I den första delen av den här serien introducerade jag grundläggande terminologi kring loggning, så jag rekommenderar att du läser det innan du fortsätter med det här inlägget. Allt annat jag kommer att täcka i serien kräver att jag känner till en del av transaktionsloggens arkitektur, så det är vad jag kommer att diskutera den här gången. Även om du inte kommer att följa serien, är några av koncepten som jag ska förklara nedan värda att känna till för vardagliga uppgifter som DBA:er hanterar i produktionen.
Strukturell hierarki
Transaktionsloggen är internt organiserad med hjälp av en trenivåhierarki som visas i figur 1 nedan.
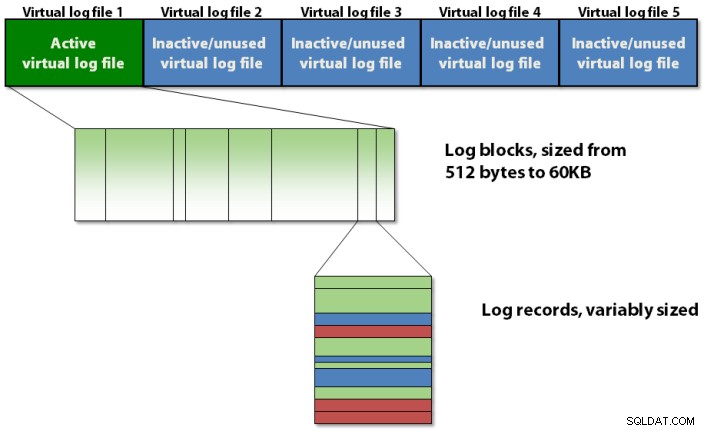 Figur 1:Den strukturella hierarkin på tre nivåer för transaktionsloggen
Figur 1:Den strukturella hierarkin på tre nivåer för transaktionsloggen
Transaktionsloggen innehåller virtuella loggfiler, som innehåller loggblock, som lagrar de faktiska loggposterna.
Virtuella loggfiler
Transaktionsloggen är uppdelad i sektioner som kallas virtuella loggfiler , vanligtvis bara kallad VLFs . Detta görs för att göra hanteringen av operationer i transaktionsloggen enklare för logghanteraren i SQL Server. Du kan inte ange hur många VLF:er som skapas av SQL Server när databasen först skapas eller loggfilen växer automatiskt, men du kan påverka den. Algoritmen för hur många VLF som skapas är följande:
- Loggfilstorlek mindre än 64 MB:skapa 4 VLF:er, var och en ungefär 16 MB i storlek
- Loggfilstorlek från 64 MB till 1 GB :skapa 8 VLF:er, var och en ungefär 1/8 av den totala storleken
- Loggfilstorlek större än 1 GB:skapa 16 VLF:er, var och en ungefär 1/16 av den totala storleken
Före SQL Server 2014, när loggfilen växer automatiskt, bestäms antalet nya VLF:er som läggs till i slutet av loggfilen av algoritmen ovan, baserat på storleken för automatisk tillväxt. Men med den här algoritmen, om storleken för automatisk tillväxt är liten och loggfilen genomgår många automatiska tillväxter, kan det leda till ett mycket stort antal små VLF:er (kalladVLF-fragmentering ) som kan vara ett stort prestandaproblem för vissa operationer (se här).
På grund av detta problem ändrades algoritmen i SQL Server 2014 för automatisk tillväxt av loggfilen. Om den automatiska odlingsstorleken är mindre än 1/8 av den totala loggfilens storlek, skapas endast en ny VLF, annars används den gamla algoritmen. Detta minskar drastiskt antalet VLF:er för en loggfil som har genomgått en stor mängd auto-tillväxt. Jag förklarade ett exempel på skillnaden i det här blogginlägget.
Varje VLF har ett sekvensnummer som unikt identifierar den och används på en mängd olika platser, vilket jag kommer att förklara nedan och i framtida inlägg. Man skulle kunna tro att sekvensnumren skulle börja på 1 för en helt ny databas, men så är inte fallet.
På en SQL Server 2019-instans skapade jag en ny databas, utan att ange några filstorlekar, och kontrollerade sedan VLF:erna med koden nedan:
CREATE DATABASE NewDB;
GO
SELECT
[file_id],
[vlf_begin_offset],
[vlf_size_mb],
[vlf_sequence_number]
FROM
sys.dm_db_log_info (DB_ID (N'NewDB'));
Notera sys.dm_db_log_info DMV lades till i SQL Server 2016 SP2. Innan dess (och idag, eftersom det fortfarande finns) kan du använda den odokumenterade DBCC LOGINFO kommandot, men du kan inte ge det en vallista – gör bara DBCC LOGINFO(N'NewDB'); och VLF-sekvensnumren finns i FSeqNo kolumnen i resultatuppsättningen.
