Redan 2014 skrev jag en artikel som heter Performance Tuning the Whole Query Plan. Den tittade på sätt att hitta ett relativt litet antal distinkta värden från ett måttligt stort dataset och drog slutsatsen att en rekursiv lösning kan vara optimal. Det här uppföljningsinlägget tar upp frågan för SQL Server 2019 igen, med ett större antal rader.
Testmiljö
Jag kommer att använda 50 GB Stack Overflow 2013-databasen, men vilken stor tabell som helst med ett lågt antal distinkta värden skulle göra det.
Jag kommer att leta efter distinkta värden i BountyAmount kolumnen i dbo.Votes tabell, presenterad i prisbeloppsordning stigande. Rösttabellen har knappt 53 miljoner rader (52 928 720 för att vara exakt). Det finns bara 19 olika prisbelopp, inklusive NULL .
Stack Overflow 2013-databasen kommer utan icke-klustrade index för att minimera nedladdningstiden. Det finns ett klustrat primärnyckelindex på Id kolumnen i dbo.Votes tabell. Den är inställd på SQL Server 2008-kompatibilitet (nivå 100), men vi börjar med en modernare inställning av SQL Server 2017 (nivå 140):
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
Testerna utfördes på min bärbara dator med SQL Server 2019 CU 2. Denna maskin har fyra i7-processorer (hyperthreaded till 8) med en bashastighet på 2,4GHz. Den har 32 GB RAM, med 24 GB tillgängligt för SQL Server 2019-instansen. Kostnadströskeln för parallellitet är satt till 50.
Varje testresultat representerar det bästa av tio körningar, med alla nödvändiga data och indexsidor i minnet.
1. Row Store Clustered Index
För att ställa in en baslinje är den första körningen en seriell fråga utan någon ny indexering (och kom ihåg att detta är med databasen inställd på kompatibilitetsnivå 140):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
Detta skannar det klustrade indexet och använder ett hashaggregat i radläge för att hitta de distinkta värdena för BountyAmount :
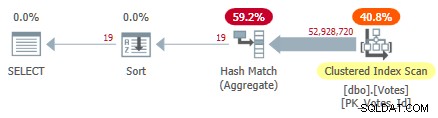 Serial Clustered Index Plan
Serial Clustered Index Plan
Detta tar 10 500 ms att slutföra med samma mängd CPU-tid. Kom ihåg att detta är den bästa tiden över tio körningar med all data i minnet. Automatiskt skapad samplad statistik på BountyAmount kolumnen skapades vid första körningen.
Ungefär hälften av den förflutna tiden spenderas på Clustered Index Scan, och ungefär hälften på Hash Match Aggregate. Sorteringen har bara 19 rader att bearbeta, så den förbrukar bara 1 ms eller så. Alla operatörer i denna plan använder radlägesexekvering.
Ta bort MAXDOP 1 ledtråd ger en parallell plan:
 Parallell Clustered Index Plan
Parallell Clustered Index Plan
Det här är planen som optimeraren väljer utan några tips i min konfiguration. Den returnerar resultat i 4 200 ms med totalt 32 800 ms CPU (vid DOP 8).
2. Nonclustered Index
Genomsöker hela tabellen för att bara hitta BountyAmount verkar ineffektivt, så det är naturligt att försöka lägga till ett icke-klustrat index på bara den kolumn som denna fråga behöver:
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
Detta index tar ett tag att skapa (1m 40s). MAXDOP 1 frågan använder nu ett Stream Aggregate eftersom optimeraren kan använda det icke-klustrade indexet för att presentera rader i BountyAmount beställning:
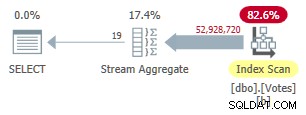 Plan för seriell icke-klustrad radläge
Plan för seriell icke-klustrad radläge
Detta körs i 9 300 ms (förbrukar samma mängd CPU-tid). En användbar förbättring jämfört med de ursprungliga 10 500 ms men knappast världsomspännande.
