SQL Server-optimeraren innehåller logik för att ta bort redundanta anslutningar, men det finns begränsningar och anslutningarna måste vara bevisligen överflödig . Sammanfattningsvis kan en koppling ha fyra effekter:
- Den kan lägga till extra kolumner (från den sammanfogade tabellen)
- Den kan lägga till extra rader (den sammanfogade tabellen kan matcha en källrad mer än en gång)
- Den kan ta bort rader (den sammanfogade tabellen kanske inte har en matchning)
- Den kan introducera
NULLs (för enRIGHTellerFULL JOIN)
För att lyckas ta bort en redundant koppling måste frågan (eller vyn) ta hänsyn till alla fyra möjligheter. När detta är gjort, korrekt, kan effekten vara häpnadsväckande. Till exempel:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
Optimeraren kan framgångsrikt förenkla följande fråga:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
Till:

Rob Farley skrev om dessa idéer på djupet i original MVP Deep Dives-boken , och det finns en inspelning av honom när han presenterar ämnet på SQLBits.
De huvudsakliga begränsningarna är att främmande nyckelrelationer måste baseras på en enda nyckel för att bidra till förenklingsprocessen, och sammanställningstiden för frågorna mot en sådan vy kan bli ganska lång, särskilt när antalet sammanfogningar ökar. Det kan vara en utmaning att skriva en 100-tabellvy som får all semantik exakt korrekt. Jag skulle vara benägen att hitta en alternativ lösning, kanske med dynamisk SQL .
Som sagt, de speciella egenskaperna hos din denormaliserade tabell kan innebära att vyn är ganska enkel att sätta ihop, och kräver endast påtvingade FOREIGN KEYs icke-NULL kan refereras till kolumner och lämplig UNIQUE begränsningar för att få den här lösningen att fungera som du hoppas, utan de 100 fysiska operatörerna i planen.
Exempel
Använder tio tabeller istället för hundra:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
Den överordnade tabelldefinitionen (med sidkomprimering):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
Utsikten:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
Hacka statistiken för att få optimeraren att tycka att tabellen är väldigt stor:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
Exempel på användarfråga:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
Ger oss denna utförandeplan:
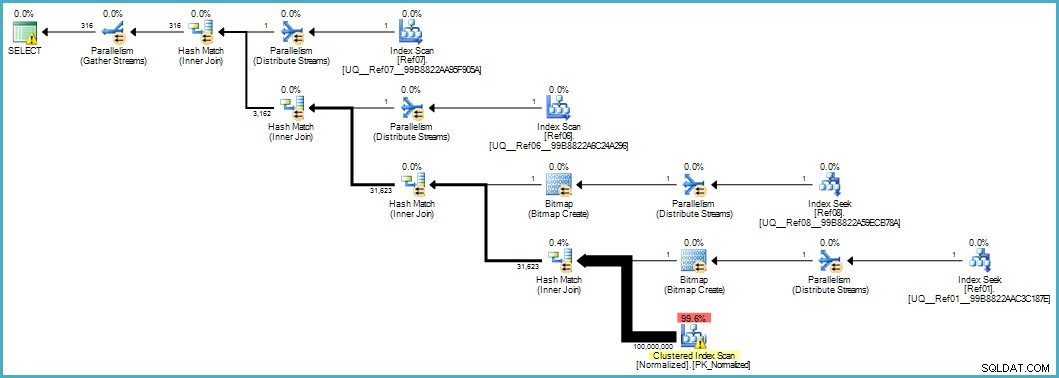
Genomsökningen av den normaliserade tabellen ser dålig ut, men båda Bloom-filterbitmapparna tillämpas under skanningen av lagringsmotorn (så att rader som inte kan matcha inte ens dyker upp så långt som frågeprocessorn). Detta kan vara tillräckligt för att ge acceptabel prestanda i ditt fall, och definitivt bättre än att skanna den ursprungliga tabellen med dess överfulla kolumner.
Om du kan uppgradera till SQL Server 2012 Enterprise i något skede har du ett annat alternativ:skapa ett kolumnbutiksindex i den normaliserade tabellen:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
Utförandeplanen är:
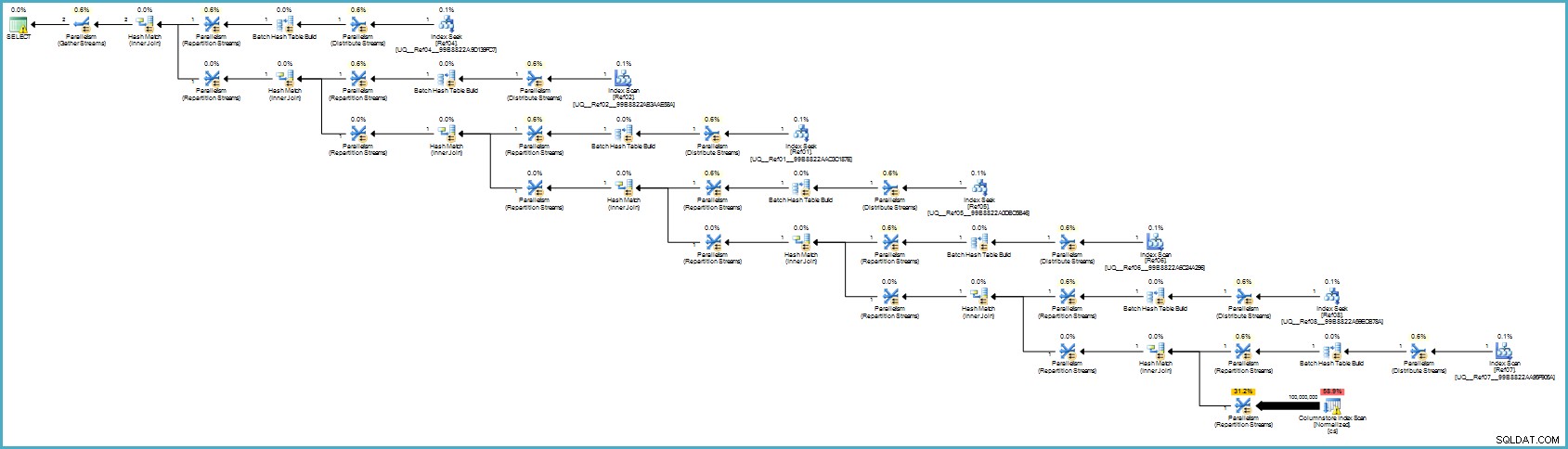
Det ser förmodligen värre ut för dig, men kolumnlagring ger exceptionell komprimering, och hela exekveringsplanen körs i batchläge med filter för alla bidragande kolumner. Om servern har tillräckliga trådar och minne tillgängligt kan detta alternativ verkligen flyga.
I slutändan är jag inte säker på att denna normalisering är det korrekta tillvägagångssättet med tanke på antalet tabeller och chanserna att få en dålig utförandeplan eller kräva överdriven kompileringstid. Jag skulle förmodligen korrigera schemat för den denormaliserade tabellen först (korrekta datatyper och så vidare), eventuellt tillämpa datakomprimering...de vanliga sakerna.
Om data verkligen hör hemma i ett stjärnschema behöver det förmodligen mer designarbete än att bara dela upp repeterande dataelement i separata tabeller.