Hur som helst, resultaten från att fråga sys.dm_db_log_info var:
file_id vlf_begin_offset vlf_size_mb vlf_sequence_number ------- ---------------- ----------- ------------------- 2 8192 1.93 37 2 2039808 1.93 0 2 4071424 1.93 0 2 6103040 2.17 0
Notera att den första VLF:en startar vid offset 8 192 byte i loggfilen. Detta beror på att alla databasfiler, inklusive transaktionsloggen, har en filhuvudsida som tar upp de första 8KB och lagrar olika metadata om filen.
Så varför väljer SQL Server 37 och inte 1 för det första VLF-sekvensnumret? Den hittar det högsta VLF-sekvensnumret i modellen databas och sedan, för en ny databas, använder transaktionsloggens första VLF det numret plus 1 för sitt sekvensnummer. Jag vet inte varför den här algoritmen valdes tillbaka i tidens dimmor, men det har varit så sedan åtminstone SQL Server 7.0.
För att bevisa det körde jag den här koden:
SELECT
MAX ([vlf_sequence_number]) AS [Max_VLF_SeqNo]
FROM
sys.dm_db_log_info (DB_ID (N'model')); Och resultaten var:
Max_VLF_SeqNo -------------------- 36
Så där har du det.
Det finns mer att diskutera om VLF:er och hur de används, men för närvarande räcker det att veta att varje VLF har ett sekvensnummer, som ökar med ett för varje VLF.
Loggblock
Varje VLF innehåller en liten metadatarubrik, och resten av utrymmet är fyllt med loggblock. Varje loggblock börjar med 512 byte och kommer att växa i steg om 512 byte till en maximal storlek på 60KB, då det måste skrivas till disken. Ett loggblock kan skrivas till disken innan det når sin maximala storlek om något av följande inträffar:
- En transaktion begår och fördröjd hållbarhet används inte för denna transaktion, så loggblocket måste skrivas till disken för att göra transaktionen hållbar
- Fördröjd hållbarhet används, och bakgrunden "spola det aktuella loggblocket till disken" 1ms timeruppgift avfyras
- En datafilsida skrivs till disken av en kontrollpunkt eller den lata skrivaren, och det finns en eller flera loggposter i det aktuella loggblocket som påverkar sidan som ska skrivas (kom ihåg att framskrivningsloggning måste vara garanterat)
Du kan betrakta ett loggblock som något som en sida med variabel storlek som lagrar loggposter i den ordning de skapas av transaktioner som ändrar databasen. Det finns inte ett loggblock för varje transaktion; loggposterna för flera samtidiga transaktioner kan blandas i ett loggblock. Du kanske tror att det här skulle innebära svårigheter för operationer som behöver hitta alla loggposter för en enskild transaktion, men det gör det inte, som jag kommer att förklara när jag tar upp hur återställning av transaktioner fungerar i ett senare inlägg.
Dessutom, när ett loggblock skrivs till disken, är det fullt möjligt att det innehåller loggposter från icke-engagerade transaktioner. Detta är inte heller ett problem på grund av hur kraschåterställning fungerar – vilket är ett par inlägg i seriens framtid.
Loggsekvensnummer
Loggblock har ett ID inom en VLF, som börjar vid 1 och ökar med 1 för varje nytt loggblock i VLF. Loggposter har också ett ID inom ett loggblock, som börjar med 1 och ökar med 1 för varje ny loggpost i loggblocket. Så alla tre element i transaktionsloggens strukturella hierarki har ett ID, och de dras samman till en tredelad identifierare som kallas loggsekvensnummer , mer vanligen kallad LSN .
Ett LSN definieras som
Grundarbete klart!
Även om VLF:er är viktiga att känna till, är enligt min åsikt LSN det viktigaste konceptet att förstå kring SQL Servers implementering av loggning, eftersom LSN:er är hörnstenen på vilken transaktionsåterställning och kraschåterställning byggs, och LSN:er kommer att dyka upp om och om igen som Jag går vidare genom serien. I nästa inlägg kommer jag att täcka loggavkortning och transaktionsloggens cirkulära karaktär, vilket helt och hållet har att göra med VLF:er och hur de återanvänds.