Två allvarliga säkerhetsbrister (kodnamnet Meltdown och Spectre) avslöjades för ett par veckor sedan. Inledande tester antydde att prestandapåverkan av begränsningar (läggs till i kärnan) kan vara upp till ~30 % för vissa arbetsbelastningar, beroende på syscallingshastigheten.
Dessa tidiga uppskattningar var tvungna att göras snabbt och baserades därför på begränsade mängder tester. Dessutom har korrigeringarna i kärnan utvecklats och förbättrats med tiden, och vi fick nu även retpoline som bör adressera Spectre v2. Det här inlägget presenterar data från mer grundliga tester, förhoppningsvis ger mer tillförlitliga uppskattningar för typiska PostgreSQL-arbetsbelastningar.
Jämfört med den tidiga bedömningen av Meltdown-fixar som Simon publicerade den 10 januari, är data som presenteras i det här inlägget mer detaljerade men i allmänhet matchar resultaten som presenteras i det inlägget.
Det här inlägget är fokuserat på PostgreSQL-arbetsbelastningar, och även om det kan vara användbart för andra system med höga syscall-/kontextväxlingshastigheter, är det verkligen inte universellt tillämpligt på något sätt. Om du är intresserad av en mer allmän förklaring av sårbarheterna och konsekvensbedömningen publicerade Brendan Gregg en utmärkt KPTI/KAISER Meltdown Initial Performance Regressions-artikel för ett par dagar sedan. Egentligen kan det vara bra att läsa den först och sedan fortsätta med det här inlägget.
Obs! Det här inlägget är inte menat att avskräcka dig från att installera korrigeringarna, utan för att ge dig en uppfattning om hur prestandan påverkas. Du bör installera alla korrigeringar så att din miljö är säker, och använd det här inlägget för att avgöra om du kan behöva uppgradera hårdvara etc.
Vilka tester kommer vi att göra?
Vi kommer att titta på två vanliga grundläggande arbetsbelastningstyper – OLTP (små enkla transaktioner) och OLAP (komplexa frågor som bearbetar stora mängder data). De flesta PostgreSQL-system kan modelleras som en blandning av dessa två arbetsbelastningstyper.
För OLTP använde vi pgbench, ett välkänt benchmarkingverktyg med PostgreSQL. Vi testade båda i skrivskyddad (-S ) och läs-skriv (-N ) lägen, med tre olika skalor – passar in i shared_buffers, i RAM och större än RAM.
För OLAP-fallet använde vi dbt-3 benchmark, som är ganska nära TPC-H, med två olika datastorlekar – 10 GB som passar in i RAM och 50 GB som är större än RAM (med tanke på index etc.).
Alla de presenterade siffrorna kommer från en server med 2x Xeon E5-2620v4, 64GB RAM och Intel SSD 750 (400GB). Systemet körde Gentoo med kärnan 4.15.3, kompilerad med GCC 7.3 (behövs för att aktivera hela retpoline fixera). Samma tester utfördes även på ett äldre/mindre system med i5-2500k CPU, 8GB RAM och 6x Intel S3700 SSD (i RAID-0). Men beteendet och slutsatserna är i stort sett desamma, så vi kommer inte att presentera data här.
Som vanligt finns kompletta skript/resultat för båda systemen tillgängliga på github.
Det här inlägget handlar om prestandapåverkan av begränsningen, så låt oss inte fokusera på absoluta siffror utan istället titta på prestanda i förhållande till oparpat system (utan kärnreduceringarna). Alla diagram i OLTP-sektionen visas
(throughput with patches) / (throughput without patches)
Vi förväntar oss siffror mellan 0 % och 100 %, med högre värden bättre (lägre effekt av begränsningar), 100 % betyder "ingen påverkan."
Obs! Y-axeln börjar på 75 % för att göra skillnaderna mer synliga.
