Hej,
I den här artikeln kommer jag kort att introducera och förklara Failover Cluster-tekniken i SQL Server. Failover Cluster-teknik för SQL Server är också en viktig teknik som ger hög tillgänglighet. Så det används ofta i företagsapplikationer för att ge maximal service i produktionssystem.
Failover Cluster-teknologi är den perfekta tekniken för att upprätthålla den höga tillgänglighetstjänsten för applikationerna i de institutioner som syftar till att tillhandahålla maximal servicenivå (telekommunikation, bank, regeringskontor, innehav).
Denna teknik kan definieras som förmågan hos en enskild databas att kunna tjäna på mer än en server. Således ger den hög tillgänglighet, maximal service, vilket är en av de oumbärliga reglerna i databasvärlden.
Jag skulle också vilja nämna att många människor kanske ser Failover Cluster-teknologin som en lösning för Disaster Recovery, men det är den inte. Failover Cluster-teknik är inte en lösning för återställning av katastrofer, det är en teknik som endast ger hög tillgänglighet.
Vi kan lista lösningarna som erbjuds av SQL Server-databasen för hög tillgänglighet enligt följande.
- Failover-klustring
- Databasspegling
- Datareplikering
- Ögonblicksbild av databas
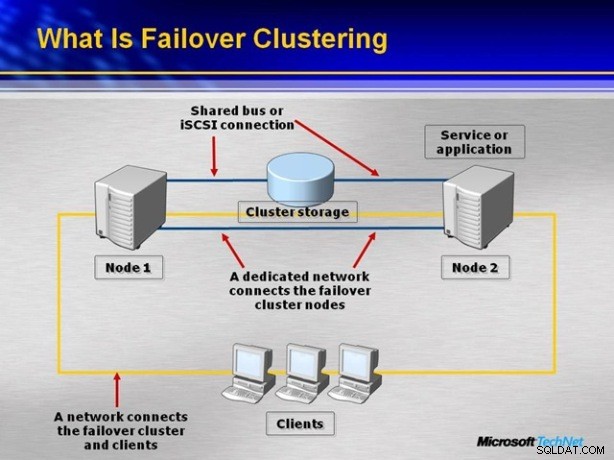
I Failover Cluster-arkitekturen är en av de två eller flera servrarna som är anslutna till varandra via Windows Cluster aktiv och den andra passiv. Om den aktiva servern inte kan tillhandahålla service i alla fall uppstår statusen Failover och den passiva noden aktiveras av Windows Cluster.
För att installera SQL Server Failover Cluster måste båda servrarna vara på Windows Cluster. På SQL Server-sidan är tjänsten som tillhandahåller Failover Cluster-arkitekturen Microsoft Cluster Service (MSCS). Båda servrarna har olika diskar, men det finns en delad disk där de databas- och klusterrelaterade filerna förvaras. Denna skiva är känd som Quorum Disk. Vi kan symbolisera Quorum Disk, som symboliserar det gemensamma diskutrymmet och är gemensamt för båda noderna, som visas i bilden nedan.
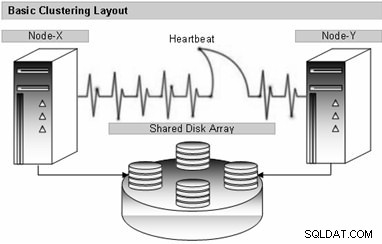
När applikationen har åtkomst till databasen, ansluter applikationen kontinuerligt databasen med kluster-IP:n inmatad utan att veta vilken av de aktiva passiva noderna som är. Cluster IP begär den för närvarande aktiva noden som är den nod som skickas till noden. När den aktiva noden är nere ansluts applikationen till den passiva noden på 1 sekund beroende på system och den påverkas inte. I det här fallet är den passiva noden aktiv och administratören kan redan göra failover manuellt när som helst.