Alla moderna databassystem stöder en Query Optimizer-modul för att automatiskt identifiera den mest effektiva strategin för exekvering av SQL-frågor. Den effektiva strategin kallas "Plan" och den mäts i termer av kostnad som är direkt proportionell mot "Frågeutförande/svarstid". Planen representeras i form av ett trädutdata från Query Optimizer. Planträdsnoderna kan huvudsakligen delas in i följande tre kategorier:
- Skanna noder :Som förklarats i min tidigare blogg "En översikt över de olika skanningsmetoderna i PostgreSQL", indikerar det hur en bastabelldata behöver hämtas.
- Gå med noder :Som förklarats i min tidigare blogg "En översikt över JOIN-metoderna i PostgreSQL", indikerar det hur två tabeller måste sammanfogas för att få resultatet av två tabeller.
- Materialiseringsnoder :Kallas även som hjälpnoder. De tidigare två typerna av noder var relaterade till hur man hämtar data från en bastabell och hur man sammanfogar data som hämtats från två tabeller. Noderna i denna kategori appliceras ovanpå data som hämtas för att ytterligare analysera eller förbereda rapport, etc t.ex. Sortering av data, aggregat av data, etc.
Tänk på ett enkelt frågeexempel som...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Anta att en plan genereras som motsvarar frågan enligt nedan:
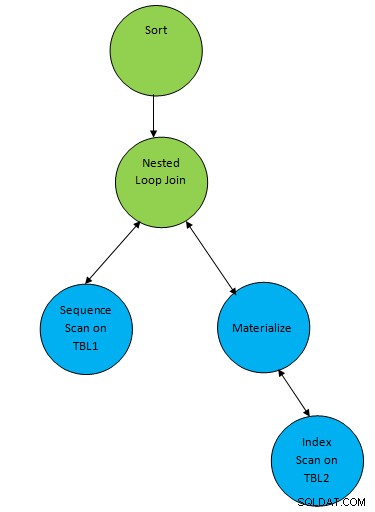
Så här läggs en hjälpnod "Sortera" till ovanpå resultatet av join för att sortera data i önskad ordning.
Några av hjälpnoderna som genereras av PostgreSQL-frågeoptimeraren är enligt nedan:
- Sortera
- Aggregerat
- Gruppera efter aggregerat
- Begränsning
- Unik
- LockRows
- SetOp
Låt oss förstå var och en av dessa noder.
Sortera
Som namnet antyder läggs denna nod till som en del av ett planträd närhelst det finns behov av sorterad data. Sorterade data kan krävas explicit eller implicit som nedanstående två fall:
Användarscenariot kräver sorterad data som utdata. I det här fallet kan sorteringsnoden ligga ovanpå hel datahämtning inklusive all annan bearbetning.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Obs! Även om användaren krävde slutresultat i sorterad ordning, kan sorteringsnod inte läggas till i den slutliga planen om det finns ett index på motsvarande tabell och sorteringskolumn. I det här fallet kan den välja indexskanning som kommer att resultera i en implicit sorterad dataordning. Låt oss till exempel skapa ett index på exemplet ovan och se resultatet:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Som förklarat i min tidigare blogg En översikt över JOIN-metoderna i PostgreSQL, Merge Join kräver att båda tabelldata sorteras innan de går med. Så det kan hända att Merge Join funnits vara billigare än någon annan anslutningsmetod även med en extra kostnad för sortering. Så i det här fallet kommer sorteringsnoden att läggas till mellan join och skanningsmetod för tabellen så att sorterade poster kan skickas vidare till joinmetoden.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Aggregerat
Aggregerad nod läggs till som en del av ett planträd om det finns en aggregatfunktion som används för att beräkna enstaka resultat från flera inmatningsrader. Några av de aggregerade funktionerna som används är COUNT, SUM, AVG (AVERAGE), MAX (MAXIMUM) och MIN (MINIMUM).
En aggregerad nod kan komma ovanpå en basrelationsskanning eller (och) vid sammanfogning av relationer. Exempel:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
Dessa typer av noder är förlängningar av "Aggregerad"-noden. Om aggregerade funktioner används för att kombinera flera inmatningsrader enligt deras grupp, läggs dessa typer av noder till i ett planträd. Så om frågan har någon aggregatfunktion som används och tillsammans med det finns en GROUP BY-sats i frågan, kommer antingen HashAggregate- eller GroupAggregate-noden att läggas till i planträdet.
Eftersom PostgreSQL använder Cost Based Optimizer för att generera ett optimalt planträd är det nästan omöjligt att gissa vilken av dessa noder som kommer att användas. Men låt oss förstå när och hur det används.
