Om ditt system är beroende av PostgreSQL och du letar efter klustringslösningar för High Availability, vill vi meddela dig i förväg att det är en komplex uppgift men inte omöjlig att uppnå.
Med tanke på dina krav på feltolerans finns här några klustringslösningar med hög tillgänglighet att välja mellan som kan hjälpa.
PostgreSQL stöder inte inbyggt någon multi-master-klustringslösning som MySQL eller Oracle. Ändå erbjuder många kommersiella och community-produkter denna implementering, inklusive replikering och lastbalansering för PostgreSQL.
Låt oss börja med några grundläggande begrepp:
Vad är hög tillgänglighet?
Hög tillgänglighet hänvisar till hur lång tid en tjänst är tillgänglig och definieras vanligtvis av ett företags överenskomna prestationsnivå.
Redundans är grunden för hög tillgänglighet; i händelse av en incident kan du fortsätta att driva och komma åt system utan problem.
Kontinuerlig återställning
När en incident inträffar, om du måste återställa en säkerhetskopia och sedan använda WAL-loggarna (Write-Ahead Logging), skulle återställningstiden vara mycket lång och den skulle inte vara mycket tillgänglig.
Men om du har säkerhetskopiorna och loggarna arkiverade på en beredskapsserver kan du använda loggarna när de kommer. Om loggarna skickas och tillämpas varje minut, skulle beredskapsbasen vara i en kontinuerlig återhämtning och skulle ha ett föråldrat tillstånd för produktion på högst en minut.
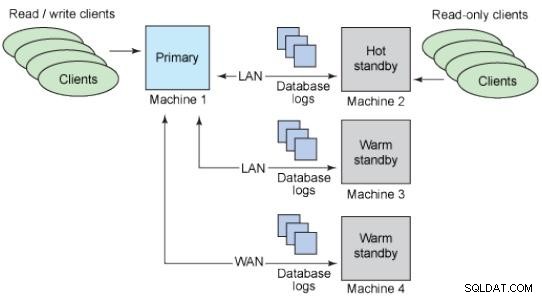
Standby-databaser
Idén med en standby-databas är att behålla en kopia av en produktionsdatabas som alltid har samma data och är redo att användas i händelse av en incident.
Det finns flera sätt att klassificera en standby-databas.
På arten av replikeringen:
-
Fysiska standbylägen:Diskblock kopieras.
-
Logiska väntelägen:Streaming av dataändringarna.
Genom transaktionernas synkronitet:
-
Asynkron:Det finns risk för dataförlust.
-
Synkron:Det finns ingen möjlighet till dataförlust; Bekräftelserna i mastern väntar på svar från standby.
Genom användning:
-
Varma väntelägen:De stöder inte anslutningar.
-
Hot standbys:Stöd för skrivskyddade anslutningar.
Kluster
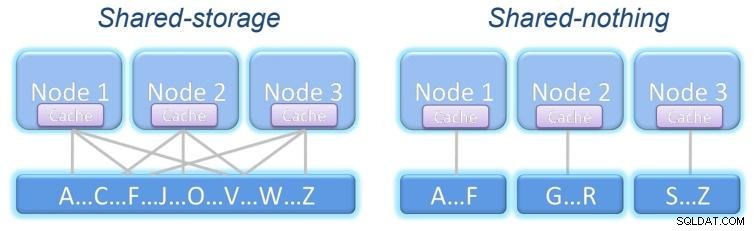
Ett kluster är en grupp värdar som arbetar tillsammans och ses som en. Detta ger ett sätt att uppnå horisontell skalbarhet och möjligheten att bearbeta mer arbete genom att lägga till servrar.
Den kan motstå fel på en nod och fortsätta att fungera transparent. Beroende på vad som delas finns det två klustermodeller:
-
Delad lagring:Alla noder får åtkomst till samma lagring med samma information.
-
Delade ingenting:Varje nod har sin egen lagring, som kanske har samma information som den andra noder, beroende på strukturen i vårt system.
Låt oss nu granska några av klustringsalternativen vi har i PostgreSQL.