OLTP / skrivskyddad
Låt oss först se resultat för skrivskyddad pgbench, exekveras av detta kommando
pgbench -n -c 16 -j 16 -S -T 1800 test
och illustreras av följande diagram:
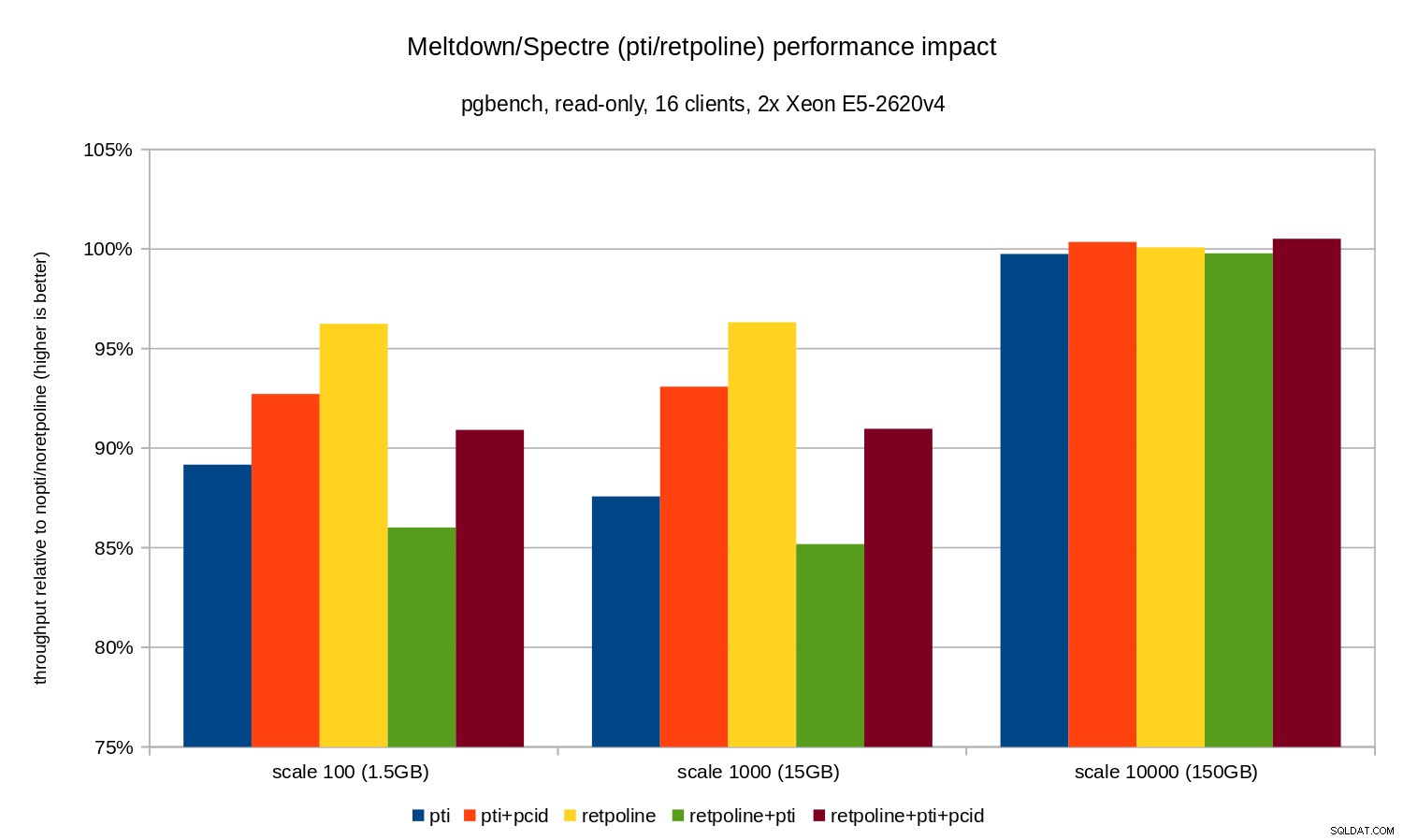
Som du kan se påverkas prestanda av pti för skalor som passar in i minnet är ungefär 10-12 % och nästan omätbar när arbetsbelastningen blir I/O-bunden. Dessutom reduceras regressionen avsevärt (eller försvinner helt) när pcid är aktiverad. Detta stämmer överens med påståendet att PCID nu är en kritisk prestanda/säkerhetsfunktion på x86. Effekten av retpoline är mycket mindre – mindre än 4 % i värsta fall, vilket lätt kan bero på buller.
