På något testbord hos mig ser din ursprungliga plan ut som följer.
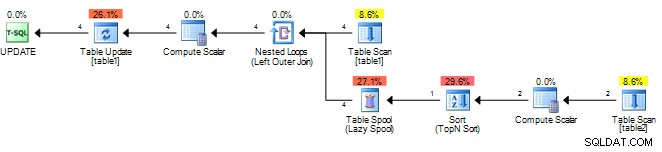
Den beräknar bara resultatet en gång och cachar det i en sppol och spelar sedan upp resultatet. Du kan prova följande så att SQL Server ser underfrågan som korrelerad och behöver omvärderas för varje yttre rad.
UPDATE table1
SET table2Id = (SELECT TOP 1 table2Id
FROM table2
ORDER BY Newid(),
table1.table1Id)
För mig ger det den här planen utan spolen.
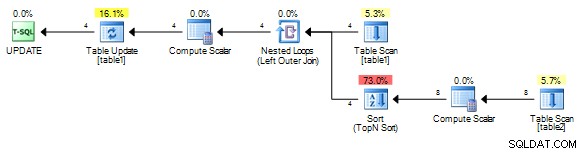
Det är viktigt att korrelera på ett unikt fält från table1 men så att även om en spool läggs till måste den alltid rullas tillbaka istället för att rullas tillbaka (spelar om det senaste resultatet) eftersom korrelationsvärdet kommer att vara olika för varje rad.
Om tabellerna är stora kommer detta att gå långsamt eftersom arbete som krävs är en produkt av de två tabellens rader (för varje rad i table1 den behöver göra en fullständig genomsökning av table2 )