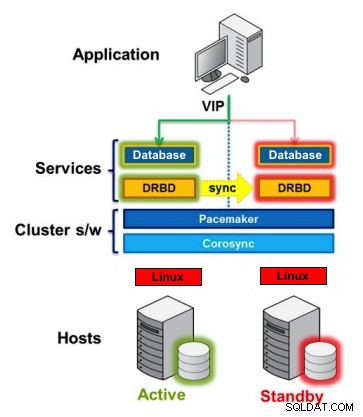
Distribuerad replikerad blockeringsenhet
DRBD är en Linux-kärnmodul som implementerar synkron blockreplikering med hjälp av nätverket. Den implementerar faktiskt inte ett kluster och hanterar inte failover eller övervakning. Du behöver kompletterande programvara för det, till exempel Corosync + Pacemaker + DRBD.
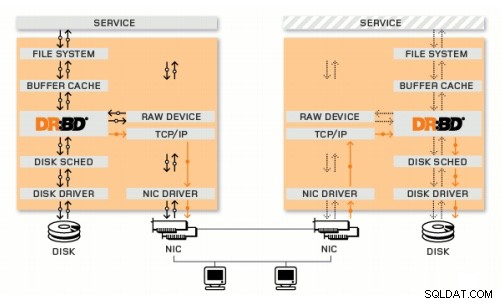
Exempel:
-
Corosync:Hanterar meddelanden mellan värdar.
-
Pacemaker:Startar och stoppar tjänster och ser till att de bara körs på en värd.
-
DRBD:Synkroniserar data på nivån för blockenheter.
ClusterControl
ClusterControl är en agentfri hanterings- och automatiseringsprogramvara för databaskluster. Det hjälper till att distribuera, övervaka, hantera och skala din databasserver/kluster direkt från användargränssnittet. Den kan hantera de flesta administrationsuppgifter som krävs för att underhålla databasservrar eller kluster.
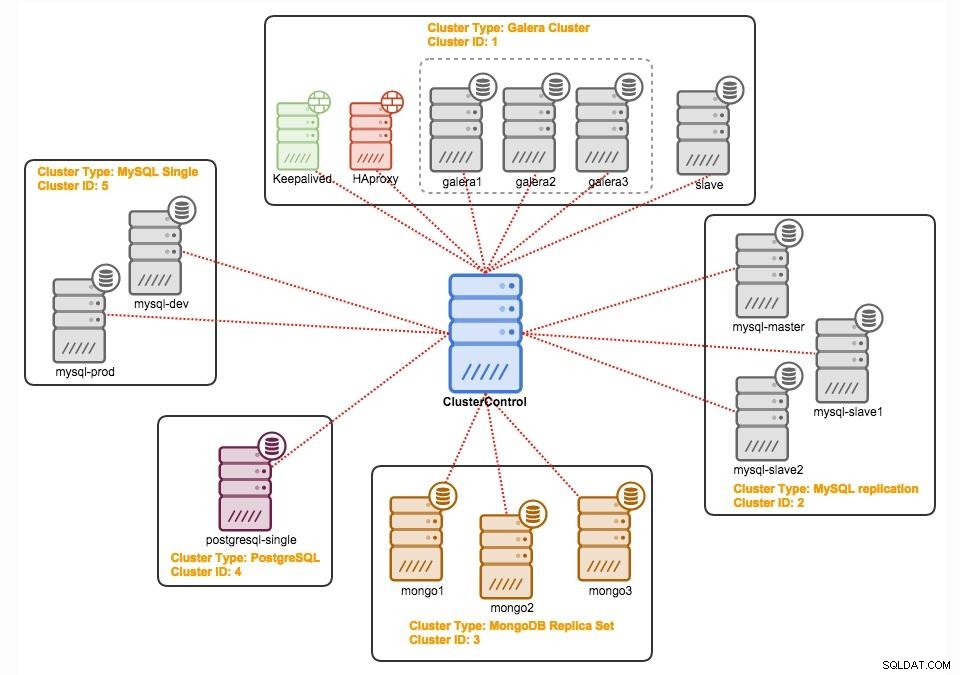
Med ClusterControl kan du:
-
Distribuera fristående, replikerade eller klustrade databaser på den teknikstack du väljer.