OLTP / läs-skriv
Läs- och skrivtesterna utfördes av en pgbench kommando som liknar detta:
pgbench -n -c 16 -j 16 -N -T 3600 test
Varaktigheten var tillräckligt lång för att täcka flera kontrollpunkter och -N användes för att eliminera låskonflikter på rader i den (liten) grentabellen. Den relativa prestandan illustreras av detta diagram:
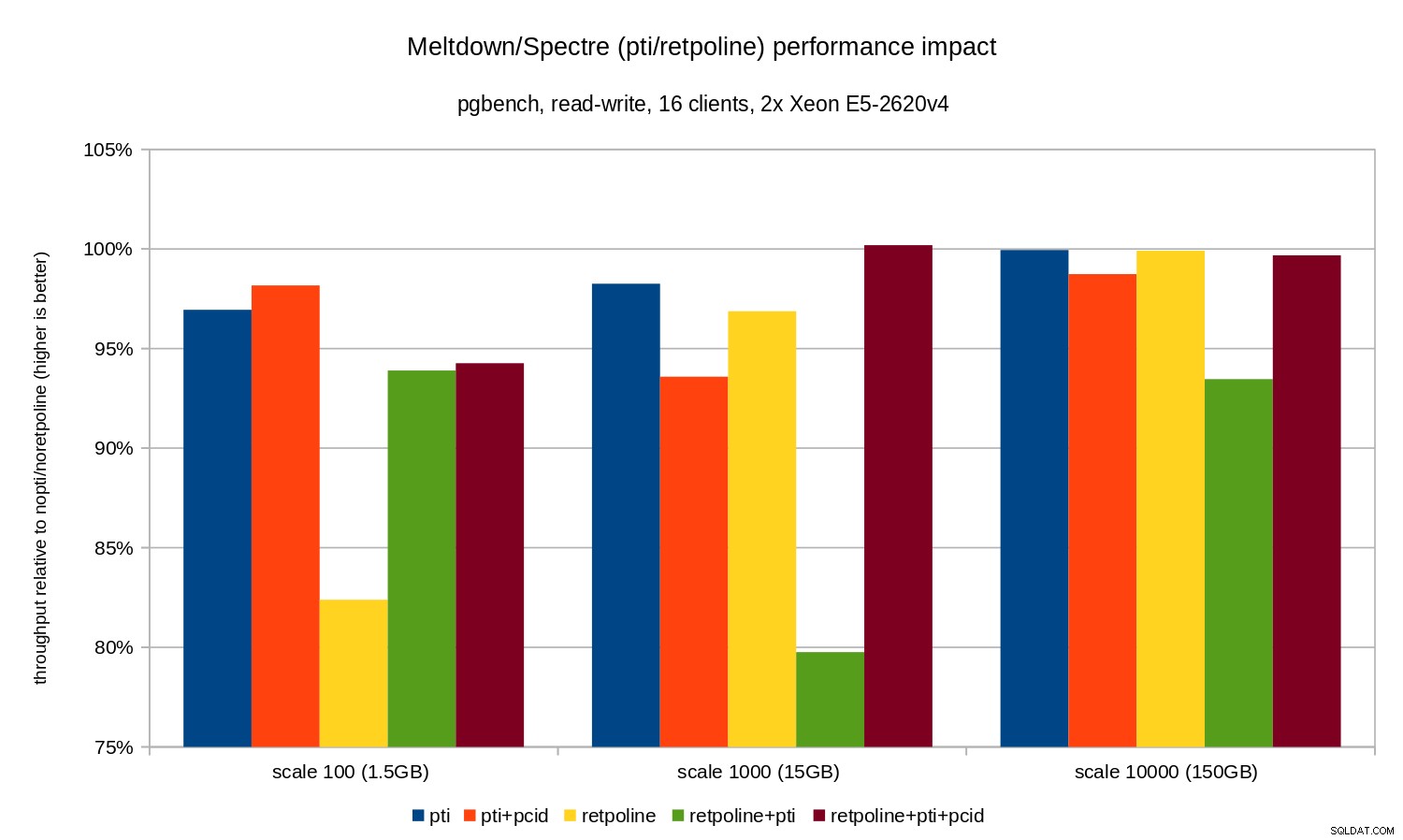
Regressionerna är lite mindre än i det skrivskyddade fallet – mindre än 8 % utan pcid och mindre än 3 % med pcid aktiverad. Detta är en naturlig konsekvens av att spendera mer tid på att utföra I/O medan du skriver data till WAL, tömning av modifierade buffertar under checkpoint etc.
Det finns dock två konstiga bitar. För det första, effekten av retpoline är oväntat stor (nära 20 %) för skala 100, och samma sak hände för retpoline+pti på skala 1000. Orsakerna är inte helt klara och kommer att kräva ytterligare utredning.
