Vi undersöker att migrera en Oracle-databas från en EC2-instans till en hanterad tjänst RDS. I den första av fyra artiklar, "Migrera en Oracle-databas från AWS EC2 till AWS RDS, del 1", skapade vi databasinstanser på EC2 och RDS. I den andra artikeln, "Migrering av en Oracle-databas från AWS EC2 till AWS RDS, del 2", skapade vi en IAM-användare för databasmigrering och skapade även en databastabell för att migrera. Endast i den andra artikeln skapade vi en replikeringsinstans och replikeringsslutpunkter. I den tredje artikeln, "Migrera en Oracle-databas från AWS EC2 till AWS RDS, del 3", skapade vi en migreringsuppgift för att migrera befintliga ändringar. I den här fortsättningsartikeln ska vi migrera pågående ändringar av data. Den här artikeln har följande avsnitt:
- Skapa och köra en replikeringsuppgift för att migrera pågående ändringar
- Lägga till kompletterande loggning
- Lägga till en tabell i en Oracle-databasinstans på EC2
- Lägga till tabelldata
- Utforska den replikerade databastabellen
- Släpp och ladda om data
- Stoppa och starta en uppgift
- Ta bort databaser
- Slutsats
Skapa och köra en replikeringsuppgift för att migrera pågående ändringar
I följande underavsnitt ska vi skapa en uppgift för att replikera pågående förändringar. För att visa pågående replikering ska vi först starta uppgiften och därefter skapa en tabell och lägga till data. Släpp tabellen DVOHRA.WLSLOG såsom visas i figur 1; vi kommer att skapa samma tabell för att visa pågående replikering.

Figur 1: Släpptabell DVOHRA.WLSLOG
Lägga till kompletterande loggning
Databasmigreringstjänst kräver att tilläggsloggning aktiveras för att möjliggöra ändringsdatainsamling (CDC) som används för att replikera pågående ändringar. Kompletterande loggning är processen att lagra information om vilka rader med data i en tabell som har ändrats. Kompletterande loggning lägger till kompletterande eller extra kolumndata i redo-loggfiler när en uppdatering av en tabell utförs. Kolumnerna som har ändrats registreras som kompletterande data i redo-loggfiler tillsammans med en identifierande nyckel, som kan vara primärnyckeln eller unikt index. Om en tabell inte har en primärnyckel eller unikt index, registreras alla skalära kolumner i redo-loggfilerna för att unikt identifiera en rad med data, vilket kan göra om-loggfilerna stora i storlek. Oracle Database stöder följande typer av tilläggsloggning:
- Minimal tilläggsloggning: Endast den minimala mängd data som krävs av LogMiner för DML-ändringarna registreras i gör om loggfiler.
- Nyckelloggning för identifiering av databasnivå: Olika typer av identifieringsnyckelloggning på databasnivå stöds – ALLA, PRIMÄRNYCKEL, UNIK och FOREIGN KEY. Med ALL-nivån registreras alla kolumner (förutom LOBs, Longs och ADTs) i redo-loggfiler. För PRIMARY KEY lagras endast primärnyckelkolumner i redo-loggfiler när en rad som innehåller en primärnyckel uppdateras; det krävs inte att en primärnyckelkolumn uppdateras. Typen FOREIGN KEY lagrar endast främmande nycklar för en rad i redo-loggfiler när någon av de röda loggfilerna uppdateras. Den UNIQUE lagrar endast kolumnerna i en unik sammansatt nyckel eller bitmappsindex när någon kolumn i den unika sammansatta nyckeln eller bitmappsindexet har ändrats.
- Tabellnivå Kompletterande loggning: Anger på tabellnivå vilka kolumner som lagras i redo-loggfiler. Loggning av identifieringsnyckel på tabellnivå stöder samma nivåer som loggning av identifieringsnyckel på databasnivå; ALLA, PRIMÄRNYCKEL, UNIK och UTLANDSNYCKEL. På tabellnivå stöds även användardefinierade kompletterande logggrupper, som låter en användare definiera vilka kolumner som ska loggas extra. De användardefinierade tilläggslogggrupperna kan vara villkorliga eller ovillkorliga.
För pågående replikering måste vi ställa in minimal tilläggsloggning och tilläggsloggning på tabellnivå för ALLA kolumner.
Kör följande programsats i SQL*Plus för att ställa in minimal tilläggsloggning:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
Utgången är som följer:
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; Database altered.
