än Python-kommandon.
Vi har gått igenom detta steg för steg för att hålla det begripligt. Men vid det här laget kan du se att allt detta mycket lätt kan skrivas in i ett Python-skript och köras i ett kommando i terminalen. Kraftfulla grejer.
Läser data
Nu har vi en fungerande databas att arbeta med. Som Dataanalytiker kommer du sannolikt att komma i kontakt med befintliga databaser i de organisationer där du arbetar. Det kommer att vara mycket användbart att veta hur man drar ut data från dessa databaser så att de sedan kan matas in i din python-datapipeline. Detta är vad vi ska arbeta med härnäst.
För detta behöver vi ytterligare en funktion, denna gång med cursor.fetchall() istället för cursor.commit(). Med den här funktionen läser vi data från databasen och kommer inte att göra några ändringar.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Återigen, vi kommer att implementera detta på ett mycket liknande sätt som execute_query. Låt oss prova det med en enkel fråga för att se hur det fungerar.
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)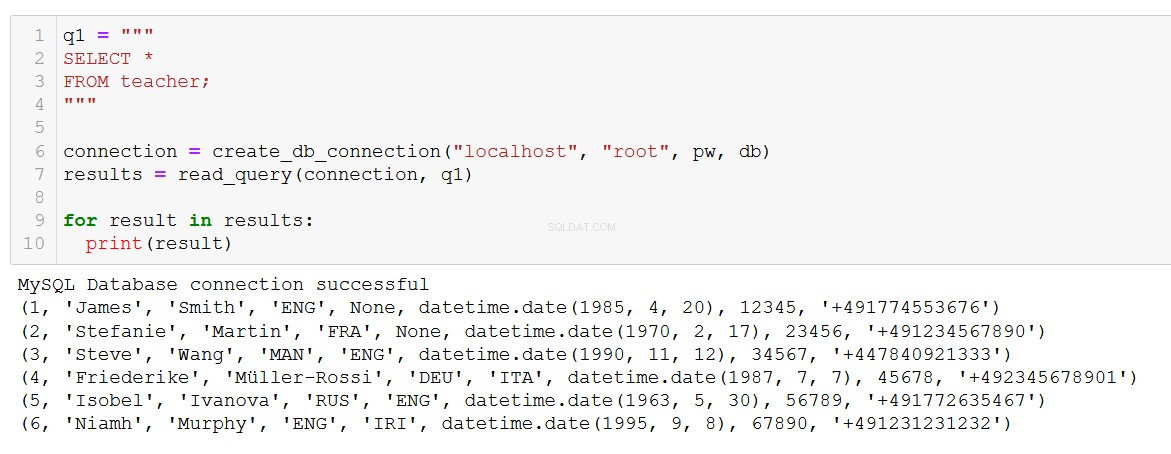
Precis vad vi förväntar oss. Funktionen fungerar också med mer komplexa frågor, som den här som involverar en JOIN på kurs- och klienttabellerna.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)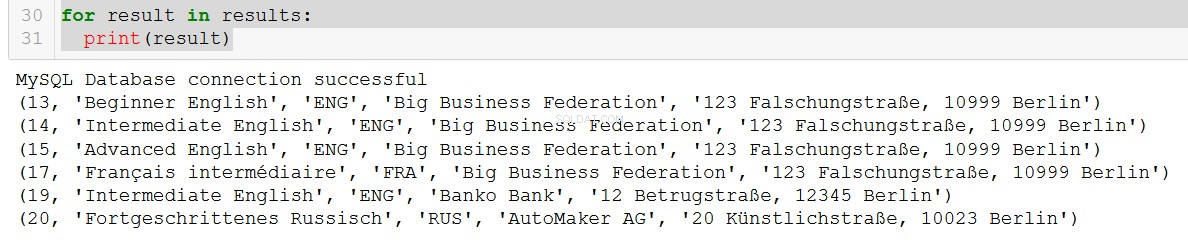
Mycket trevligt.
För våra datapipelines och arbetsflöden i Python kanske vi vill få dessa resultat i olika format för att göra dem mer användbara eller redo för oss att manipulera.
Låt oss gå igenom ett par exempel för att se hur vi kan göra det.