HashAggregate
HashAggregate fungerar genom att bygga hashtabellen för data för att gruppera dem. Så HashAggregate kan användas av aggregat på gruppnivå om aggregatet sker på osorterad datamängd.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Här är demo1-tabellschemadata enligt exemplet som visas i föregående avsnitt. Eftersom det bara finns 1000 rader att gruppera, så är resursen som krävs för att bygga en hashtabell mindre än kostnaden för sortering. Frågeplaneraren bestämmer sig för att välja HashAggregate.
GroupAggregate
GroupAggregate fungerar på sorterad data så den kräver ingen ytterligare datastruktur. GroupAggregate kan användas av gruppnivåaggregat om aggregeringen är på sorterad datamängd. För att gruppera på sorterad data kan den antingen explicit sortera (genom att lägga till Sorteringsnod) eller så kan den fungera på data hämtad efter index i vilket fall den är implicit sorterad.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Här är demo2-tabellschemadata enligt exemplet som visas i föregående avsnitt. Eftersom det här finns 100 000 rader att gruppera, så resursen som krävs för att bygga hashtabell kan vara dyrare än kostnaden för sortering. Så frågeplaneraren bestämmer sig för att välja GroupAggregate. Observera här att posterna som valts från "demo2"-tabellen är explicit sorterade och för vilka det finns en nod tillagd i planträdet.
Se nedan ett annat exempel, där redan data hämtas sorterade på grund av indexskanning:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Se nedan ytterligare ett exempel, som även om det har Index Scan, fortfarande måste sorteras explicit som kolumnen där index där och grupperingskolumnen inte är samma. Så fortfarande måste den sorteras enligt grupperingskolumnen.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Obs! GroupAggregate/HashAggregate kan användas för många andra indirekta frågor även om aggregering med grupp inte finns i frågan. Det beror på hur planeraren tolkar frågan. T.ex. Säg att vi behöver få ett distinkt värde från tabellen, då kan den ses som en grupp av motsvarande kolumn och sedan ta ett värde från varje grupp.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Så här används HashAggregate även om det inte finns någon aggregering och grupp av inblandade.
Begränsning
Limit noder läggs till i planträdet om "limit/offset"-satsen används i SELECT-frågan. Denna sats används för att begränsa antalet rader och eventuellt tillhandahålla en offset för att börja läsa data. Exempel nedan:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Unik
Denna nod väljs för att få ett distinkt värde från det underliggande resultatet. Observera att beroende på fråga, selektivitet och annan resursinformation, kan det distinkta värdet hämtas med HashAggregate/GroupAggregate även utan att använda Unique node. Exempel:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)LockRows
PostgreSQL tillhandahåller funktionalitet för att låsa alla valda rader. Rader kan väljas i ett "Delat"-läge eller "Exklusivt"-läge beroende på "FOR SHARE" respektive "FOR UPDATE"-klausulen. En ny nod "LockRows" läggs till i planträdet för att uppnå denna operation.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQL tillhandahåller funktionalitet för att kombinera resultaten av två eller flera frågor. Så eftersom typen av Join-nod väljs för att sammanfoga två tabeller, väljs en liknande typ av SetOp-nod för att kombinera resultaten av två eller flera frågor. Tänk till exempel en tabell med anställda med deras id, namn, ålder och lön enligt nedan:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Låt oss nu få anställda som är äldre än 25 år:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Låt oss nu få anställda med en lön på över 95 miljoner:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)Nu för att få anställda med ålder över 25 år och lön över 95 miljoner, kan vi skriva nedan korsningsfråga:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) Så här, en ny typ av nod HashSetOp läggs till för att utvärdera skärningspunkten mellan dessa två individuella frågor.
Observera att det finns två andra typer av nya noder som läggs till här:
Lägg till
Denna nod läggs till för att kombinera flera resultat till ett.
Sökning av underfråga
Denna nod läggs till för att utvärdera alla underfrågor. I planen ovan läggs underfrågan till för att utvärdera ytterligare ett konstant kolumnvärde som indikerar vilken ingångsuppsättning som bidrog med en specifik rad.
HashedSetop arbetar med hash för det underliggande resultatet men det är möjligt att generera sorteringsbaserad SetOp-operation med frågeoptimeraren. Sorteringsbaserad Setop-nod betecknas som "Setop".
Obs:Det är möjligt att uppnå samma resultat som visas i ovanstående resultat med en enda fråga, men här visas det med intersect bara för en enkel demonstration.
Slutsats
Alla noder i PostgreSQL är användbara och väljs baserat på frågans natur, data etc. Många av satserna är mappade en till en med noder. För vissa klausuler finns det flera alternativ för noder, som avgörs baserat på de underliggande datakostnadsberäkningarna.