För att hitta statusen för den minimala tilläggsloggningen, kör följande uttalande. Och om utdata har ett SUPPLEME kolumnvärde som JA, aktiveras minimal tilläggsloggning.
SQL> SELECT supplemental_log_data_min FROM v$database; SUPPLEME -------- YES
Inställning av minimal tilläggsloggning och verifiering av status visas i figur 2.
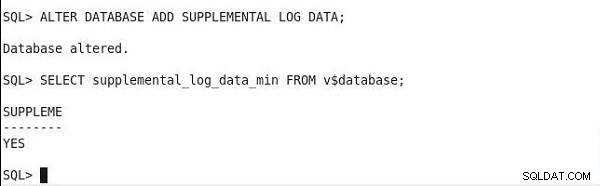
Figur 2: Ställa in och verifiera minimal tilläggsloggning
Vi kommer också att ställa in identifieringsnyckelloggning på tabellnivå när vi lägger till tabell- och tabelldata för att demonstrera pågående replikering efter att uppgiften har startat. Om vi lägger till tabell- och tabelldata innan vi skapar och startar en uppgift - kommer vi inte att kunna demonstrera pågående replikering.
För att skapa en uppgift för pågående replikering, klicka på Skapa uppgift , som visas i figur 3.

Figur 3: Uppgifter>Skapa uppgift
I Skapa uppgift guiden, ange ett uppgiftsnamn och en beskrivning och välj replikeringsinstansen, källslutpunkten och målslutpunkten, som visas i figur 4. Välj Migreringstyp som Migrera befintlig data och replikera pågående ändringar .
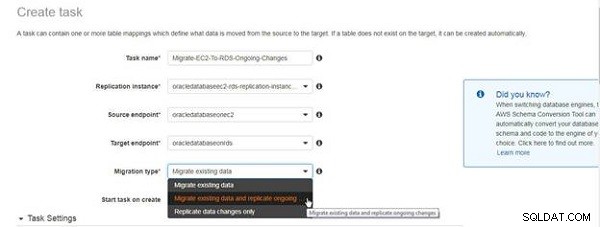
Figur 4: Välja migreringstyp för pågående replikering
Ett meddelande som visas i figur 5 indikerar att tilläggsloggning krävs för att vara aktiverad för pågående replikering. Meddelandet ska inte indikera att tilläggsloggning inte har aktiverats, utan endast som en påminnelse. Vi har redan aktiverat kompletterande loggning. Markera kryssrutan Starta uppgift vid skapa .
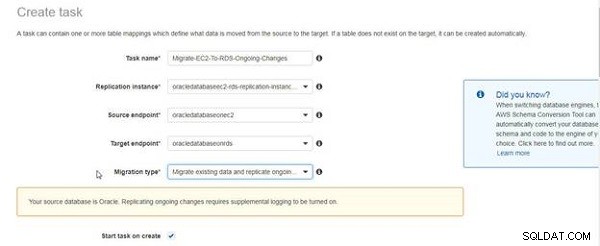
Figur 5: Meddelande om kompletterande loggningskrav för replikering av pågående ändringar
Uppgiftsinställningar är desamma som endast för migrering av befintlig data (se figur 6).
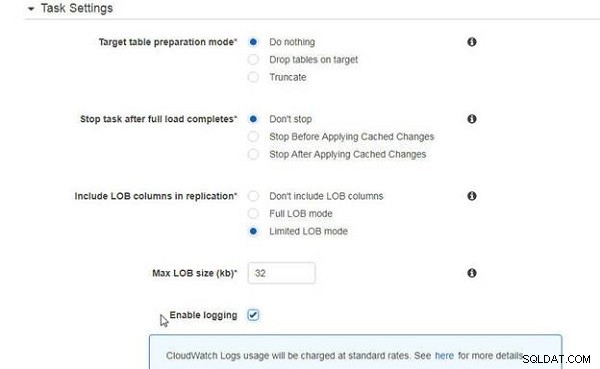
Figur 6: Uppgiftsinställningar
För tabellmappningar krävs minst en urvalsregel. Lägg till en urvalsregel för att inkludera alla tabeller i DVOHRA tabell, som visas i figur 7.
