Demonstration av möjlig förklaring.
Skapa tabellskript
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
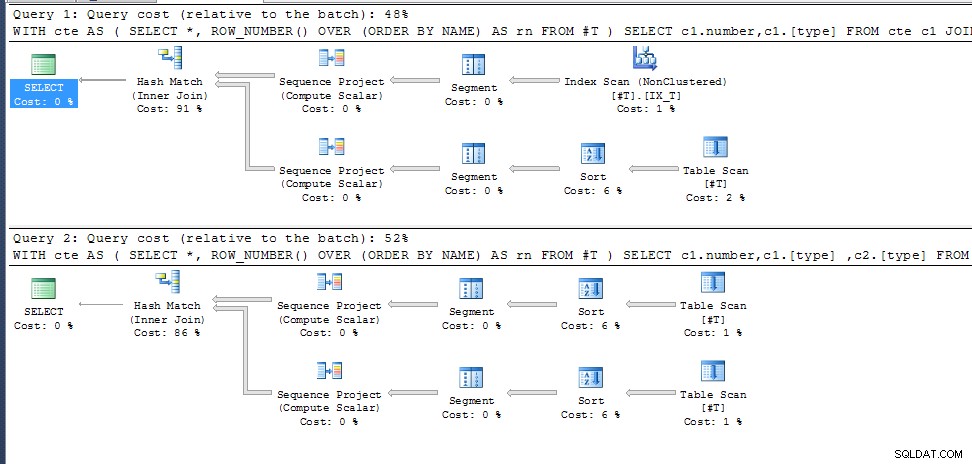
Fråga ett (Ger 35 resultat)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Fråga två (Samma som tidigare men om du lägger till c2.[typ] i den valda listan får den 0 resultat);
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Varför?
row_number() för dubbletter av NAMN är inte specificerade så det väljer bara vilken som passar in med den bästa exekveringsplanen för de nödvändiga utdatakolumnerna. I den andra frågan är detta samma för båda cte-anropen, i den första väljer den en annan åtkomstväg med resulterande olika radnummer.
Föreslagen lösning
Du går själv med i CTE på ROW_NUMBER() over (order by t.[Date])
I motsats till vad som kan ha förväntats kommer CTE sannolikt att inte förverkligas
vilket skulle ha säkerställt konsistens för självanslutningen och därmed antar du en korrelation mellan ROW_NUMBER() på båda sidor som mycket väl inte finns för poster där en dubblett [Date] finns i data.
Vad händer om du försöker ROW_NUMBER() over (order by t.[Date], t.[id]) för att säkerställa att radnumreringen är i en garanterad konsekvent ordning vid ojämna datum. (Eller någon annan kolumn/kombination av kolumner som kan skilja poster om id inte gör det)