Formatera utdata till en lista
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
Formatera utdata till en lista med listor
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Formatera utdata till en pandas DataFrame
För dataanalytiker som använder Python är pandas vår vackra och pålitliga gamla vän. Det är väldigt enkelt att konvertera utdata från vår databas till en DataFrame, och därifrån är möjligheterna oändliga!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)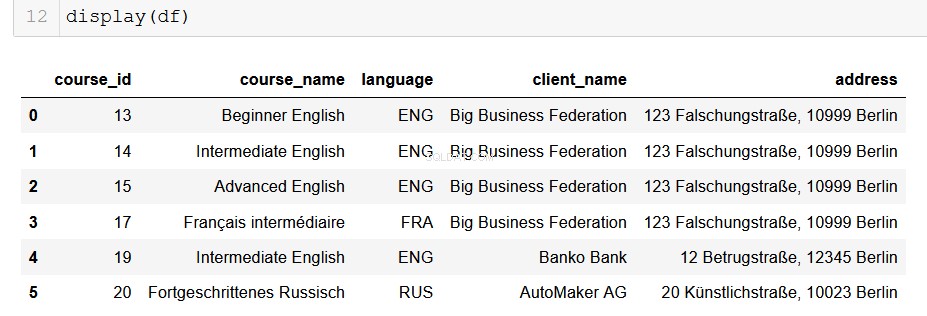
Förhoppningsvis kan du se möjligheterna utvecklas framför dig här. Med bara några rader kod kan vi enkelt extrahera all data vi kan hantera från relationsdatabaserna där den finns och dra in den i våra toppmoderna dataanalyspipelines. Det här är verkligen nyttigt.
Uppdatering av poster
När vi underhåller en databas behöver vi ibland göra ändringar i befintliga poster. I det här avsnittet ska vi titta på hur man gör det.
Låt oss säga att ILS har meddelats att en av dess befintliga kunder, Big Business Federation, flyttar kontor till 23 Fingiertweg, 14534 Berlin. I det här fallet kommer databasadministratören (det är vi!) att behöva göra några ändringar.
Tack och lov kan vi göra detta med vår execute_query-funktion tillsammans med SQL UPDATE-satsen.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Observera att WHERE-satsen är mycket viktig här. Om vi kör den här frågan utan WHERE-satsen kommer alla adresser för alla poster i vår klienttabell att uppdateras till 23 Fingiertweg. Det är så mycket inte vad vi vill göra.
Observera också att vi använde "WHERE client_id =101" i UPDATE-frågan. Det skulle också ha varit möjligt att använda "WHERE client_name ='Big Business Federation'" eller "WHERE address ='123 Falschungstraße, 10999 Berlin'" eller till och med "WHERE address LIKE '%Falschung%'".
Det viktiga är att WHERE-satsen tillåter oss att unikt identifiera posten (eller posterna) vi vill uppdatera.
Ta bort poster
Det är också möjligt att använda vår execute_query-funktion för att radera poster genom att använda DELETE.
När vi använder SQL med relationsdatabaser måste vi vara försiktiga med att använda DELETE-operatorn. Det här är inte Windows, det finns inget "Är du säker på att du vill ta bort detta?" varning pop-up, och det finns ingen återvinningskärl. När vi tar bort något är det verkligen borta.
Med det sagt behöver vi verkligen radera saker ibland. Så låt oss ta en titt på det genom att ta bort en kurs från vår kurstabell.
Låt oss först och främst påminna oss om vilka kurser vi har.
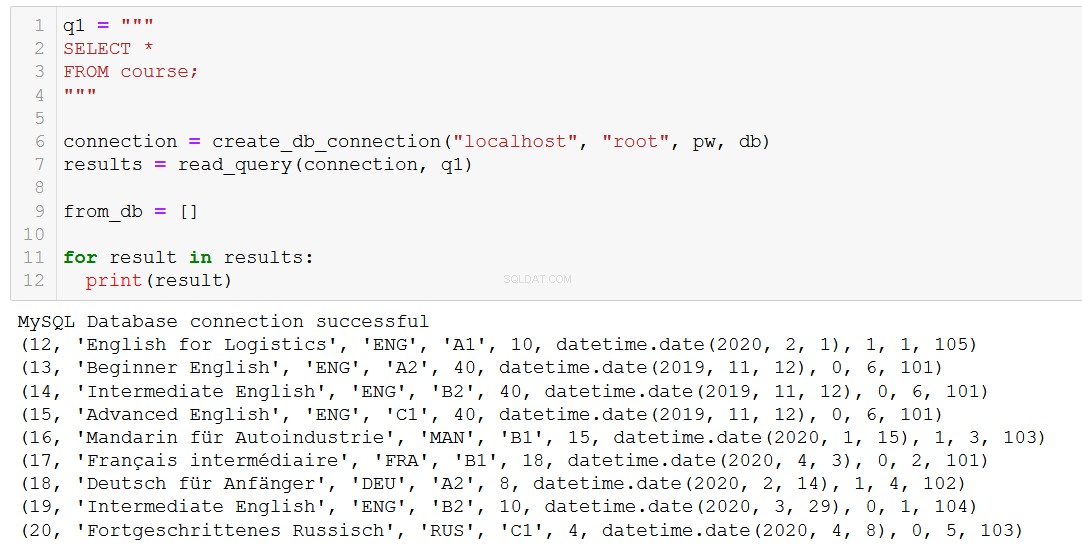
Låt oss säga att kurs 20, 'Fortgeschrittenes Russisch' (det är 'Avancerad ryska' för dig och mig), närmar sig sitt slut, så vi måste ta bort den från vår databas.
