Det bästa scenariot är att du i händelse av ett databasfel har en bra Disaster Recovery Plan (DRP) och en mycket tillgänglig miljö med en automatisk failover-process, men... vad händer om den misslyckas för någon oväntad anledning? Vad händer om du behöver utföra en manuell failover? I den här bloggen kommer vi att dela med oss av några rekommendationer att följa om du behöver göra en backup på din databas.
Verifieringskontroller
Innan du utför någon ändring måste du verifiera några grundläggande saker för att undvika nya problem efter failover-processen.
Replikeringsstatus
Det kan vara möjligt att slavnoden vid feltillfället inte är uppdaterad på grund av ett nätverksfel, hög belastning eller annat problem, så du måste se till att slav har all (eller nästan all) information. Om du har mer än en slavnod bör du också kontrollera vilken som är den mest avancerade noden och välja den till failover.
t.ex.:Låt oss kontrollera replikeringsstatusen i en MariaDB-server.
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)I fallet med PostgreSQL är det lite annorlunda eftersom du måste kontrollera WALs status och jämföra de tillämpade med de hämtade.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Inloggningsuppgifter
Innan du kör failover måste du kontrollera om din applikation/användare kommer att kunna komma åt din nya master med de aktuella referenserna. Om du inte replikerar dina databasanvändare, kanske autentiseringsuppgifterna har ändrats, så du måste uppdatera dem i slavnoderna innan några ändringar.
t.ex.:Du kan fråga användartabellen i mysql-databasen för att kontrollera användaruppgifterna i en MariaDB/MySQL-server:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)I fallet med PostgreSQL kan du använda kommandot '\du' för att känna till rollerna, och du måste också kontrollera konfigurationsfilen pg_hba.conf för att hantera användaråtkomsten (inte autentiseringsuppgifter). Så:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}Och pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustNätverks-/brandväggsåtkomst
Inloggningsuppgifterna är inte det enda möjliga problemet med att komma åt din nya master. Om noden finns i ett annat datacenter, eller om du har en lokal brandvägg för att filtrera trafik, måste du kontrollera om du har tillåtelse att komma åt den eller till och med om du har nätverksvägen för att nå den nya huvudnoden.
t.ex. iptables. Låt oss tillåta trafiken från nätverket 167.124.57.0/24 och kontrollera de nuvarande reglerna efter att ha lagt till det:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationt.ex:rutter. Låt oss anta att din nya huvudnod är i nätverket 10.0.0.0/24, din applikationsserver är i 192.168.100.0/24, och du kan nå fjärrnätverket med 192.168.100.100, så i din applikationsserver lägger du till motsvarande rutt:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Åtgärdspunkter
Efter att ha kontrollerat alla de nämnda punkterna bör du vara redo att vidta åtgärder för att överta din databas.
Ny IP-adress
Eftersom du kommer att marknadsföra en slavnod kommer huvud-IP-adressen att ändras, så du måste ändra den i din applikation eller klientåtkomst.
Att använda en lastbalanserare är ett utmärkt sätt att undvika detta problem/ändring. Efter failover-processen kommer Load Balancer att upptäcka den gamla mastern som offline och (beror på konfigurationen) skicka trafiken till den nya för att skriva på den, så du behöver inte ändra något i din applikation.
t.ex.:Låt oss se ett exempel på en HAProxy-konfiguration:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkI det här fallet, om en nod är nere, kommer HAProxy inte att skicka trafik dit och skicka trafiken endast till den tillgängliga noden.
Konfigurera om slavnoderna
Om du har mer än en slavnod, efter att ha främjat en av dem, måste du konfigurera om resten av slavarna för att ansluta till den nya mastern. Detta kan vara en tidskrävande uppgift, beroende på antalet noder.
Verifiera och konfigurera säkerhetskopiorna
När du har allt på plats (ny master har främjats, slavar omkonfigurerade, applikationsskrivning i den nya mastern), är det viktigt att vidta nödvändiga åtgärder för att förhindra ett nytt problem, så säkerhetskopiering är ett måste i detta steg. Med största sannolikhet hade du en säkerhetskopieringspolicy igång innan incidenten (om inte, måste du ha den med säkerhet), så du måste kontrollera om säkerhetskopieringarna fortfarande körs, annars fungerar de i den nya topologin. Det kan vara möjligt att du körde säkerhetskopiorna på den gamla mastern eller använde slavnoden som är master nu, så du måste kontrollera den för att se till att din säkerhetskopieringspolicy fortfarande fungerar efter ändringarna.