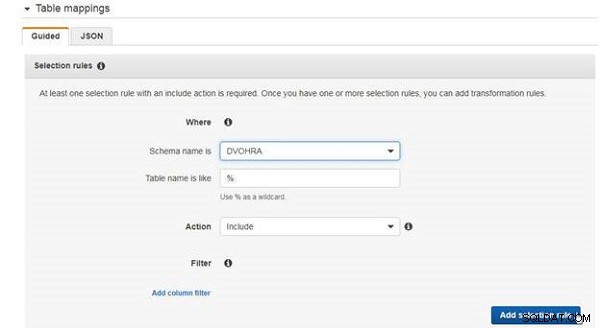
Figur 7: Lägga till en urvalsregel
Den tillagda urvalsregeln visas i figur 8.
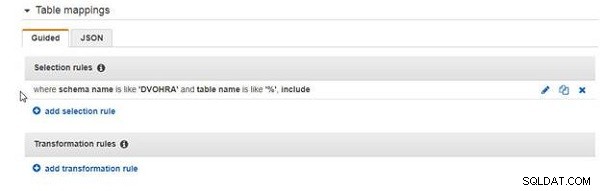
Figur 8: Urvalsregel
Klicka på Skapa uppgift för att skapa uppgiften, som visas i figur 9.
Figur 9: Skapa uppgift
En ny uppgift läggs till med statusen Skapar , som visas i figur 10.

Figur 10: Uppgift tillagd med status Skapar
När urvals- och omvandlingsreglerna för alla befintliga data har tillämpats och data migrerats, blir aktivitetsstatusen Laddning klar, replikering pågår (se figur 11).

Figur 11: Laddning klar, replikering pågår
Tabellstatistik fliken visar inga tabeller som har migrerats eller replikerats, som visas i figur 12.
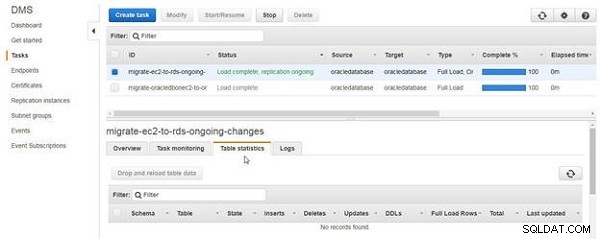
Figur 12: Tabellstatistik
För att utforska CloudWatch-loggarna, klicka på Loggar fliken och klicka på länken, som visas i figur 13.
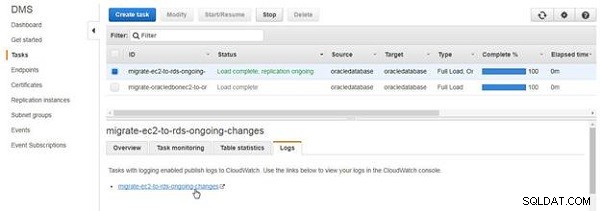
Figur 13: Loggar
CloudWatch-loggarna visas, som visas i figur 14. Den sista posten i loggarna handlar om att starta replikering. Den pågående replikeringsuppgiften avslutas inte efter laddning av befintlig data, om någon, utan fortsätter att köras.
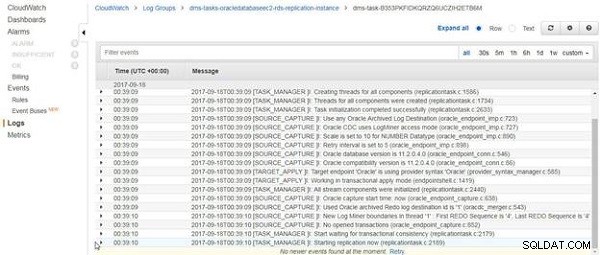
Figur 14: CloudWatch-loggar
Lägga till en tabell i en Oracle-databasinstans på EC2
Skapa sedan en tabell och lägg till tabelldata för att visa pågående replikering. Kör följande två satser tillsammans så att tilläggsloggning på tabellnivå ställs in när tabellen skapas. Ändra skriptet för att göra schemat annorlunda.
CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY, category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns;
Den kompletterande loggningen på tabellnivå ställs in när tabellen skapas.
SQL> CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY,category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns; Table created. SQL> Table altered.
Utdata visas i SQL*Plus i figur 15.