I det här skedet kommer du inte att bli alls förvånad över hur vi gör detta - spara SQL-kommandot som en sträng och mata in det i vår arbetshäst execute_query-funktion.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Låt oss kontrollera att det hade den avsedda effekten:
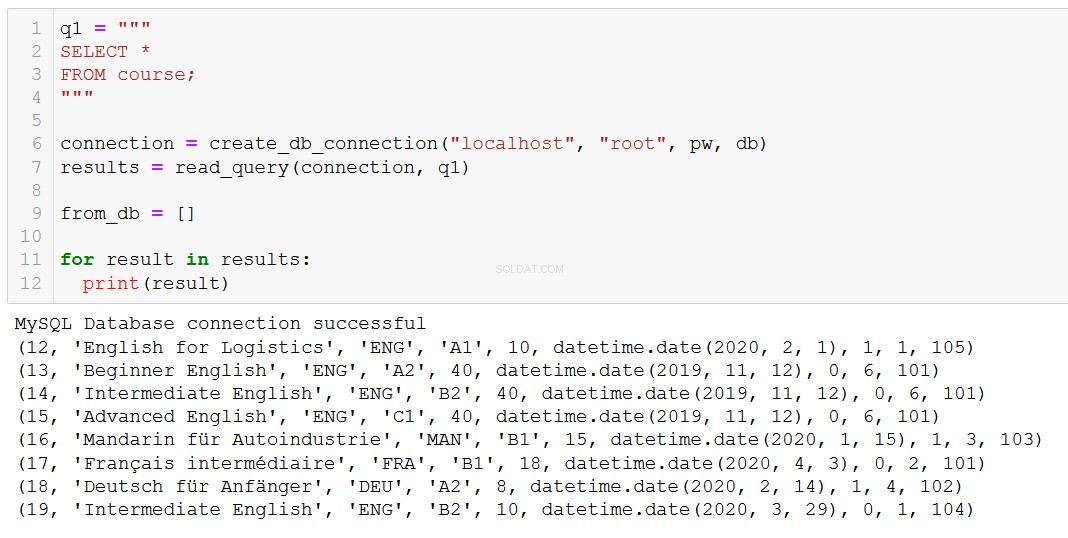
'Advanced Russian' är borta, som vi förväntade oss.
Detta fungerar också med att ta bort hela kolumner med DROP COLUMN och hela tabeller med DROP TABLE-kommandon, men vi kommer inte att täcka dem i den här handledningen.
Varsågod och experimentera med dem, men det spelar ingen roll om du tar bort en kolumn eller tabell från en databas för en fiktiv skola, och det är en bra idé att bli bekväm med dessa kommandon innan du går in i en produktionsmiljö.
Åh CRUD
Vid det här laget kan vi nu slutföra de fyra stora operationerna för beständig datalagring.
Vi har lärt oss hur man:
- Skapa – helt nya databaser, tabeller och poster
- Läs - extrahera data från en databas och lagra dessa data i flera format
- Uppdatera - gör ändringar i befintliga poster i databasen
- Ta bort - ta bort poster som inte längre behövs
Det är fantastiskt användbara saker att kunna göra.
Innan vi avslutar saker här, har vi ytterligare en mycket praktisk färdighet att lära oss.
Skapa poster från listor
Vi såg när vi fyllde i våra tabeller att vi kan använda kommandot SQL INSERT i vår execute_query-funktion för att infoga poster i vår databas.
