SQLskills-teamet älskar väntestatistik. Om du tittar igenom inlägg på den här bloggen (se Pauls inlägg om Knee-Jerk Wait Statistics) och på SQLskills-webbplatsen, kommer du att se inlägg från oss alla som diskuterar värdet av väntestatistik, vad vi letar efter och varför en viss vänta är ett problem. Paul skriver mest om detta, men alla av oss börjar vanligtvis med väntestatistik när vi felsöker ett prestandaproblem. Vad betyder det när det gäller att vara proaktiv?
För att få en komplett bild av vad väntestatistik betyder under ett prestationsproblem måste du veta vad dina normala väntetider är. Det innebär att proaktivt fånga denna information och använda den baslinjen som referens. Om du inte har dessa data, när ett prestandaproblem uppstår, kommer du inte att veta om PAGELATCH-väntningar är typiska i din miljö (mycket möjligt) eller om du plötsligt har ett problem relaterat till tempdb på grund av någon ny kod som lades till .
Väntestatistikdata
Jag har tidigare publicerat ett manus som jag använder för att fånga väntestatistik, och det är ett manus som jag har använt länge för kunder. Men jag har nyligen gjort ändringar i mitt manus och justerat min metod något. Låt mig förklara varför...
Den grundläggande premissen bakom väntestatistik är att SQL Server spårar varje gång en tråd måste vänta på "något". Väntar du på att läsa en sida från disken? PAGEIOLATCH_XX vänta. Väntar du på att få ett lås så du gör en modifiering av data? LCX_M_XXX vänta. Väntar du på ett minnesanslag så att en fråga kan köras? RESOURCE_SEMAPHORE vänta. Alla dessa väntetider spåras i sys.dm_os_wait_stats DMV, och data samlas bara över tiden... det är en kumulativ representant för väntan.
Till exempel har jag en SQL Server 2014-instans i en av mina virtuella datorer som har varit uppe och sedan cirka 9:30 i morse:
SELECT [sqlserver_start_time] FROM [sys].[dm_os_sys_info];
 SQL-serverns starttid
SQL-serverns starttid
Om jag nu tittar för att se hur min väntestatistik ser ut (kom ihåg, kumulativ tills nu) med Pauls manus, ser jag att TRACEWRITE är min nuvarande "standard" väntan:
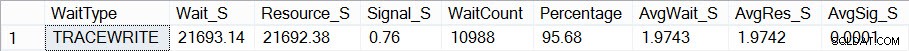 Aktuella sammanlagda väntetider
Aktuella sammanlagda väntetider
Ok, låt oss nu introducera fem minuters tempdb-strid och se hur det påverkar min totala väntestatistik. Jag har ett skript som Jonathan har använt tidigare för att skapa tempdb-strider, och jag har ställt in det så att det körs i 5 minuter:
USE AdventureWorks2012;
GO
SET NOCOUNT ON;
GO
DECLARE @CurrentTime SMALLDATETIME = SYSDATETIME(), @EndTime SMALLDATETIME = DATEADD(MINUTE, 5, SYSDATETIME());
WHILE @CurrentTime < @EndTime
BEGIN
IF OBJECT_ID('tempdb..#temp') IS NOT NULL
BEGIN
DROP TABLE #temp;
END
CREATE TABLE #temp
(
ProductID INT PRIMARY KEY,
OrderQty INT,
TotalDiscount MONEY,
LineTotal MONEY,
Filler NCHAR(500) DEFAULT(N'') NOT NULL
