I min tidigare blogg diskuterade vi olika sätt att välja, eller skanna, data från en enda tabell. Men i praktiken räcker det inte att hämta data från en enda tabell. Det kräver att man väljer data från flera tabeller och sedan korrelerar mellan dem. Korrelation av dessa data mellan tabeller kallas sammanfogande tabeller och det kan göras på olika sätt. Eftersom sammanfogningen av tabeller kräver indata (t.ex. från tabellskanningen), kan det aldrig vara en lövnod i planen som genereras.
T.ex. betrakta ett enkelt frågeexempel som SELECT * FROM TBL1, TBL2 där TBL1.ID> TBL2.ID; och anta att planen som genereras är enligt nedan:
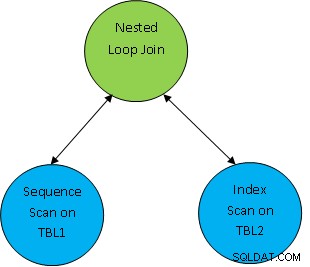
Så här skannas de första båda tabellerna och sedan sammanfogas de som enligt korrelationsvillkoret som TBL.ID> TBL2.ID
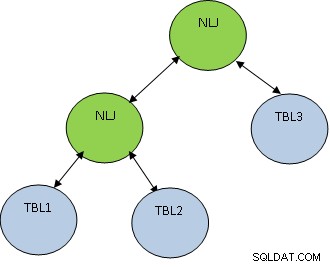
Förutom kopplingsmetoden är kopplingsordningen också mycket viktig. Tänk på exemplet nedan:
VÄLJ * FRÅN TBL1, TBL2, TBL3 VAR TBL1.ID=TBL2.ID OCH TBL2.ID=TBL3.ID;
Tänk på att TBL1, TBL2 OCH TBL3 har 10, 100 respektive 1000 poster.
Villkoret TBL1.ID=TBL2.ID returnerar endast 5 poster, medan TBL2.ID=TBL3.ID returnerar 100 poster, då är det bättre att först slå samman TBL1 och TBL2 så att ett mindre antal poster får gick med TBL3. Planen kommer att vara som visas nedan:
PostgreSQL stöder följande typer av anslutningar:
- Nested Loop Join
- Hash Join
- Slå samman gå med
Var och en av dessa Join-metoder är lika användbara beroende på frågan och andra parametrar, t.ex. fråga, tabelldata, join-klausul, selektivitet, minne etc. Dessa join-metoder implementeras av de flesta relationsdatabaser.
Låt oss skapa en förinställd tabell och fylla på med lite data, som kommer att användas ofta för att bättre förklara dessa skanningsmetoder.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZEI alla våra efterföljande exempel tar vi hänsyn till standardkonfigurationsparametern om inte annat specifikt anges.
Nested Loop Join
Nested Loop Join (NLJ) är den enklaste kopplingsalgoritmen där varje post av yttre relation matchas med varje post av inre relation. Sammanfogningen mellan relation A och B med villkor A.ID Nested Loop Join (NLJ) är den vanligaste kopplingsmetoden och den kan användas nästan på alla datauppsättningar med vilken typ av kopplingssats som helst. Eftersom denna algoritm skannar alla tuplar av inre och yttre relation, anses det vara den mest kostsamma sammanfogningsoperationen. I enlighet med tabellen och data ovan, kommer följande fråga att resultera i en Nested Loop Join som visas nedan: Eftersom join-satsen är "<", är den enda möjliga joinmetoden här Nested Loop Join. Lägg här märke till en ny typ av nod som Materialize; denna nod fungerar som mellanliggande resultatcache, dvs istället för att hämta alla tuplar av en relation flera gånger, lagras det första gången hämtade resultatet i minnet och vid nästa begäran om att få tuple kommer att serveras från minnet istället för att hämtas från relationssidorna igen . Om alla tuplar inte kan passas in i minnet går spill-over-tuplar till en temporär fil. Det är mestadels användbart i fallet med Nested Loop Join och i viss mån i fallet med Merge Join eftersom de förlitar sig på omsökning av inre relation. Materialize Node är inte bara begränsat till cachning av resultat av relation, utan den kan cache resultat från vilken nod som helst nedan i planträdet. TIPS:Om join-satsen är "=" och kapslad loop-join väljs mellan en relation, är det verkligen viktigt att undersöka om en mer effektiv join-metod som hash eller merge join kan väljas av inställningskonfiguration (t.ex. work_mem men inte begränsat till ) eller genom att lägga till ett index, etc. En del av frågorna kanske inte har join-klausul, i så fall är det enda valet att gå med i Nested Loop Join. T.ex. överväg nedanstående frågor enligt förinställningsdata: Kombinationen i exemplet ovan är bara en kartesisk produkt av båda tabellerna. Denna algoritm fungerar i två faser: Kopplingen mellan relation A och B med villkoret A.ID =B.ID kan representeras enligt nedan: I enlighet med ovanstående förinställningstabell och data, kommer följande fråga att resultera i en Hash Join som visas nedan: Här skapas hashtabellen på tabellen