Databasövervakning
När du utför en failover-process är övervakning ett måste före, under och efter processen. Med detta kan du förhindra ett problem innan det blir värre, upptäcka ett oväntat problem under failover, eller till och med veta om något går fel efter det. Du måste till exempel övervaka om din applikation kan komma åt din nya master genom att kontrollera antalet aktiva anslutningar.
Nyckelmått att övervaka
Låt oss se några av de viktigaste mätvärdena att ta hänsyn till:
- replikeringsfördröjning
- replikeringsstatus
- Antal anslutningar
- Nätverksanvändning/fel
- Serverbelastning (CPU, minne, disk)
- Databas- och systemloggar
Återställ
Naturligtvis, om något gick fel måste du kunna rulla tillbaka. Att blockera trafik till den gamla noden och hålla den så isolerad som möjligt kan vara en bra strategi för detta, så i fall du behöver återställa, kommer du att ha den gamla noden tillgänglig. Om återställningen sker efter några minuter, beroende på trafiken, kommer du förmodligen att behöva infoga data för dessa minuter i den gamla mastern, så se till att du också har din temporära masternod tillgänglig och isolerad för att ta denna information och tillämpa den tillbaka .
Automatisk failover-process med ClusterControl
När du ser alla dessa nödvändiga uppgifter för att utföra en failover, vill du antagligen automatisera den och undvika allt detta manuella arbete. För detta kan du dra fördel av några av funktionerna som ClusterControl kan erbjuda dig för olika databastekniker, som automatisk återställning, säkerhetskopiering, användarhantering, övervakning, bland andra funktioner, allt från samma system.
Med ClusterControl kan du verifiera replikeringsstatusen och dess fördröjning, skapa eller ändra autentiseringsuppgifter, känna till nätverks- och värdstatusen och ännu fler verifieringar.
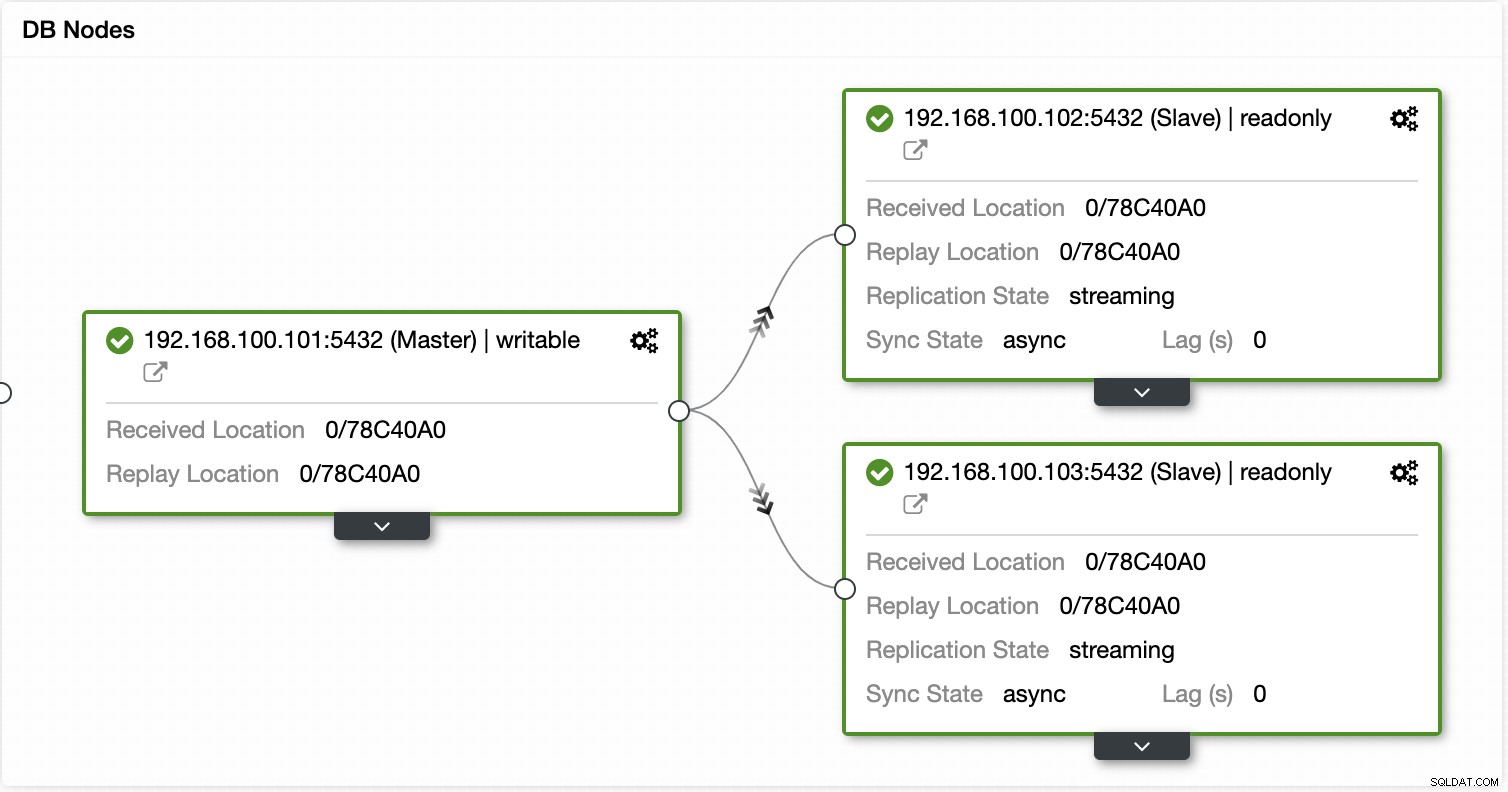
Med ClusterControl kan du också utföra olika kluster- och nodåtgärder, som att främja slav , starta om databas och server, lägg till eller ta bort databasnoder, lägg till eller ta bort belastningsbalanseringsnoder, bygg om en replikeringsslav och mer.
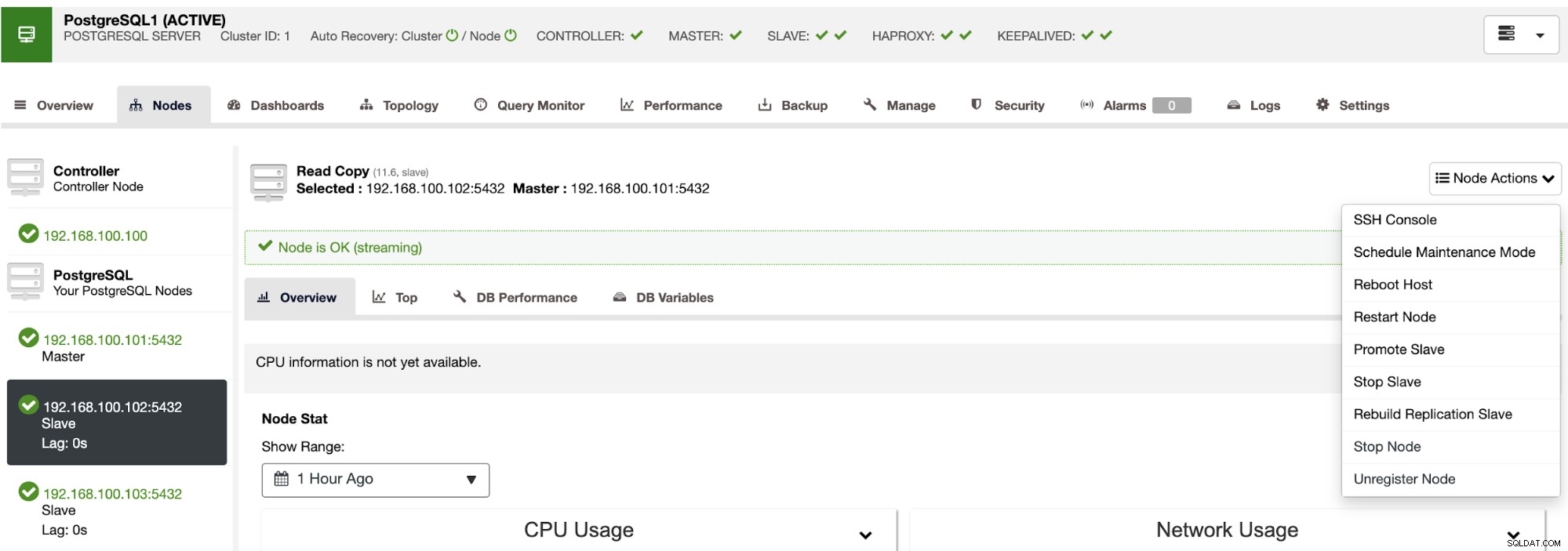
Med dessa åtgärder kan du även återställa din failover om det behövs genom att bygga om och marknadsföra den tidigare mästaren.