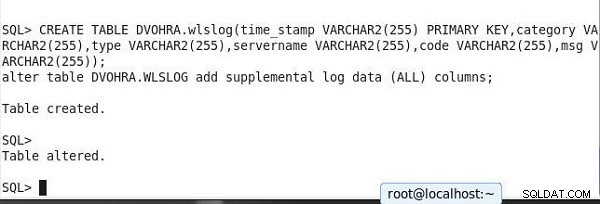
Figur 15: Skapa tabell och ställa in tilläggsloggning
Än så länge har vi bara skapat tabellen och inte lagt till någon tabelldata. DDL för tabellen migreras, vilket framgår av tabellstatistiken i figur 16.
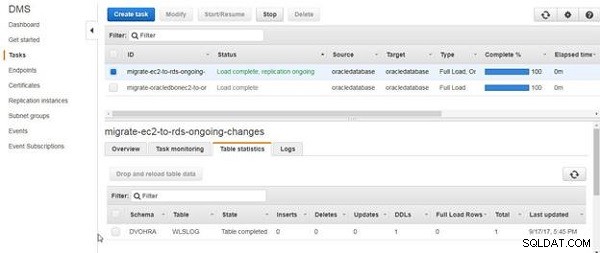
Figur 16: DDL:er för tabellmigrerade
Lägga till tabelldata
Kör sedan följande SQL-skript för att lägga till data till den skapade tabellen. Ändra skriptet för att göra schemat annorlunda.
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:16-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000365','Server
state changed to STANDBY');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:17-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to STARTING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:18-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to ADMIN');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:19-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RESUMING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:20-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000361','Started WebLogic
AdminServer');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:21-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RUNNING');
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
Kör sedan Commit-satsen.
SQL> COMMIT; Commit complete.
Utforska den replikerade databastabellen
Tabellstatistiken visar Infogar som antalet rader med data som lagts till, som visas i figur 17.
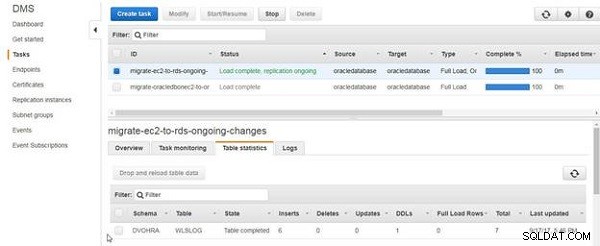
Figur 17: Tabellstatistiklista 6 Inlägg
Uppgiften fortsätter att köras efter replikering av pågående ändringar. Lägg till ytterligare en rad med data.
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:22-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000360','Server
started in RUNNING mode');
1 row created.
SQL> COMMIT;
Commit complete.
SQL>
Klicka på Uppdatera data från servern, som visas i figur 18.
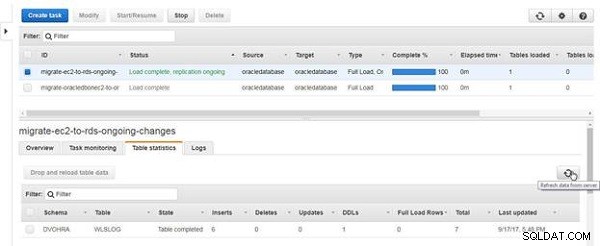
Figur 18: Uppdatera data från servern
Det totala antalet inlägg i tabellstatistik blir 7, som visas i figur 19.
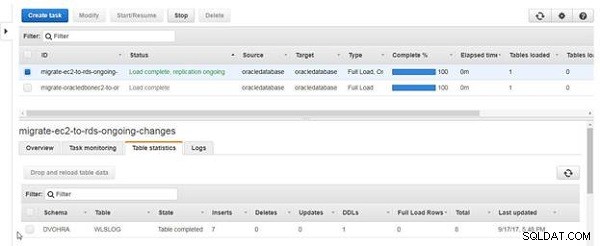
Figur 19: Tabellstatistik med infogar som 7
Släpp och ladda om data
Om du vill släppa och ladda om tabelldata klickar du på Släpp och ladda om tabelldata , som visas i figur 20.
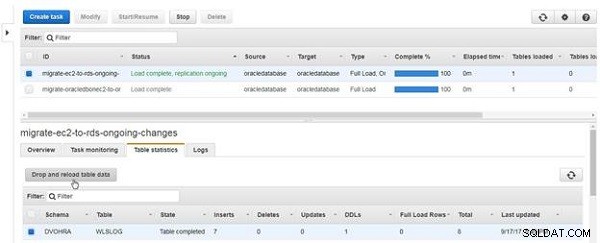
Figur 20: Släpp och ladda om tabelldata
Klicka på Uppdatera data från server (se figur 21).