Med tanke på att vi använder Python för att manipulera vår SQL-databas, skulle det vara användbart att kunna ta en Python-datastruktur (som en lista) och infoga den direkt i vår databas.
Detta kan vara användbart när vi vill lagra loggar över användaraktivitet på en social media-app som vi har skrivit i Python, eller input från användare till en Wiki som vi har byggt, till exempel. Det finns så många möjliga användningsområden för detta som du kan tänka dig.
Den här metoden är också säkrare om vår databas är öppen för våra användare när som helst, eftersom den hjälper till att förhindra SQL Injection-attacker, som kan skada eller till och med förstöra hela vår databas.
För att göra detta kommer vi att skriva en funktion med metoden executemany() istället för den enklare metoden execute() vi har använt hittills.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Nu har vi funktionen, vi behöver definiera ett SQL-kommando ('sql') och en lista som innehåller de värden vi vill lägga in i databasen ('val'). Värdena måste lagras som en lista över tupler, vilket är ett ganska vanligt sätt att lagra data i Python.
För att lägga till två nya lärare till databasen kan vi skriva lite kod så här:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Lägg märke till att i 'sql'-koden använder vi '%s' som platshållare för vårt värde. Likheten med platshållaren '%s' för en sträng i python är bara tillfällig (och ärligt talat mycket förvirrande), vi vill använda '%s' för alla datatyper (strängar, ints, datum, etc) med MySQL Python Anslutning.
Du kan se ett antal frågor på Stackoverflow där någon har blivit förvirrad och försökt använda '%d' platshållare för heltal eftersom de är vana vid att göra detta i Python. Detta kommer inte att fungera här - vi måste använda en '%s' för varje kolumn vi vill lägga till ett värde till.
Funktionen executemany tar sedan varje tuppel i vår "val"-lista och infogar det relevanta värdet för den kolumnen i stället för platshållaren och kör SQL-kommandot för varje tupel som finns i listan.
Detta kan utföras för flera rader med data, så länge de är korrekt formaterade. I vårt exempel kommer vi bara att lägga till två nya lärare, i illustrativt syfte, men i princip kan vi lägga till så många vi vill.
Låt oss köra den här frågan och lägga till lärarna i vår databas.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)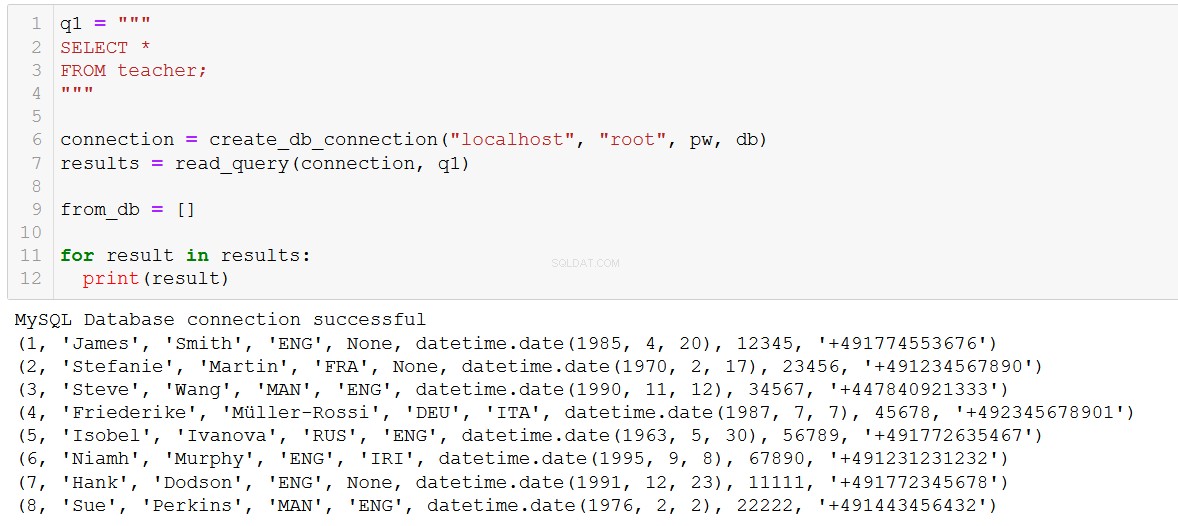
Välkommen till ILS, Hank och Sue!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Slutsats
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you'd like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly - all feedback is warmly received!