);
INSERT INTO #temp(ProductID, OrderQty, TotalDiscount, LineTotal)
SELECT
sod.ProductID,
SUM(sod.OrderQty),
SUM(sod.LineTotal),
SUM(sod.OrderQty + sod.UnitPriceDiscount)
FROM Sales.SalesOrderDetail AS sod
GROUP BY ProductID;
DECLARE
@ProductNumber NVARCHAR(25),
@Name NVARCHAR(50),
@TotalQty INT,
@SalesTotal MONEY,
@TotalDiscount MONEY;
SELECT
@ProductNumber = p.ProductNumber,
@Name = p.Name,
@TotalQty = t1.OrderQty,
@SalesTotal = t1.LineTotal,
@TotalDiscount = t1.TotalDiscount
FROM Production.Product AS p
JOIN #temp AS t1 ON p.ProductID = t1.ProductID;
SET @CurrentTime = SYSDATETIME()
END Jag använde en kommandotolk för att starta upp 10 sessioner som körde det här skriptet och körde samtidigt ett skript som fångade min totala väntestatistik, en ögonblicksbild av väntetiderna under en 5 minuters tidsperiod och sedan den övergripande väntestatistiken igen. Först, en liten hemlighet, eftersom vi ignorerar godartade väntetider hela tiden, kan det vara användbart att stoppa in dem i en tabell så att du kan referera till ett objekt istället för att hela tiden behöva hårdkoda en lista med uteslutningssträngar i en fråga. Så:
USE SQLskills_WaitStats; GO CREATE TABLE dbo.WaitsToIgnore(WaitType SYSNAME PRIMARY KEY); INSERT dbo.WaitsToIgnore(WaitType) VALUES(N'BROKER_EVENTHANDLER'), (N'BROKER_RECEIVE_WAITFOR'), (N'BROKER_TASK_STOP'), (N'BROKER_TO_FLUSH'), (N'BROKER_TRANSMITTER'), (N'CHECKPOINT_QUEUE'), (N'CHKPT'), (N'CLR_AUTO_EVENT'), (N'CLR_MANUAL_EVENT'), (N'CLR_SEMAPHORE'), (N'DBMIRROR_DBM_EVENT'), (N'DBMIRROR_EVENTS_QUEUE'), (N'DBMIRROR_WORKER_QUEUE'), (N'DBMIRRORING_CMD'), (N'DIRTY_PAGE_POLL'), (N'DISPATCHER_QUEUE_SEMAPHORE'), (N'EXECSYNC'), (N'FSAGENT'), (N'FT_IFTS_SCHEDULER_IDLE_WAIT'), (N'FT_IFTSHC_MUTEX'), (N'HADR_CLUSAPI_CALL'), (N'HADR_FILESTREAM_IOMGR_IOCOMPLETIO(N'), (N'HADR_LOGCAPTURE_WAIT'), (N'HADR_NOTIFICATION_DEQUEUE'), (N'HADR_TIMER_TASK'), (N'HADR_WORK_QUEUE'), (N'KSOURCE_WAKEUP'), (N'LAZYWRITER_SLEEP'), (N'LOGMGR_QUEUE'), (N'ONDEMAND_TASK_QUEUE'), (N'PWAIT_ALL_COMPONENTS_INITIALIZED'), (N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP'), (N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP'), (N'REQUEST_FOR_DEADLOCK_SEARCH'), (N'RESOURCE_QUEUE'), (N'SERVER_IDLE_CHECK'), (N'SLEEP_BPOOL_FLUSH'), (N'SLEEP_DBSTARTUP'), (N'SLEEP_DCOMSTARTUP'), (N'SLEEP_MASTERDBREADY'), (N'SLEEP_MASTERMDREADY'), (N'SLEEP_MASTERUPGRADED'), (N'SLEEP_MSDBSTARTUP'), (N'SLEEP_SYSTEMTASK'), (N'SLEEP_TASK'), (N'SLEEP_TEMPDBSTARTUP'), (N'SNI_HTTP_ACCEPT'), (N'SP_SERVER_DIAGNOSTICS_SLEEP'), (N'SQLTRACE_BUFFER_FLUSH'), (N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP'), (N'SQLTRACE_WAIT_ENTRIES'), (N'WAIT_FOR_RESULTS'), (N'WAITFOR'), (N'WAITFOR_TASKSHUTDOW(N'), (N'WAIT_XTP_HOST_WAIT'), (N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG'), (N'WAIT_XTP_CKPT_CLOSE'), (N'XE_DISPATCHER_JOIN'), (N'XE_DISPATCHER_WAIT'), (N'XE_TIMER_EVENT');