Ta bort MAXDOP 1 tips ger en parallell plan med lokal (per tråd) aggregering:
 Parallell icke-klustrad radlägesplan
Parallell icke-klustrad radlägesplan
Detta körs på 3 400 ms använder 25 800 ms CPU-tid. Vi kanske kan bli bättre med rad- eller sidkomprimering på det nya indexet, men jag vill gå vidare till fler intressanta alternativ.
3. Batch Mode on Row Store (BMOR)
Ställ nu in databasen till SQL Server 2019-kompatibilitetsläge med:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
Detta ger optimeraren frihet att välja batchläge på radbutik om den anser det värt besväret. Detta kan ge några av fördelarna med att köra batchläge utan att behöva ett kolumnlagerindex. För djupa tekniska detaljer och odokumenterade alternativ, se Dmitry Pilugins utmärkta artikel om ämnet.
Tyvärr väljer optimeraren fortfarande körning av helt radläge med strömaggregat för både seriella och parallella testfrågor. För att få ett batchläge på radbutikens exekveringsplan kan vi lägga till en ledtråd för att uppmuntra aggregering med hashmatchning (som kan köras i batchläge):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); Detta ger oss en plan med alla operatörer som körs i batchläge:
 Serial Batch Mode på Row Store Plan
Serial Batch Mode på Row Store Plan
Resultaten returneras efter 2 600 ms (alla CPU som vanligt). Detta är redan snabbare än parallell radlägesplan (3 400 ms förflutna) samtidigt som man använder mycket mindre CPU (2 600 ms mot 25 800 ms).
Ta bort MAXDOP 1 tips (men behåll HASH GROUP ) ger ett parallellt batchläge på radbutiksplanen:
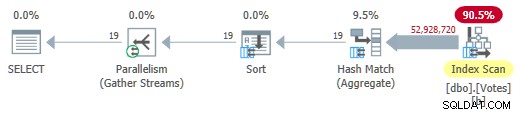 Parallellt batchläge på radbutiksplan
Parallellt batchläge på radbutiksplan
Detta körs på bara 725 ms använder 5 700 ms CPU.
4. Batch-läge på Column Store
Resultatet av det parallella batchläget på radbutiksresultatet är en imponerande förbättring. Vi kan göra ännu bättre genom att tillhandahålla en kolumnlagerrepresentation av datan. För att allt annat ska vara detsamma lägger jag till en icke-klustrad kolumnbutiksindex på just den kolumn vi behöver:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Detta fylls i från det befintliga b-tree icke-klustrade indexet och tar bara 15 sekunder att skapa.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); Optimeraren väljer en plan för fullt batchläge inklusive en kolumnbutiksindexsökning:
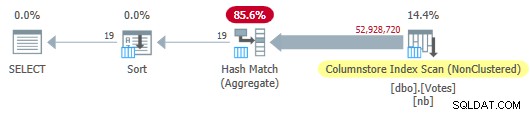 Serieplan för kolumnbutik
Serieplan för kolumnbutik
Detta körs på 115 ms använder samma mängd CPU-tid. Optimeraren väljer denna plan utan några tips om min systemkonfiguration eftersom den uppskattade kostnaden för planen ligger under kostnadströskeln för parallellism .
För att få en parallell plan kan vi antingen sänka kostnadströskeln eller använda en odokumenterad ledtråd:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); I alla fall är den parallella planen:
 Parallell kolumnbutiksplan
Parallell kolumnbutiksplan
Förfluten tid för frågor är nu nere på 30 ms , samtidigt som den förbrukar 210 ms CPU.
5. Batch-läge på Column Store med Push Down
Den nuvarande bästa exekveringstiden på 30 ms är imponerande, speciellt jämfört med de ursprungliga 10 500 ms. Ändå är det lite synd att vi måste passera nästan 53 miljoner rader (i 58 868 batcher) från Scan till Hash Match Aggregate.
Det skulle vara trevligt om SQL Server kunde trycka ner aggregeringen i skanningen och bara returnera distinkta värden från kolumnlagret direkt. Du kanske tror att vi måste uttrycka DISTINCT som en GROUP BY för att få Grouped Aggregate Pushdown, men det är logiskt överflödigt och inte hela historien i alla fall.