blogtable2 eftersom det är den mindre tabellen så det minimala minnet som krävs för hashtabellen och hela hashtabellen får plats i minnet. Merge Join är en algoritm där varje post av yttre relation matchas med varje post av inre relation tills det finns en möjlighet för join-satsmatchning. Denna join-algoritm används endast om båda relationerna är sorterade och join-satsoperatorn är "=". Kopplingen mellan relation A och B med villkoret A.ID =B.ID kan representeras enligt nedan: Exempelfrågan som resulterade i en Hash Join, som visas ovan, kan resultera i en Merge Join om indexet skapas på båda tabellerna. Detta beror på att tabelldata kan hämtas i sorterad ordning på grund av indexet, vilket är ett av huvudkriterierna för metoden Merge Join: Så, som vi ser, använder båda tabellerna indexskanning istället för sekventiell genomsökning, vilket gör att båda tabellerna kommer att skicka ut sorterade poster. PostgreSQL stöder olika planerarerelaterade konfigurationer, som kan användas för att antyda frågeoptimeraren att inte välja någon speciell typ av kopplingsmetoder. Om kopplingsmetoden som valts av optimeraren inte är optimal, kan dessa konfigurationsparametrar stängas av för att tvinga frågeoptimeraren att välja en annan typ av kopplingsmetoder. Alla dessa konfigurationsparametrar är "på" som standard. Nedan finns konfigurationsparametrarna för planerare som är specifika för kopplingsmetoder. Det finns många planrelaterade konfigurationsparametrar som används för olika ändamål. I den här bloggen är det begränsat till att bara gå med metoder. Dessa parametrar kan ändras från en viss session. Så om vi vill experimentera med planen från en viss session, kan dessa konfigurationsparametrar manipuleras och andra sessioner kommer fortfarande att fortsätta att fungera som de är. Tänk nu på ovanstående exempel på merge join och hash join. Utan ett index valde frågeoptimeraren en Hash Join för nedanstående fråga, men efter att ha använt konfigurationen växlar den till merge join även utan index: Initialt har Hash Join valts eftersom data från tabeller inte sorteras. För att välja sammanfogningsplanen måste den först sortera alla poster som hämtats från båda tabellerna och sedan tillämpa sammanfogningen. Så kostnaden för sortering kommer att bli ytterligare och därför kommer den totala kostnaden att öka. Så möjligen, i det här fallet, är den totala (inklusive ökade) kostnaden mer än den totala kostnaden för Hash Join, så Hash Join väljs. När konfigurationsparametern enable_hashjoin har ändrats till "av", betyder det att frågeoptimeraren direkt tilldelar en kostnad för hash-join som inaktiveringskostnad (=1.0e10, dvs. 10000000000.00). Kostnaden för eventuell anslutning kommer att vara lägre än detta. Så, samma frågeresultat i Merge Join efter att enable_hashjoin ändrades till "off" eftersom den totala kostnaden för merge join även inklusive sorteringskostnaden är lägre än inaktiveringskostnaden. Tänk nu på exemplet nedan: Som vi kan se ovan, även om den kapslade loop join-relaterade konfigurationsparametern ändras till "off" väljer den ändå Nested Loop Join eftersom det inte finns någon alternativ möjlighet för någon annan typ av sammanfogningsmetod att få vald. I enklare termer, eftersom Nested Loop Join är den enda möjliga joinningen, så kommer det alltid att vara vinnaren oavsett kostnaden (samma som jag brukade vara vinnaren i 100 m lopp om jag sprang ensam...:-)). Lägg också märke till skillnaden i kostnad i den första och andra planen. Den första planen visar den faktiska kostnaden för Nested Loop Join men den andra visar inaktiveringskostnaden för densamma. Alla typer av PostgreSQL join-metoder är användbara och väljs baserat på frågans karaktär, data, join-klausul, etc. Om frågan inte fungerar som förväntat, dvs. join-metoder fungerar inte som förväntat. vald som förväntat då kan användaren leka med olika tillgängliga plankonfigurationsparametrar och se om något saknas.For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)Hash Join
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Slå samman gå med
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)Konfiguration
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)Slutsats