Nu är vi redo att fånga våra väntan:
/* Capture the instance start time
(in this case, time since waits have been accumulating) */
SELECT [sqlserver_start_time] FROM [sys].[dm_os_sys_info];
GO
/* Get the current time */
SELECT SYSDATETIME() AS [Before Test 1];
/* Get aggregate waits until now */
WITH [Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_Waits.WaitsToIgnore)
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
/* Get the current time */
SELECT SYSDATETIME() AS [Before Test 2];
/* Capture a snapshot of waits over a 5 minute period */
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
GO
WAITFOR DELAY '00:05:00';
GO
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
GO
WITH [DiffWaits] AS
(
SELECT -- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT -- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0
),
[Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
SELECT
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
-- Cleanup
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
/* Get the current time */
SELECT SYSDATETIME() AS [After Test 1];
/* Get aggregate waits again */
WITH [Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
/* Get the current time */
SELECT SYSDATETIME() AS [After Test 2]; Om vi tittar på utdata kan vi se att medan de 10 instanserna av skriptet för att skapa tempdb-konflikt kördes, var SOS_SCHEDULER_YIELD vår vanligaste väntetyp, och vi hade även PAGELATCH_XX väntar, som förväntat:
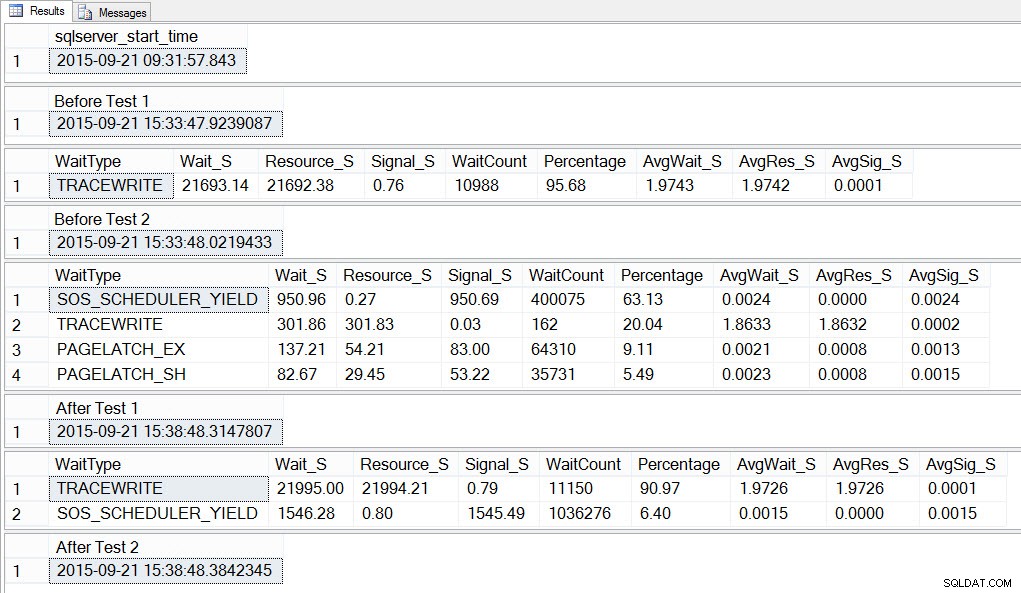
Om vi tittar på de genomsnittliga väntetiderna EFTER att testet slutförts, ser vi återigen TRACEWRITE som den högsta väntan, och vi ser SOS_SCHEDULER_YIELD som en väntan. Beroende på vad mer som körs i miljön, kan denna väntan kvarstå i våra toppväntningar under lång tid, och kanske bubbla upp som en väntetyp att undersöka.
Proaktivt fånga väntestatistik
Som standard är väntestatistiken kumulativ . Ja, du kan rensa dem när som helst med DBCC SQLPERF, men jag tycker att de flesta inte gör det regelbundet, de låter dem bara ackumuleras. Och det här är bra, men förstå hur det påverkar din data. Om du bara startar om din instans när du korrigerar den, eller när det finns ett problem (som förhoppningsvis händer sällan), kan den informationen ackumuleras i månader. Ju mer data du har, desto svårare är det att se små variationer... saker som kan vara prestandaproblem. Även när du har ett "stort problem" som påverkar hela din server i flera minuter, som vi gjorde här med tempdb, kan det hända att det inte skapar tillräckligt med förändringar i dina data för att upptäckas i den ackumulerade informationen. Istället måste du ta en ögonblicksbild av data (fånga in den, vänta några minuter, fånga den igen och sedan differentiera data) för att se vad som verkligen händer just nu .