ClusterControl har övervaknings- och varningstjänster som hjälper dig att veta vad som händer eller till och med om något hänt tidigare.
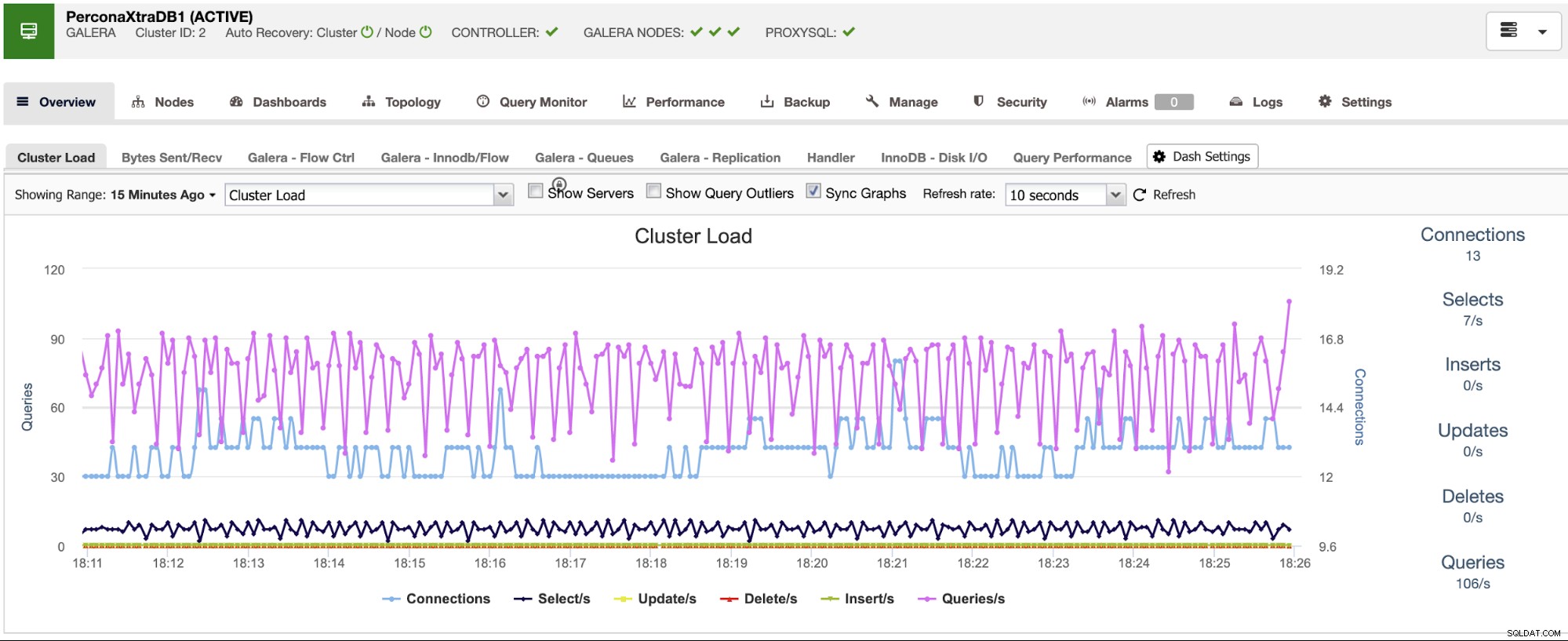
Du kan också använda instrumentpanelssektionen för att få en mer användarvänlig vy om status för dina system.
Slutsats
I händelse av ett misslyckande i huvuddatabasen, vill du ha all information på plats för att vidta nödvändiga åtgärder ASAP. Att ha en bra DRP är nyckeln för att hålla ditt system igång hela (eller nästan hela) tiden. Denna DRP bör innehålla en väldokumenterad failover-process för att ha en acceptabel RTO (Recovery Time Objective) för företaget.