Orsak till problemet :
TOKEN metod i SSIS använder implementeringen av strtok funktion i C++ . Jag samlade in den här informationen när jag läste boken Microsoft® SQL Server® 2012 Integration Services stark>
. Det nämns som anteckning på sidan 113 (Jag gillar den här boken! Massor av trevlig information. ).
Jag sökte efter implementeringen av strtok funktion och jag hittade följande länkar.
INFO:strtok():C-funktion -- dokumentationstillägg - Kodexemplet i denna länk visar att funktionen inte ignorerar på varandra följande avgränsare.
Svaren på följande SO-frågor pekar på att strtok funktionen är utformad för att ignorera på varandra följande avgränsare.
Behöver veta när ingen data visas mellan två tokenseparatorer med strtok()
strtok_s beteende med konsekutiva avgränsare
Jag tror att TOKEN och TOKENCOUNT funktionerna fungerar enligt design men om det är så SSIS ska bete sig kan vara en fråga för Microsoft SSIS-teamet.
Original post - avsnittet ovan är en uppdatering:
Jag skapade ett enkelt paket i SSIS 2012 baserat på dina datainmatningar. Som du beskrev i din fråga, TOKEN funktionen fungerar inte som avsett. Jag håller med dig om att funktionen inte verkar fungera. Det här inlägget är inte ett svar på ditt ursprungliga problem.
Här är ett alternativt sätt att skriva uttrycket på ett relativt enklare sätt. Detta fungerar bara om det sista segmentet i din indatapost alltid kommer att ha ett värde (säg A1 , B2 , C3 etc.).
Uttryck kan skrivas om som :
Denna sats kommer att ta indataposten som parameter, avgränsaren caret (^) som den andra parametern. Den tredje parametern beräknar det totala antalet segment i posterna när de delas med avgränsaren. Har du data i det sista segmentet har du garanterat två segment. Du kan sedan subtrahera 1 för att hämta det näst sista segmentet.
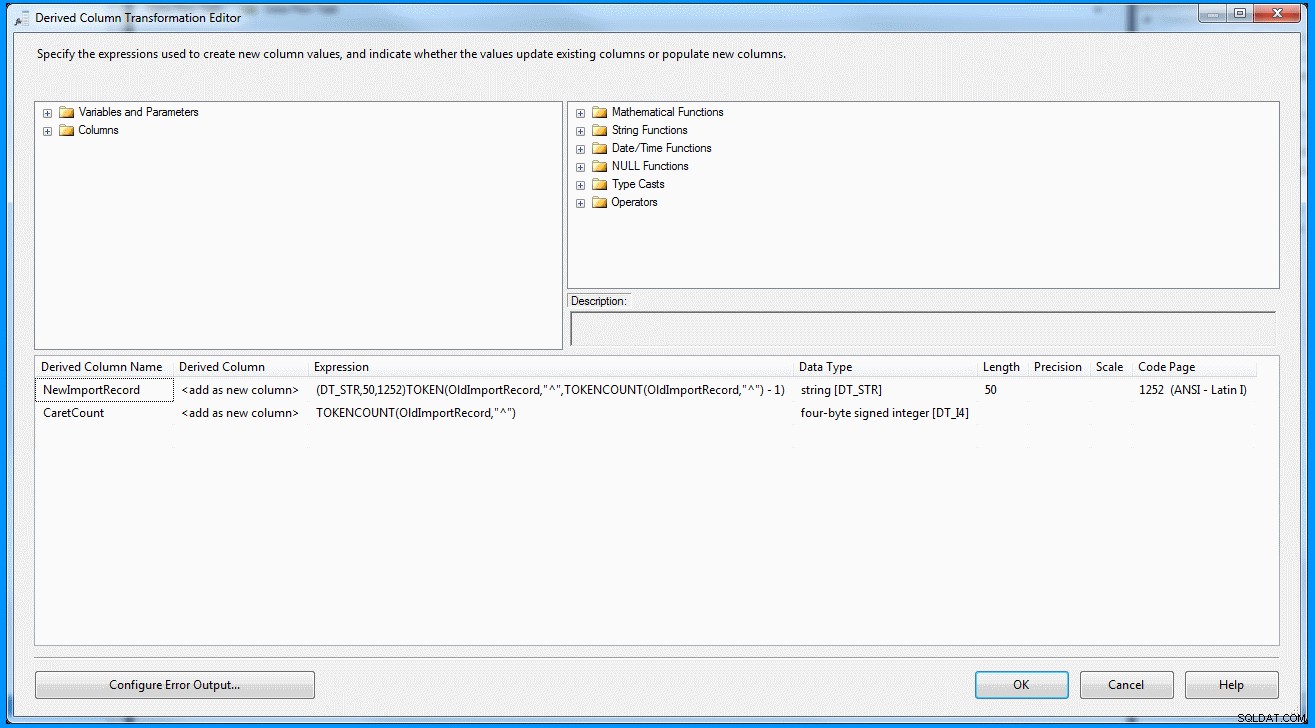
(DT_STR,50,1252)TOKEN(OldImportRecord,"^",TOKENCOUNT(OldImportRecord,"^") - 1)
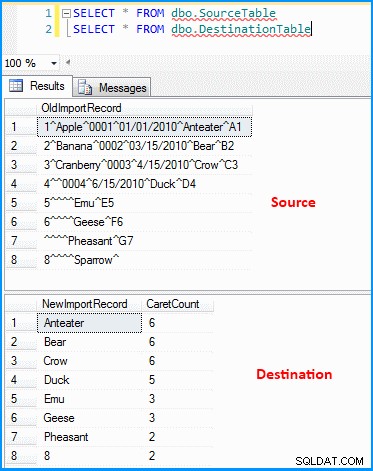
Jag skapade ett enkelt paket med uppgift om dataflöde. OLE DB-källan hämtar data och den härledda transformationen analyserar och delar upp data enligt skärmdumpen nedan. Utdata infogas sedan i destinationstabellen. Du kan se käll- och destinationstabellerna i den sista skärmdumpen. Destinationstabellen har två kolumner. Den första kolumnen lagrar näst sista segmentdata och segmenten räknas baserat på avgränsaren (vilket återigen inte är korrekt). Du kan märka att den senaste posten inte gav rätt resultat. Om den senaste posten inte hade värdet 8 , då misslyckas uttrycket ovan eftersom uttrycket kommer att evalueras till noll index.
Hoppas det hjälper till att förenkla ditt uttryck.
Om du inte hör från någon annan rekommenderar jag att du loggar det här problemet på Microsoft Connect-webbplatsen .
Skapa tabeller och fyll i skript :
CREATE TABLE [dbo].[SourceTable](
[OldImportRecord] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DestinationTable](
[NewImportRecord] [varchar](50) NOT NULL,
[CaretCount] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.SourceTable (OldImportRecord) VALUES
('1^Apple^0001^01/01/2010^Anteater^A1'),
('2^Banana^0002^03/15/2010^Bear^B2'),
('3^Cranberry^0003^4/15/2010^Crow^C3'),
('4^^0004^6/15/2010^Duck^D4'),
('5^^^^Emu^E5'),
('6^^^^Geese^F6'),
('^^^^Pheasant^G7'),
('8^^^^Sparrow^');
GO
Härledd kolumntransformation inuti uppgiften för dataflöde :
Data i käll- och måltabeller :