Som sådan, om du bara tar en ögonblicksbild av väntestatistik med några timmars mellanrum, visar data du har samlat in bara den fortsatta aggregeringen över tiden. Du kan differentiera dessa ögonblicksbilder för att få en förståelse för prestanda mellan ögonblicksbilderna, men jag kan säga att du måste skriva den här koden mot en stor datamängd, det är jobbigt (men jag är inte en utvecklare, så det kanske är lätt för dig ).
Min traditionella metod för att fånga väntestatistik var att bara ta en ögonblicksbild av sys.dm_os_wait_stats med några timmars mellanrum med Pauls ursprungliga skript:
USE [BaselineData];
GO
IF NOT EXISTS (SELECT * FROM [sys].[tables] WHERE [name] = N'SQLskills_WaitStats_OldMethod')
BEGIN
CREATE TABLE [dbo].[SQLskills_WaitStats_OldMethod]
(
[RowNum] [bigint] IDENTITY(1,1) NOT NULL,
[CaptureDate] [datetime] NULL,
[WaitType] [nvarchar](120) NULL,
[Wait_S] [decimal](14, 2) NULL,
[Resource_S] [decimal](14, 2) NULL,
[Signal_S] [decimal](14, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](4, 2) NULL,
[AvgWait_S] [decimal](14, 4) NULL,
[AvgRes_S] [decimal](14, 4) NULL,
[AvgSig_S] [decimal](14, 4) NULL
);
CREATE CLUSTERED INDEX [CI_SQLskills_WaitStats_OldMethod]
ON [dbo].[SQLskills_WaitStats_OldMethod] ([CaptureDate],[RowNum]);
END
GO
/* Query to use in scheduled job */
USE [BaselineData];
GO
INSERT INTO [dbo].[SQLskills_WaitStats_OldMethod]
(
[CaptureDate] ,
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
EXEC ('WITH [Waits] AS (SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
SELECT
GETDATE(),
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL(14, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL(14, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL(14, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL(4, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS], [W1].[ResourceS],
[W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95;'
); Jag skulle sedan gå igenom och titta på den övre väntan för varje ögonblicksbild, till exempel:
SELECT [w].[CaptureDate] , [w].[WaitType] , [w].[Percentage] , [w].[Wait_S] , [w].[WaitCount] , [w].[AvgWait_S] FROM [dbo].[SQLskills_WaitStats_OldMethod] w JOIN ( SELECT MIN([RowNum]) AS [RowNumber] , [CaptureDate] FROM [dbo].[SQLskills_WaitStats_OldMethod] WHERE [CaptureDate] IS NOT NULL AND [CaptureDate] > GETDATE() - 60 GROUP BY [CaptureDate] ) m ON [w].[RowNum] = [m].[RowNumber] ORDER BY [w].[CaptureDate];
Min nya, alternativa metod är att variera ett par ögonblicksbilder av väntestatistik (med två till tre minuter mellan ögonblicksbilder) varje timme eller så. Denna information berättar sedan exakt vad systemet väntade på vid den tiden:
USE [BaselineData];
GO
IF NOT EXISTS ( SELECT * FROM [sys].[tables] WHERE [name] = N'SQLskills_WaitStats')
BEGIN
CREATE TABLE [dbo].[SQLskills_WaitStats]
(
[RowNum] [bigint] IDENTITY(1,1) NOT NULL,
[CaptureDate] [datetime] NOT NULL DEFAULT (sysdatetime()),
[WaitType] [nvarchar](60) NOT NULL,
[Wait_S] [decimal](16, 2) NULL,
[Resource_S] [decimal](16, 2) NULL,
[Signal_S] [decimal](16, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](5, 2) NULL,
[AvgWait_S] [decimal](16, 4) NULL,
[AvgRes_S] [decimal](16, 4) NULL,
[AvgSig_S] [decimal](16, 4) NULL
) ON [PRIMARY];
CREATE CLUSTERED INDEX [CI_SQLskills_WaitStats]
ON [dbo].[SQLskills_WaitStats] ([CaptureDate],[RowNum]);
END
/* Query to use in scheduled job */
USE [BaselineData];
GO
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
/* Capture wait stats */
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
GO
/* Wait some amount of time */
WAITFOR DELAY '00:02:00';
GO
/* Capture wait stats again */
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
GO
/* Diff the waits */
WITH [DiffWaits] AS
(
SELECT -- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT -- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0
),
[Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
INSERT INTO [BaselineData].[dbo].[SQLskills_WaitStats]
(
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
SELECT
[W1].[wait_type],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) ,
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) ,
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) ,
[W1].[WaitCount] ,