OLAP
Analysarbetsbelastningen modellerades av dbt-3 benchmark. Låt oss först titta på resultat i skala 10 GB, vilket passar in i RAM helt och hållet (inklusive alla index etc.). På samma sätt som OLTP är vi inte riktigt intresserade av absoluta tal, vilket i det här fallet skulle vara varaktigheten för individuella frågor. Istället kommer vi att titta på avmattning jämfört med nopti/noretpoline , det vill säga:
(duration without patches) / (duration with patches)
Om vi antar att begränsningarna leder till avmattning får vi värden mellan 0 % och 100 % där 100 % betyder "ingen påverkan". Resultaten ser ut så här:
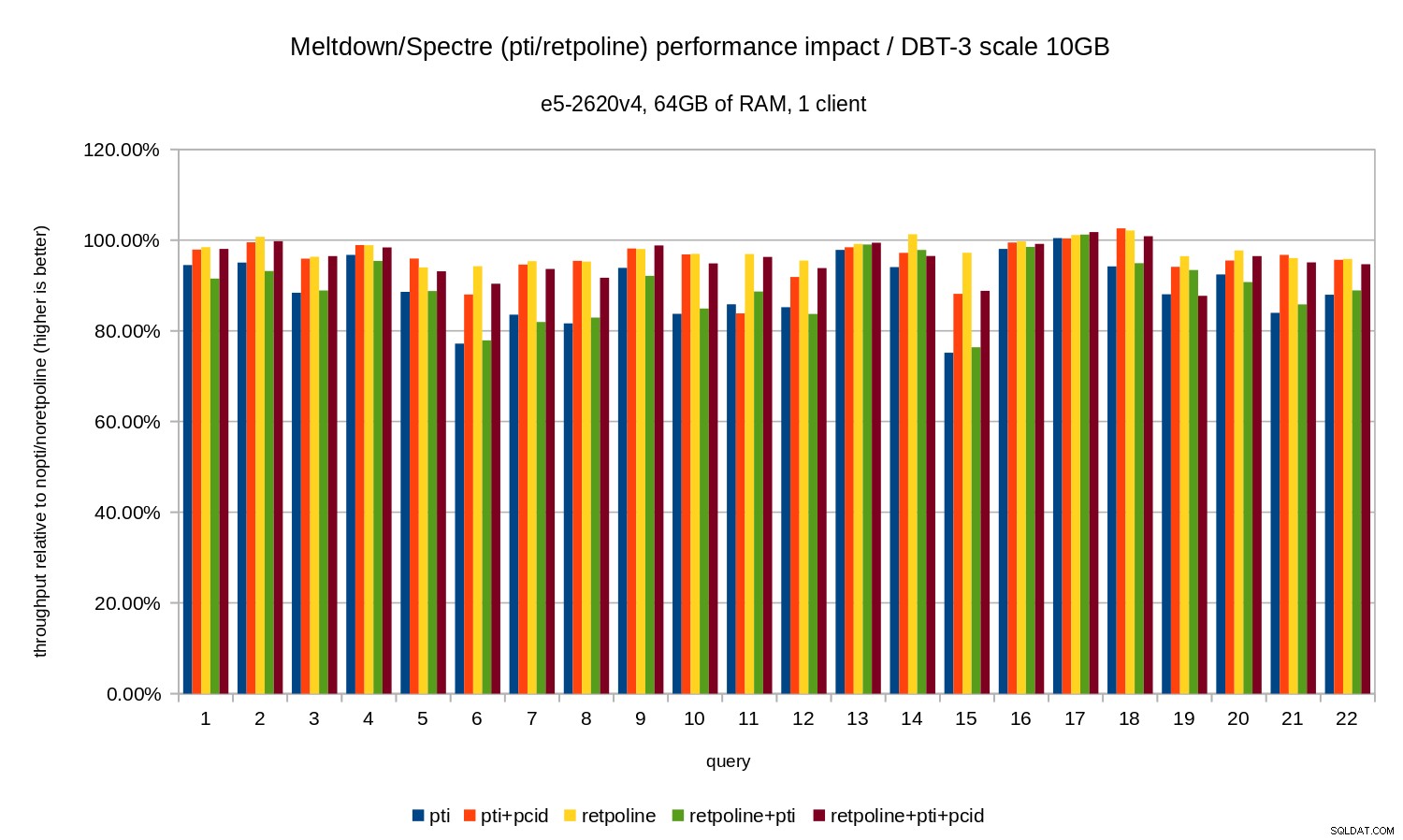
Det vill säga utan pcid regressionen är vanligtvis i intervallet 10-20 %, beroende på frågan. Och med pcid regressionen sjunker till mindre än 5 % (och i allmänhet nära 0 %). Återigen bekräftar detta vikten av pcid funktion.