-
Automatisera failovers, återställning och dagliga uppgifter enhetligt över polyglotdatabaser och dynamiska infrastrukturer.
-
Skapa fullständiga eller inkrementella säkerhetskopior manuellt eller schemalägg dem.
-
Gör enhetlig och omfattande övervakning i realtid av hela din databas och serverinfrastruktur.
-
Lägg till eller ta bort en nod enkelt med en enda åtgärd.
-
Klona ditt kluster till ett annat datacenter/molnleverantör
Om du har en incident på PostgreSQL kan din Standby-nod flyttas upp till Primär automatiskt.
Det är ett komplett verktyg som erbjuder full-ops livscykelhantering och automatisering genom en enda glasruta. ClusterControl tillhandahåller också en gratis 30-dagars provperiod så att du kan utvärdera den, utan begränsningar.
Rubyrep
Rubyrep är en lösning som tillhandahåller asynkron, multi-master, multi-plattform replikering (implementerad i Ruby eller JRuby) och multi-DBMS (MySQL eller PostgreSQL).
Det är baserat på utlösare och stöder inte DDL, användare eller anslag. Enkel användning och administration är dess främsta mål.
Vissa funktioner inkluderar:
-
Enkel konfiguration
-
Enkel installation
-
Plattformoberoende, bordsdesignoberoende.
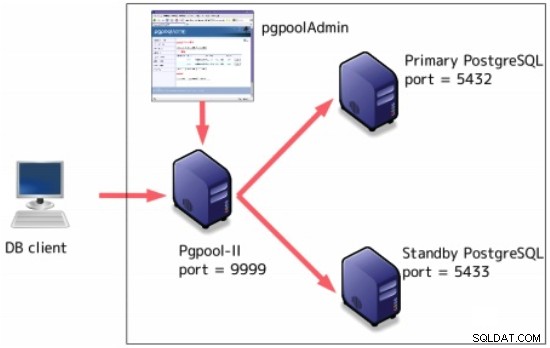
Pgpool-II
Pgpool-II är ett mellanprogram som fungerar mellan PostgreSQL-servrar och en PostgreSQL-databasklient.
Vissa funktioner inkluderar:
-
Anslutningspool
-
Replikering
-
Lastbalansering
-
Automatisk failover
-
Parallella frågor
Det kan konfigureras ovanpå strömmande replikering:
Bucardo
Bucardo erbjuder asynkron kaskadkopplande master-slav-replikering, radbaserad, med hjälp av triggers och köer i databasen, och asynkron master-master-replikering, radbaserad, med hjälp av triggers och anpassad konfliktlösning.
Bucardo kräver en dedikerad databas och körs som en Perl-demon som kommunicerar med denna databas och alla andra databaser som är involverade i replikeringen. Den kan köras som multi-master eller multi-slave.
Master-slave replikering involverar en eller flera källor som går till ett eller flera mål. Källan måste vara PostgreSQL, men målen kan vara PostgreSQL, MySQL, Redis, Oracle, MariaDB, SQLite eller MongoDB.
Vissa funktioner inkluderar:
-
Lastbalansering
-
Slavar är inte begränsade och kan skrivas
-
Delvis replikering
-
Replikering på begäran (ändringar kan skickas automatiskt eller när så önskas)
-
Slavar kan "förvärmas" för snabb installation
Nackdelar:
-
Kan inte hantera DDL
-
Kan inte hantera stora föremål
-
Kan inte stegvis replikera tabeller utan en unik nyckel
-
Fungerar inte på versioner äldre än Postgres 8
Postgres-XC
Postgres-XC är ett projekt med öppen källkod för att tillhandahålla en skrivskalbar, synkron, symmetrisk och transparent PostgreSQL-klusterlösning. Det är en samling tätt kopplade databaskomponenter som kan installeras i mer än en hårdvara eller virtuell maskin.
Skriv-skalbar innebär att Postgres-XC kan konfigureras med så många databasservrar som du vill och hantera många fler skrivningar (uppdatering av SQL-satser) jämfört med vad en enskild databasserver kan göra.