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) ,
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) ,
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) ,
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4))
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS], [W1].[ResourceS],
[W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
/* Clean up the temp tables */
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2]; Är min nya metod bättre? Jag tror det, eftersom det är en bättre representation av hur väntetiderna ser ut vid tidpunkten för fångst, och det provtas fortfarande med jämna mellanrum. För båda metoderna tittar jag vanligtvis för att se vad den högsta väntetiden var vid tidpunkten för fångst:
SELECT [w].[CaptureDate] , [w].[WaitType] , [w].[Percentage] , [w].[Wait_S] , [w].[WaitCount] , [w].[AvgWait_S] FROM [dbo].[SQLskills_WaitStats] w JOIN ( SELECT MIN([RowNum]) AS [RowNumber], [CaptureDate] FROM [dbo].[SQLskills_WaitStats] WHERE [CaptureDate] > GETDATE() - 30 GROUP BY [CaptureDate] ) m ON [w].[RowNum] = [m].[RowNumber] ORDER BY [w].[CaptureDate];
Resultat:
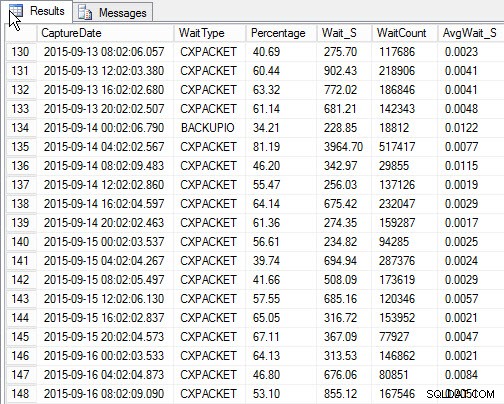 Topp vänta på varje ögonblicksbild (exempelutdata)
Topp vänta på varje ögonblicksbild (exempelutdata)
Nackdelen, som fanns med mitt originalmanus, är att det fortfarande bara är en ögonblicksbild . Jag kan trenda de högsta väntetiderna över tid, men om det finns ett problem som uppstår mellan ögonblicksbilderna kommer det inte att dyka upp. Så vad kan du göra?
Du kan öka frekvensen av dina fångster. Kanske istället för att fånga väntestatistik varje timme, fångar du den var 15:e minut. Eller kanske var tionde. Ju oftare du samlar in data, desto större chans har du att fånga ett prestandaproblem.
Ditt andra alternativ skulle vara att använda en tredjepartsapplikation, som SQL Sentry Performance Advisor, för att övervaka väntetider. Performance Advisor hämtar exakt samma information från sys.dm_os_wait_stats DMV. Den frågar sys.dm_os_wait_stats var 10:e sekund med en mycket enkel fråga:
SELECT * FROM sys.dm_os_wait_stats WHERE wait_time_ms > 0;