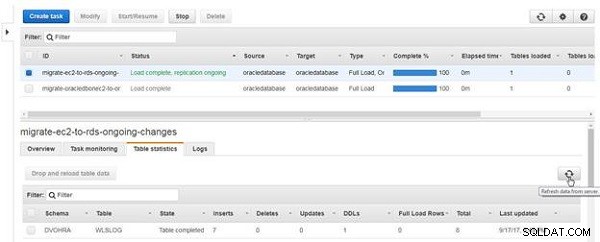
Figur 21: Uppdatera data från servern
Ikonen och State kolumnen för tabellen indikerar att tabellen laddas om, som visas i figur 22.
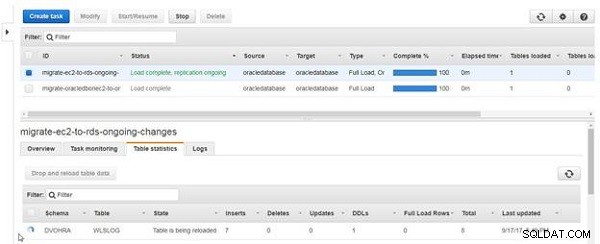
Figur 22: Tabellen laddas om
När tabellåterladdningen har slutförts blir kolumnen tabellstatus Tabell färdig , som visas i figur 23. Efter att ha laddat om tabelldata, Raderna för full belastning visar värdet 7 och Inserts är 0 eftersom en omladdning inte är pågående replikering, utan en full laddning.
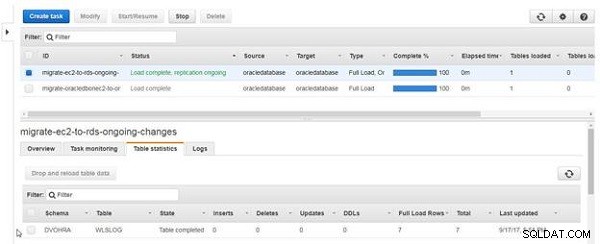
Figur 23: Omladdning av tabell slutförd
Eftersom tabelldata släpps och laddas om och källtabelldata inte har ändrats, innehåller CloudWatch-loggarna ett meddelande "Vissa ändringar från källdatabasen hade ingen inverkan när de tillämpades på måldatabasen.", som visas i figur 24.
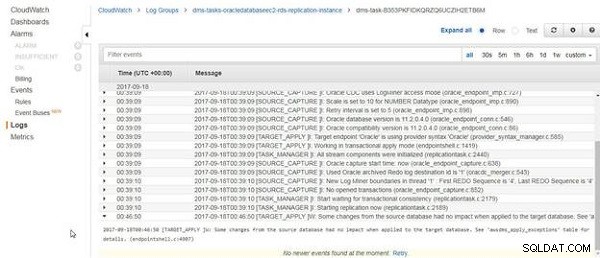
Figur 24: Vissa ändringar från källdatabasen hade ingen inverkan när de tillämpades på måldatabasen
När du laddar om DVOHRA.wlslog tabell har slutförts, meddelandet "Ladda klar för tabellen DVOHRA.wlslog. 7 rader mottagna” visas, som visas i figur 25.
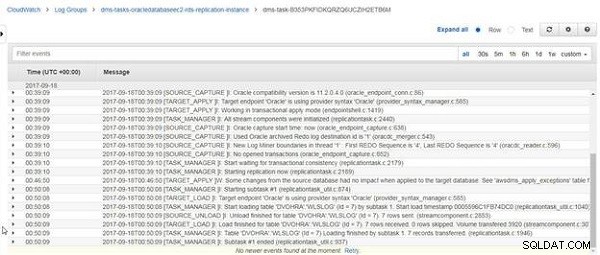
Figur 25: CloudWatch-loggmeddelande för laddning har slutförts
Stoppa och starta en uppgift
En uppgift av den typ som inkluderar pågående replikering slutar inte av sig själv om inte ett fel uppstår. För att stoppa uppgiften klickar du på Stopp (se figur 26).
