Jag antar att anledningen är att de helt enkelt inte har ansett detta som en prioriterad funktion värd att implementera. Det ser ut som att Postgres gör stödja båda
UNION och UNION ALL .
Om du har starka argument för den här funktionen kan du ge feedback på Anslut (eller vilken webbadress till dess ersättning nu är).
Att förhindra att dubbletter läggs till kan vara användbart eftersom en dubblettrad som läggs till i ett senare steg till en tidigare nästan alltid kommer att orsaka en oändlig loop eller överskrida den maximala rekursionsgränsen.
Det finns en hel del platser i SQL-standarderna
där kod används som visar UNION som nedan
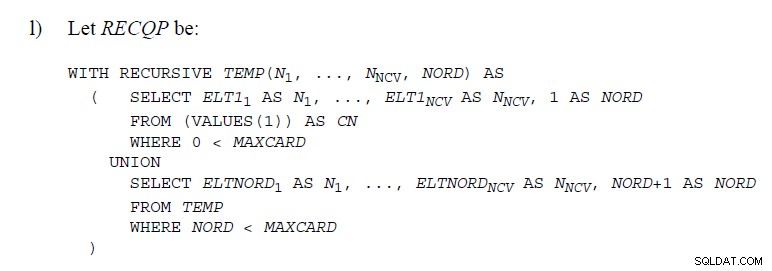
Den här artikeln förklarar hur de är implementerade i SQL Server . De gör inte något sådant "under huven". Stackrullen tar bort rader allt eftersom så det skulle inte vara möjligt att veta om en senare rad är en dubblett av en raderad. Stöder UNION skulle behöva ett något annat tillvägagångssätt.
Under tiden kan du ganska enkelt uppnå samma sak i en TVF med flera uttalanden.
För att ta ett dumt exempel nedan (Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
Ändra UNION till UNION ALL och lägga till en DISTINCT i slutet kommer du inte att rädda dig från den oändliga rekursionen.
Men du kan implementera detta som
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
Ovanstående använder IGNORE_DUP_KEY att kassera dubbletter. Om kolumnlistan är för bred för att indexeras skulle du behöva DISTINCT och NOT EXISTS istället. Du skulle förmodligen också vilja ha en parameter för att ställa in det maximala antalet rekursioner och undvika oändliga loopar.