Bakom kulisserna tar Performance Advisor sedan denna data och lägger till den i sin övervakningsdatabas. När du ser data tas godartade väntetider bort och deltan beräknas åt dig. Dessutom har Performance Advisor en fantastisk display (att titta på instrumentpanelen är mycket snyggare än textutmatningen ovan) och du kan anpassa samlingen om du vill. Om vi tittar på Performance Advisor och tittar på data från hela dagen kan jag enkelt se var jag hade ett problem i SQL Server Waits-rutan:
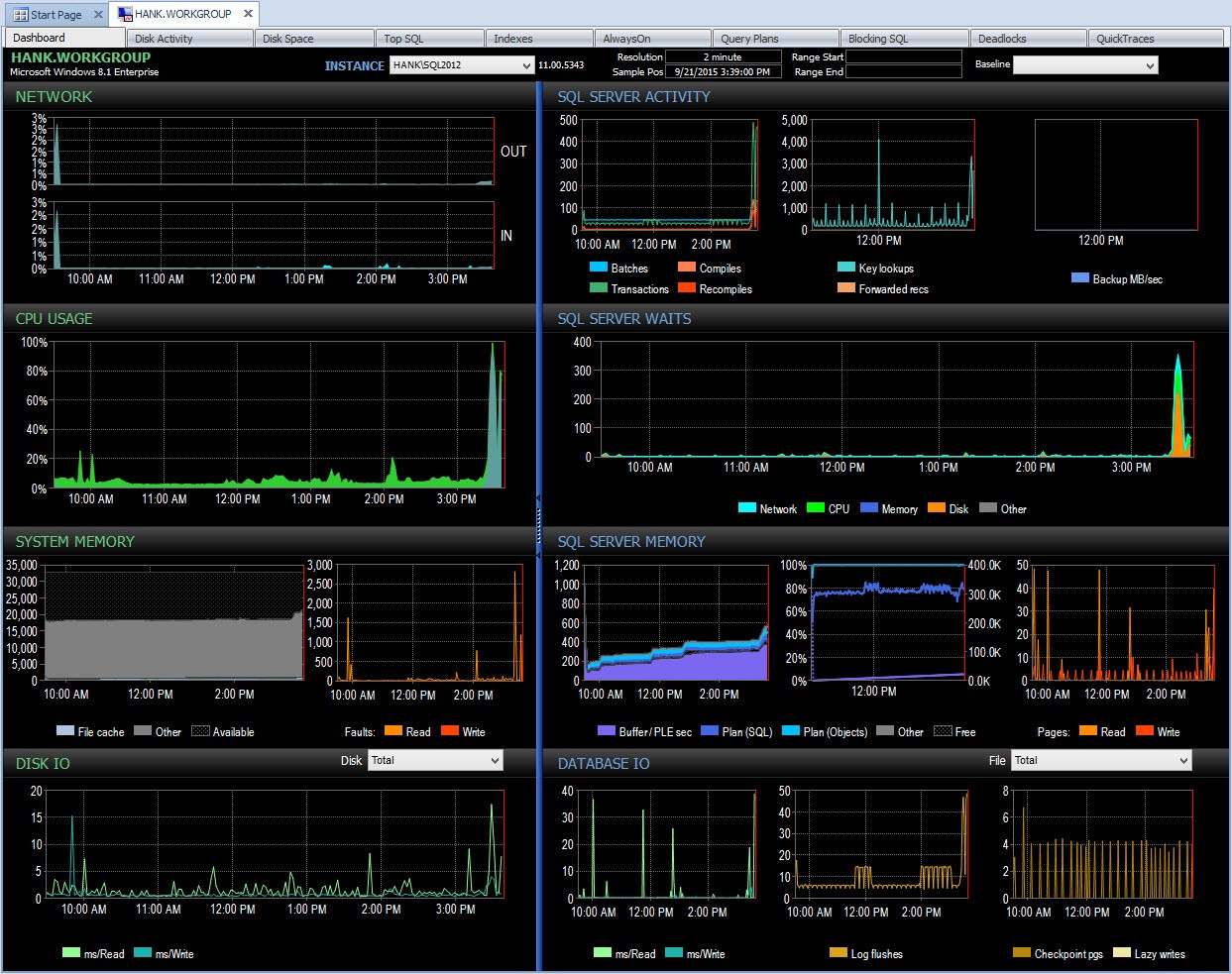 Performance Advisor Dashboard för dagen
Performance Advisor Dashboard för dagen
Och jag kan sedan gå in i den tidsperioden efter 15:00 för att ytterligare undersöka vad som hände:
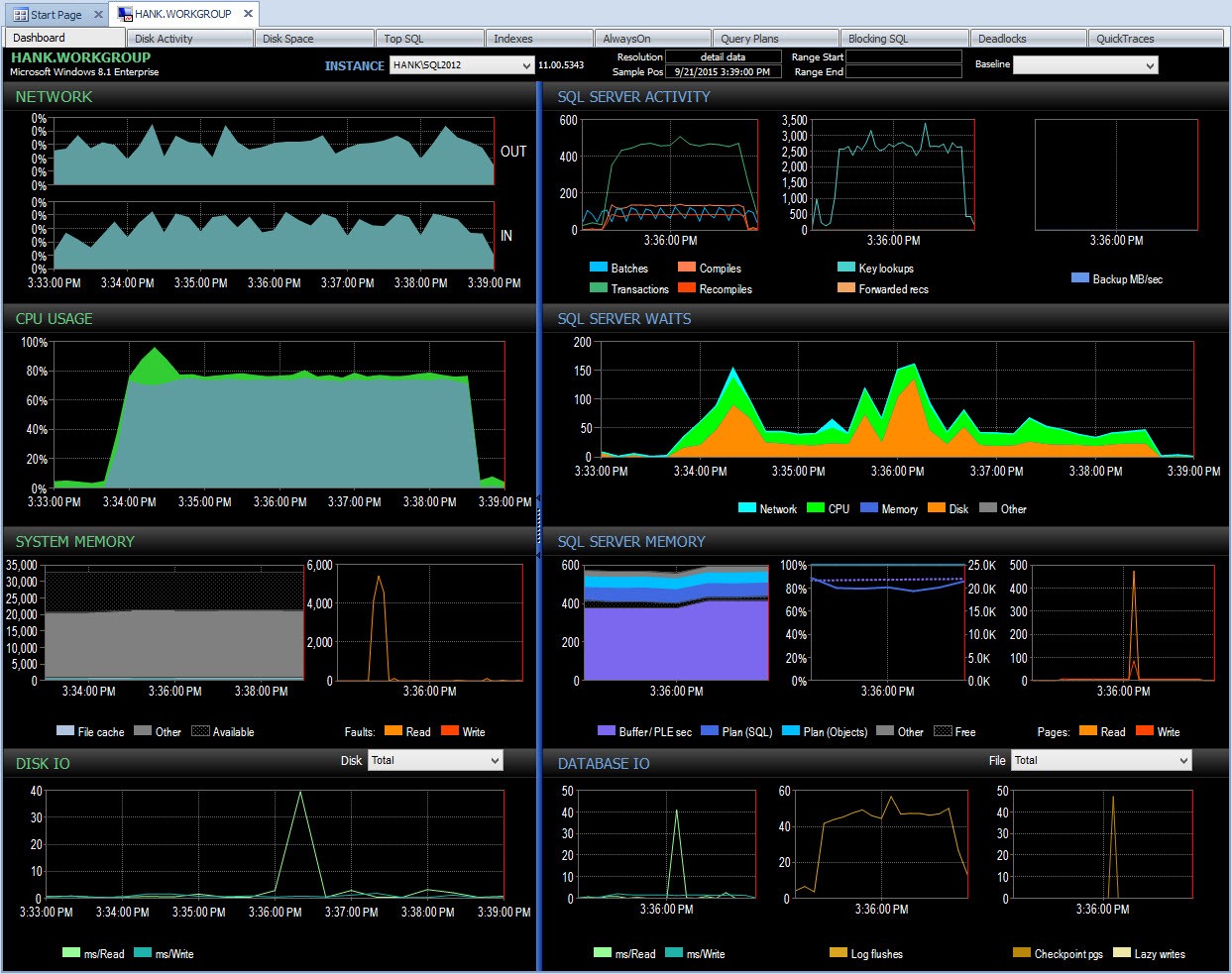 Drill ner i PA under prestandaproblem
Drill ner i PA under prestandaproblem
Övervakning på egen hand, såvida jag inte råkade ta en ögonblicksbild av väntestatistik samtidigt med ett skript, kommer jag att ha missat att fånga all data om det prestandaproblemet. Eftersom Performance Advisor lagrar informationen under en längre tidsperiod, om du har en störning i prestanda, gör ha väntestatistikdata (tillsammans med mycket annan information) tillgänglig för att hjälpa till att undersöka problemet, och du har också historiska data så att du förstår vilka normala väntetider som finns i din miljö.
Sammanfattning
Vilken metod du än väljer för att övervaka väntetider, är det först viktigt att förstå hur SQL Server lagrar vänteinformation så att du förstår den data du ser om du fångar den regelbundet. Om du måste rulla dina egna skript för att fånga väntetider, är du begränsad genom att du kanske inte fångar avvikelser lika enkelt som du kunde med programvara från tredje part. Men det är ok – att ha en viss mängd baslinjedata så att du kan börja förstå vad som är "normalt" är bättre än att inte ha något alls . När du bygger ditt arkiv och börjar bli bekant med en miljö, kan du skräddarsy dina insamlingsskript efter behov för att lösa eventuella problem som kan finnas. Om du har nytta av programvara från tredje part, använd den informationen till fullo och se till att du förstår hur väntetider samlas in och lagras.