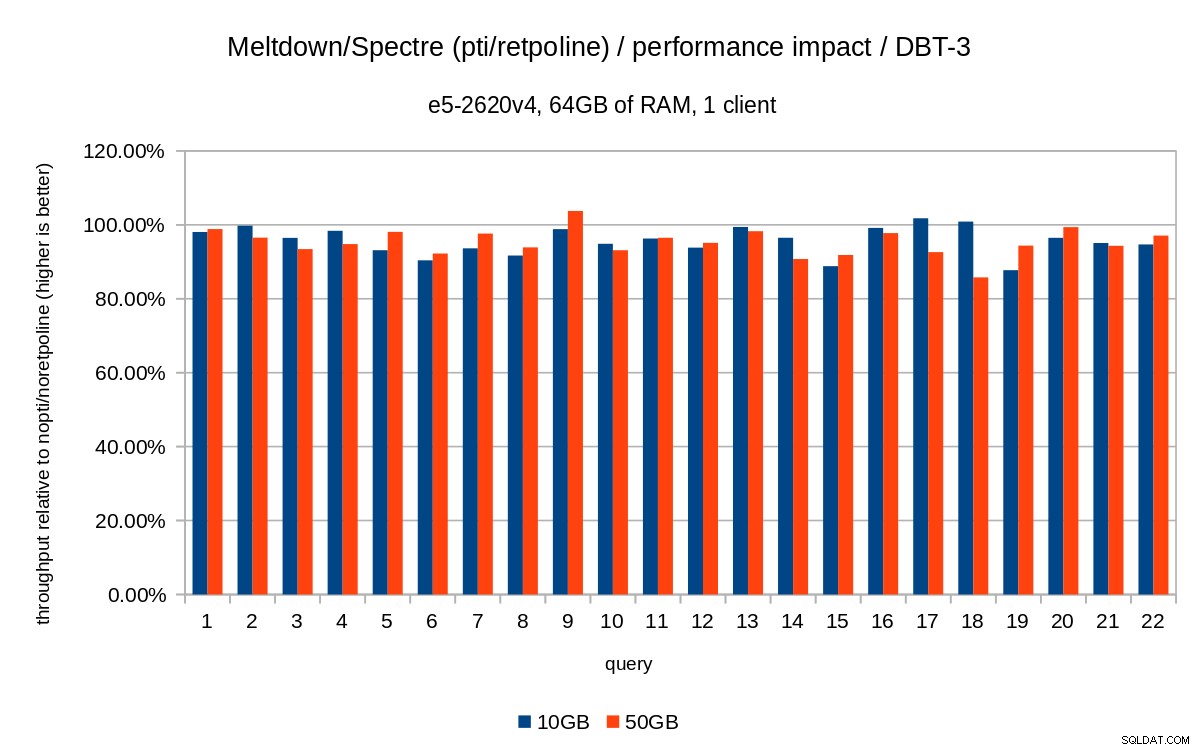
För datauppsättningen på 50 GB (vilket är ungefär 120 GB med alla index etc.) ser effekten ut så här:
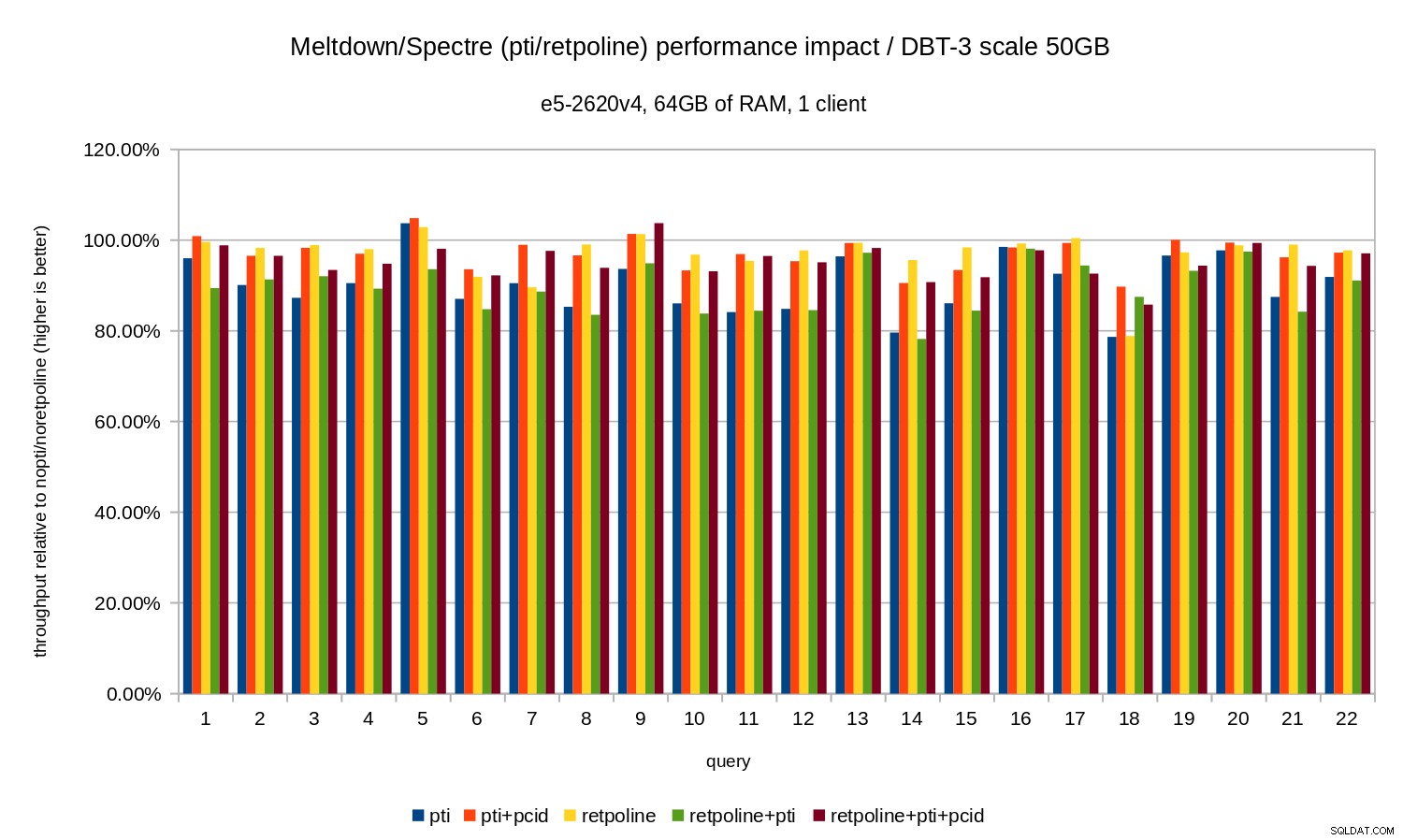
Så precis som i fallet med 10 GB är regressionerna under 20 % och pcid minskar dem avsevärt – nära 0 % i de flesta fall.
De tidigare diagrammen är lite röriga – det finns 22 frågor och 5 dataserier, vilket är lite för mycket för ett enda diagram. Så här är ett diagram som visar effekten endast för alla tre funktionerna (pti , pcid och retpoline ), för båda datamängdsstorlekarna.
Slutsats
För att kort sammanfatta resultaten:
retpolinehar mycket liten prestandapåverkan- OLTP – regressionen är ungefär 10-15 % utan
pcid, och cirka 1-5 % medpcid. - OLAP – regressionen är upp till 20 % utan
pcid, och cirka 1-5 % medpcid. - För I/O-bundna arbetsbelastningar (t.ex. OLTP med den största datamängden) har Meltdown försumbar effekt.
Effekten verkar vara mycket lägre än vad de initiala uppskattningarna antyder (30 %), åtminstone för de testade arbetsbelastningarna. Många system arbetar med 70-80 % CPU under högsäsong, och de 30 % skulle helt mätta CPU-kapaciteten. Men i praktiken verkar effekten vara under 5 %, åtminstone när pcid alternativet används.
Missförstå mig inte, 5% minskning är fortfarande en allvarlig regression. Det är verkligen något vi skulle bry oss om under utvecklingen av PostgreSQL, t.ex. när man utvärderar effekten av föreslagna patchar. Men det är något som befintliga system borde hantera bra – om 5 % ökning i CPU-användning får ditt system att överträffa, har du problem även utan Meltdown/Spectre.
Uppenbarligen är detta inte slutet på Meltdown/Spectre-fixar. Kärnutvecklare arbetar fortfarande med att förbättra skydden och lägga till nya, och Intel och andra CPU-tillverkare arbetar med mikrokoduppdateringar. Och det är inte som att vi känner till alla möjliga varianter av sårbarheterna, eftersom forskare lyckades hitta nya varianter av attackerna.
Så det kommer mer att komma och det ska bli intressant att se vilken inverkan på prestandan kommer att bli.