Med den nuvarande SQL Server-implementeringen behöver vi faktiskt beräkna ett aggregat för att aktivera aggregerad pushdown. Mer än så måste vi använda det sammanlagda resultatet på något sätt, eller så tar optimeraren bara bort det som onödigt.
Ett sätt att skriva frågan för att uppnå sammanlagd pushdown är att lägga till ett logiskt redundant sekundärt beställningskrav:
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); Serieplanen är nu:
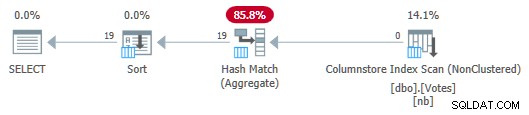 Serial Column Store Plan med Aggregate Push Down
Serial Column Store Plan med Aggregate Push Down
Observera att inga rader skickas från Scan to the Aggregate! Under täcket, partiella aggregat av BountyAmount värden och deras associerade radantal skickas till Hash Match Aggregate, som summerar de partiella aggregaten för att bilda det slutliga (globala) aggregatet som krävs. Detta är mycket effektivt, vilket bekräftas av den förflutna tiden på 13ms (som allt är CPU-tid). Som en påminnelse tog den tidigare serieplanen 115 ms.
För att slutföra uppsättningen kan vi få en parallellversion på samma sätt som tidigare:
 Parallell kolumnbutiksplan med samlad Push Down
Parallell kolumnbutiksplan med samlad Push Down
Detta pågår i 7ms använder 40ms CPU totalt.
Det är synd att vi behöver beräkna och använda ett aggregat som vi inte behöver bara för att trycka ner. Kanske kommer detta att förbättras i framtiden så att DISTINCT och GROUP BY utan aggregat kan tryckas ner till skanningen.
6. Radläge Rekursivt gemensamt tabelluttryck
I början lovade jag att återvända till den rekursiva CTE-lösning som användes för att hitta ett litet antal dubbletter i en stor datamängd. Att implementera det nuvarande kravet med den tekniken är ganska enkelt, även om koden nödvändigtvis är längre än något vi har sett fram till denna punkt:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); Idén har sina rötter i en så kallad index skip scan:Vi hittar det lägsta värdet av intresse i början av det stigande b-trädets index, försöker sedan hitta nästa värde i indexordning, och så vidare. Strukturen hos ett b-trädindex gör det mycket effektivt att hitta det näst högsta värdet – det finns inget behov av att skanna igenom dubbletterna.
Det enda riktiga tricket här är att övertyga optimeraren att tillåta oss att använda TOP i den "rekursiva" delen av CTE för att returnera en kopia av varje distinkt värde. Se min tidigare artikel om du behöver en uppfräschning av detaljerna.
Utförandeplanen (förklarad generellt av Craig Freedman här) är:
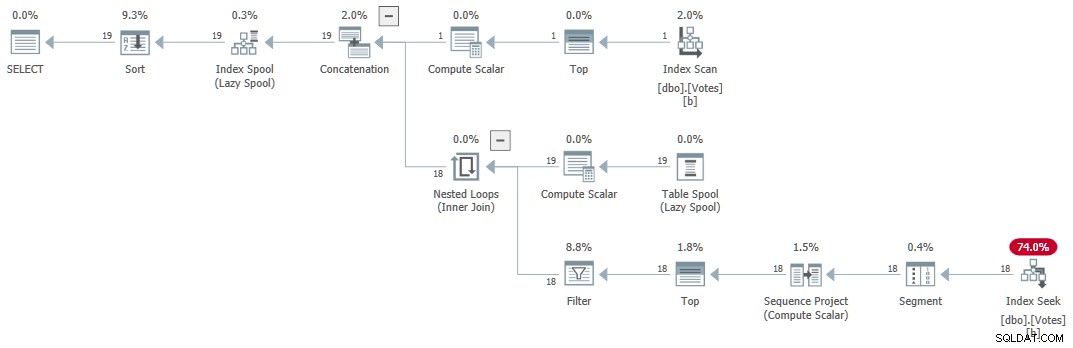 Seriell rekursiv CTE
Seriell rekursiv CTE
Frågan returnerar korrekta resultat på 1 ms använder 1ms CPU, enligt Sentry One Plan Explorer.