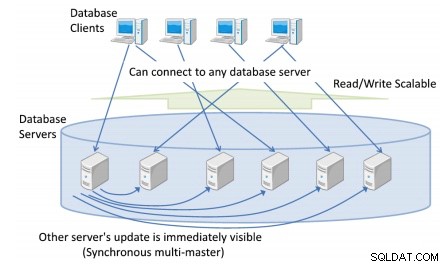
Du kan ha mer än en databasserver som klienter ansluter till, vilket ger en enda, konsekvent klusteromfattande vy av databasen.
Alla databasuppdateringar från vilken databasserver som helst är omedelbart synliga för alla andra transaktioner som körs på olika masters.
Transparent betyder att du inte behöver oroa dig för hur din data lagras på mer än en databasserver internt.
Du kan konfigurera Postgres-XC att köras på flera servrar. Dina data lagras på ett distribuerat sätt, partitionerat eller replikerat, som du väljer för varje tabell. När du utfärdar frågor bestämmer Postgres-XC var måldata lagras och skickar motsvarande frågor till servrar som innehåller måldata.
Citus
Citus är en drop-in-ersättning för PostgreSQL med inbyggda funktioner för hög tillgänglighet som automatisk delning och replikering. Citus skär ner din databas och replikerar flera kopior av varje skärva över klustret av handelsnoder. Om en nod i klustret blir otillgänglig, omdirigerar Citus transparent alla skrivningar eller frågor till en av de andra noderna som innehåller en kopia av den påverkade skärpan.
Vissa funktioner inkluderar:
-
Automatisk logisk skärning
-
Inbyggd replikering
-
Datacentermedveten replikering för katastrofåterställning
-
Feltolerans i mitten av frågan med avancerad lastbalansering
Du kan öka drifttiden för dina realtidsapplikationer som drivs av PostgreSQL och minimera inverkan av hårdvarufel på prestanda. Du kan uppnå detta med inbyggda verktyg för hög tillgänglighet som minimerar kostsamma och felbenägna manuella ingrepp.
PostgresXL
PostgresXL är en delad-ingenting, multi-master klustringslösning som transparent kan distribuera en tabell på en uppsättning noder och exekvera frågor parallellt med dessa noder. Den har en extra komponent som kallas Global Transaction Manager (GTM) för att ge en globalt konsekvent bild av klustret.
PostgresXL är ett horisontellt skalbart SQL-databaskluster med öppen källkod, tillräckligt flexibelt för att hantera varierande databasarbetsbelastningar:
-
OLTP-skrivintensiva arbetsbelastningar
-
Business Intelligence som kräver MPP-parallellism
-
Operational datastore
-
Nyckel-värdelager
-
GIS Geospatial
-
miljöer med blandad arbetsbelastning
-
Omgivningar med flera hyresgäster som är värd för leverantörer

Komponenter:
-
Global Transaction Monitor (GTM):Global Transaction Monitor säkerställer klusterövergripande transaktionskonsistens.
-
Koordinator:Samordnaren hanterar användarsessionerna och interagerar med GTM och datanoderna.
-
Datanod:Datanoden är där den faktiska datan lagras.
Avsluta
Det finns många fler produkter tillgängliga för att implementera din högtillgänglighetsmiljö för PostgreSQL, men du måste vara försiktig med:
-
Nya produkter, inte tillräckligt testade
-
Projekt som upphört
-
Begränsningar
-
Licenskostnader
-
Mycket komplexa implementeringar
-
Osäkra lösningar
När du väljer vilken lösning du ska använda, ta även hänsyn till din infrastruktur. Om du bara har en applikationsserver, oavsett hur mycket du har konfigurerat den höga tillgängligheten för databaserna, är du otillgänglig om applikationsservern misslyckas. Du måste analysera de enskilda felpunkterna i infrastrukturen väl och försöka lösa dem.
Med hänsyn till dessa punkter kan du hitta en klusterlösning med hög tillgänglighet som anpassar sig efter dina behov och krav, utan huvudvärk. Om du letar efter ytterligare HA-resurser för din PG-databas, kolla in det här inlägget om att distribuera PostgreSQL för hög tillgänglighet.
Följ oss på Twitter och LinkedIn och prenumerera på vårt nyhetsbrev för att hålla dig uppdaterad om databashanteringslösningar och bästa praxis.