Underträdskostnader bör tas med en stor nypa salt (och speciellt när du har stora kardinalitetsfel). SET STATISTICS IO ON; SET STATISTICS TIME ON; output är en bättre indikator på faktisk prestanda.
Nollradssorteringen tar inte 87 % av resurserna. Detta problem i din plan är ett av statistikuppskattningar. De kostnader som visas i den faktiska planen är fortfarande uppskattade kostnader. Det justerar dem inte för att ta hänsyn till vad som faktiskt hände.
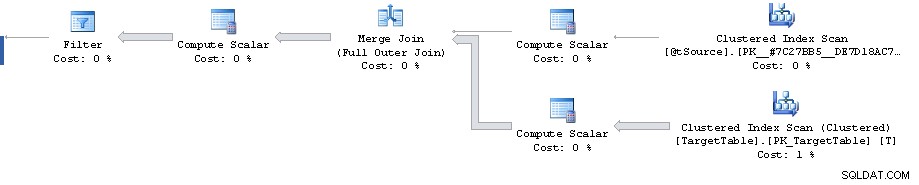
Det finns en punkt i planen där ett filter minskar 1 911 721 rader till 0 men de beräknade raderna framöver är 1 860 310. Därefter är alla kostnader falska och kulminerar i den beräknade kostnaden på 87 % på 3 348 560 rader.
Kardinalitetsuppskattningsfelet kan reproduceras utanför Merge uttalande genom att titta på den beräknade planen för Full Outer Join med motsvarande predikat (ger samma uppskattning av 1 860 310 rader).
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
Som sagt, men planen fram till själva filtret ser ganska suboptimal ut. Den gör en fullständig klustrad indexskanning när du kanske vill ha en plan med 2 klustrade indexintervallsökningar. En för att hämta den enda raden som matchas av primärnyckeln från kopplingen till källan och den andra för att hämta T.Key1 = @id intervall (även om detta kanske är för att undvika behovet av att sortera i klustrad nyckelordning senare?)
Du kanske kan testa den här omskrivningen och se om den fungerar bättre eller sämre
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;