OVER- och PARTITION BY-funktionerna är båda funktioner som används för att dela en resultatuppsättning enligt specificerade kriterier.
Den här artikeln förklarar hur dessa två funktioner kan användas tillsammans för att hämta partitionerad data på mycket specifika sätt.
Förbereda några exempeldata
För att utföra våra exempelfrågor, låt oss först skapa en databas med namnet "studentdb".
Kör följande kommando i ditt frågefönster:
SKAPA DATABAS schooldb;
Därefter måste vi skapa "student"-tabellen i "studentdb"-databasen. Elevtabellen kommer att ha fem kolumner:id, namn, ålder, kön och total_score.
Som alltid, se till att du är väl säkerhetskopierad innan du experimenterar med en ny kod. Se den här artikeln om säkerhetskopiering av SQL Server-databaser om du är osäker.
Kör följande fråga för att skapa elevtabellen.
ANVÄND schooldbCREATE TABLE elev( id INT PRIMÄR NYCKEL IDENTITET, namn VARCHAR(50) NOT NULL, kön VARCHAR(50) NOT NULL, ålder INT INTE NULL, total_score INT NOT NULL, )
Slutligen måste vi infoga lite dummydata som vi kan arbeta med i databasen.
ANVÄND schooldbINSERT INTO student VALUES ('Jolly', 'Female', 20, 500), ('Jon', 'Mane', 22, 545), ('Sara', 'Female', 25, 600), ('Laura', 'Female', 18, 400), ('Alan', 'Mane', 20, 500), ('Kate', 'Female', 22, 500), ('Joseph', 'Mane' , 18, 643), ('Möss', 'Male', 23, 543), ('Wise', 'Mane', 21, 499), ('Elis', 'Female', 27, 400);
Just nu är vi redo att arbeta med ett problem och se vem vi kan använda Over och Partition By för att lösa det.
Problem
Vi har 10 poster i elevtabellen och vi vill visa namn, id och kön för alla elever, och dessutom vill vi också visa det totala antalet elever som tillhör varje kön, medelåldern för elever av varje kön och summan av värdena i kolumnen total_score för varje kön.
Resultatuppsättningen som vi letar efter är enligt nedan:
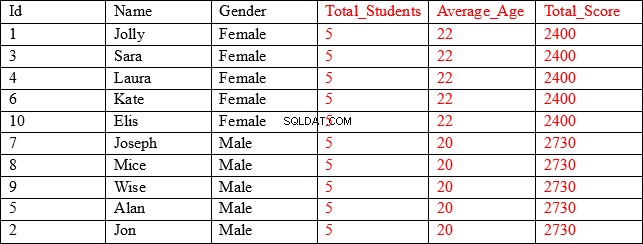
Som du kan se innehåller de tre första kolumnerna (visade i svart) individuella värden för varje post, medan de tre sista kolumnerna (visas i rött) innehåller aggregerade värden grupperade efter könskolumnen. Till exempel, i kolumnen Average_Age, visar de första fem raderna medelåldern och totalpoängen för alla poster där kön är Kvinna.
Vår resultatuppsättning innehåller aggregerade resultat sammanfogade med icke aggregerade kolumner.
För att hämta de aggregerade resultaten, grupperade efter en viss kolumn, kan vi använda GROUP BY-satsen som vanligt.
ANVÄND schooldbSELECT gender, count(gender) AS Total_Students, AVG(age) as Average_Age, SUM(total_score) as Total_ScoreFROM studentGROUP BY genus
Låt oss se hur vi kan hämta Total_Students, Average_Age och Total_Score för eleverna grupperade efter kön.
Du kommer att se följande resultat:

Låt oss nu utöka detta och lägga till "id" och "namn" (de icke-aggregerade kolumnerna i SELECT-satsen) och se om vi kan få vårt önskade resultat.
ANVÄND schooldbSELECT-id, namn, kön, count(gender) AS total_students, AVG(age) as Average_Age, SUM(total_score) as Total_ScoreFROM studentGROUP BY gender
När du kör ovanstående fråga kommer du att se ett felmeddelande:

Felet säger att id-kolumnen i elevtabellen är ogiltig i SELECT-satsen eftersom vi använder GROUP BY-satsen i frågan.
Det betyder att vi måste tillämpa en aggregerad funktion på id-kolumnen eller så måste vi använda den i GROUP BY-satsen. Kort sagt, detta schema löser inte vårt problem.
Lösning med JOIN-förklaring
En lösning på detta skulle vara att använda JOIN-satsen för att sammanfoga kolumnerna med aggregerade resultat till kolumner som innehåller icke aggregerade resultat.
För att göra det behöver du en underfråga som hämtar kön, Total_Students, Average_Age och Total_Score för eleverna grupperade efter kön. Dessa resultat kan sedan kopplas till resultaten som erhålls från underfrågan med den yttre SELECT-satsen. Detta kommer att tillämpas på könskolumnen i underfrågan som innehåller det aggregerade resultatet och könskolumnen i elevtabellen. Den yttre SELECT-satsen skulle inkludera icke aggregerade kolumner, t.ex. "id" och "namn", enligt nedan.
ANVÄND schooldbSELECT id, namn, Aggregation.gender, Aggregation.Total_students, Aggregation.Average_Age, Aggregation.Total_ScoreFROM studentINNER JOIN(SELECT gender, count(gender) AS Total_students, AVG(age) AS Average_Age_ScoreF AS Average_Age_ScoreF AS(total) studentGROUP BY gender) AS Aggregationon Aggregation.gender =student.gender
Ovanstående fråga ger dig det önskade resultatet men är inte den optimala lösningen. Vi var tvungna att använda en JOIN-sats och en underfråga som ökar skriptets komplexitet. Detta är inte en elegant eller effektiv lösning.
Ett bättre tillvägagångssätt är att använda OVER- och PARTITION BY-satserna tillsammans.
Lösning med OVER och PARTITION BY
För att använda OVER- och PARTITION BY-satserna behöver du helt enkelt ange kolumnen som du vill partitionera dina aggregerade resultat efter. Detta förklaras bäst med hjälp av ett exempel.
Låt oss ta en titt på hur vi uppnår vårt resultat med OVER och PARTITION BY.
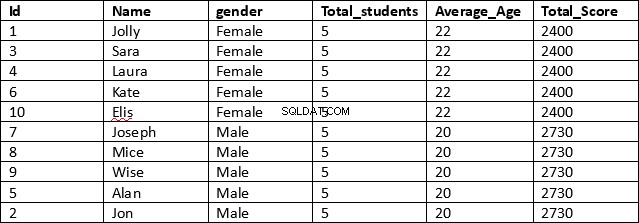
ANVÄND schooldbSELECT id, namn, kön,ANTAL(kön) ÖVER (DELNING EFTER kön) AS Total_students,AVG(ålder) ÖVER (DELNING EFTER kön) AS Average_Age,SUM(total_score) ÖVER (DELNING EFTER kön) AS Total_ScoreFROM student
Detta är ett mycket mer effektivt resultat. I den första raden av skriptet hämtas kolumnerna id, namn och kön. Dessa kolumner innehåller inga sammanställda resultat.
Därefter, för kolumnerna som innehåller aggregerade resultat, anger vi helt enkelt den aggregerade funktionen, följt av OVER-satsen och sedan inom parentesen anger vi PARTITION BY-satsen följt av namnet på kolumnen som vi vill att våra resultat ska delas upp som visas nedan.
Referenser
- Microsoft – Förstå OVER-satsen
- Midnight DBA – Introduktion till OVER och PARTITION BY
- StackOverflow – Skillnaden mellan PARTITION BY och GROUP BY