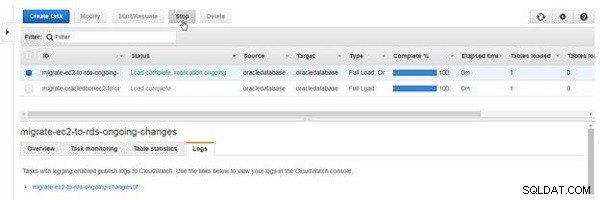
Figur 26: Stoppa en uppgift
I Stoppuppgift klickar du på Stopp , som visas i figur 27.
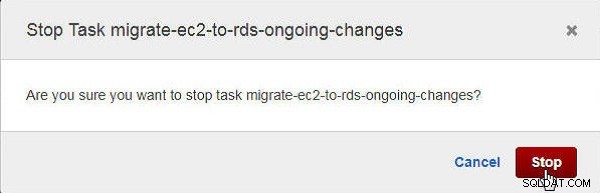
Figur 27: Bekräftelsedialog för att stoppa en uppgift
Aktivitetsstatusen blir Stoppar , som visas i figur 28.
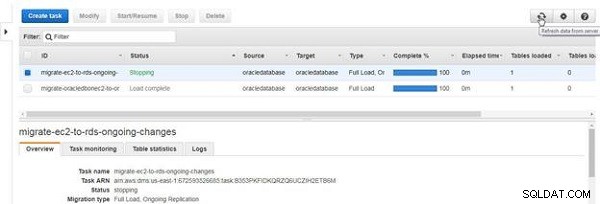
Figur 28: Stoppa en uppgift
När en uppgift stoppas blir statusen Stoppad , som visas i figur 29.
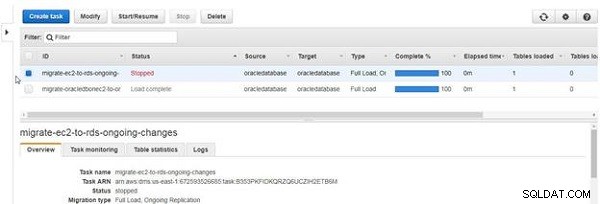
Figur 29: Uppgift stoppad
För att starta en stoppad uppgift, klicka på Starta/Återuppta , som visas i figur 30.
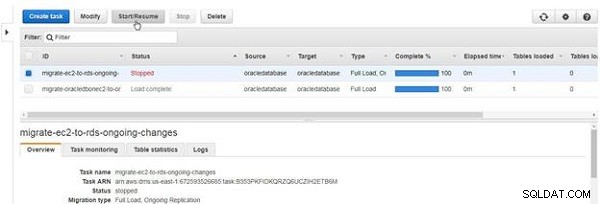
Figur 30: Starta eller återuppta en uppgift
I Starta uppgift klickar du på Start för att starta uppgiften från den stoppade punkten (se figur 31). Det andra alternativet är att starta om uppgiften.
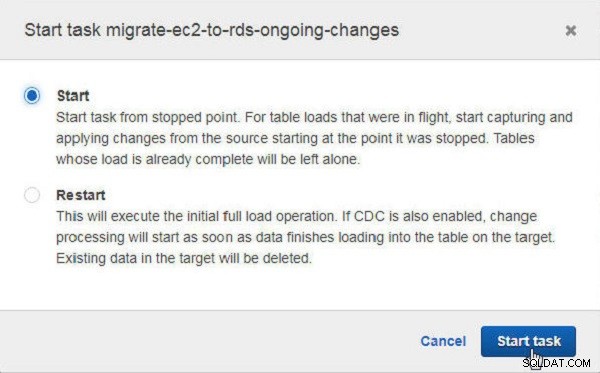
Figur 31: Starta uppgift efter stopp
Aktivitetsstatusen blir Startar , som visas i figur 32.

Figur 32: Starta en uppgift
När migreringen av befintliga data har slutförts fortsätter uppgiften att köras med statusen Laddning klar, replikering pågår , som visas i figur 33.

Figur 33: Inläsningen är klar, replikering pågår
Ta bort databaser
RDS DB-instansen kan raderas med Instansåtgärder>Ta bort kommando. Oracle-databasen på EC2-instansen kan stoppas med Actions>Instance State>Stop , som visas i figur 34.

Figur 34: Stoppar EC2-instans
Slutsats
I fyra artiklar diskuterade vi migrering av en Oracle-databas från AWS EC2 till AWS RDS.