7. Iterativ T-SQL
Liknande logik kan uttryckas med en WHILE slinga. Koden kan vara lättare att läsa och förstå än den rekursiva CTE. Det undviker också att behöva använda knep för att komma runt de många begränsningarna på den rekursiva delen av en CTE. Prestandan är konkurrenskraftig på cirka 15 ms. Denna kod tillhandahålls för intresse och ingår inte i resultatöversiktstabellen.
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Resultatöversiktstabell
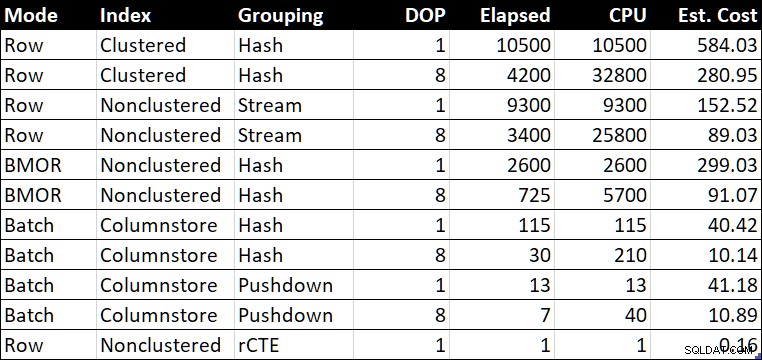 Prestanda Sammanfattningstabell (varaktighet / CPU i millisekunder)
Prestanda Sammanfattningstabell (varaktighet / CPU i millisekunder)
Den "Uppsk. Kolumnen "Kostnad" visar optimerarens kostnadsuppskattning för varje fråga som rapporterats i testsystemet.
Slutliga tankar
Att hitta ett litet antal distinkta värden kan tyckas vara ett ganska specifikt krav, men jag har stött på det ganska ofta genom åren, vanligtvis som en del av att finjustera en större fråga.
De senaste exemplen var ganska nära i prestanda. Många människor skulle vara nöjda med vilket som helst av undersekundsresultaten, beroende på prioriteringar. Till och med det seriella batchläget på radlagringsresultatet på 2 600 ms kan jämföras bra med de bästa parallella radlägesplaner, vilket bådar gott för betydande snabbare bara genom att uppgradera till SQL Server 2019 och aktivera databaskompatibilitetsnivå 150. Alla kommer inte att kunna flytta till kolumnbutikslagring snabbt, och det kommer inte alltid att vara rätt lösning ändå . Batchläge i radlager är ett snyggt sätt att uppnå några av de vinster som är möjliga med kolumnbutiker, förutsatt att du kan övertyga optimeraren att välja att använda den.
Den parallella kolumnen lagrar samlat push-down-resultat på 57 miljoner rader bearbetas på 7ms (med 40ms CPU) är anmärkningsvärt, särskilt med tanke på hårdvaran. Det seriella sammanlagda push-down-resultatet på 13ms är lika imponerande. Det skulle vara bra om jag inte hade behövt lägga till ett meningslöst sammanställt resultat för att få dessa planer.
För dem som ännu inte kan gå över till SQL Server 2019 eller kolumnlagringslagring, är den rekursiva CTE fortfarande en gångbar och effektiv lösning när ett lämpligt b-tree-index finns, och antalet distinkta värden som behövs är garanterat ganska litet. Det skulle vara snyggt om SQL Server kunde komma åt ett b-träd som detta utan att behöva skriva en rekursiv CTE (eller motsvarande iterativ looping T-SQL-kod med WHILE ).
En annan möjlig lösning på problemet är att skapa en indexerad vy. Detta kommer att ge distinkta värden med stor effektivitet. Nackdelen, som vanligt, är att varje ändring av den underliggande tabellen kommer att behöva uppdatera radantalet lagrat i den materialiserade vyn.
Var och en av lösningarna som presenteras här har sin plats, beroende på kraven. Att ha ett brett utbud av verktyg tillgängliga är generellt sett en bra sak när man ställer in frågor. För det mesta skulle jag välja en av batchlägeslösningarna eftersom deras prestanda kommer att vara ganska förutsägbar oavsett hur många dubbletter som finns.