Jag har en 50 % lösning för dig.
Problemet
SSIS verkligen bryr sig om metadata så variationer i den tenderar att resultera i undantag. DTS var mycket mer förlåtande i denna mening. Det stora behovet av konsekvent metadata gör användningen av den platta filkällan besvärlig.
Frågebaserad lösning
Om problemet är komponenten, låt oss inte använda den. Det jag gillar med det här tillvägagångssättet är att konceptuellt är det samma sak som att fråga efter en tabell - kolumnernas ordning spelar ingen roll och inte heller förekomsten av extra kolumner.
Variabler
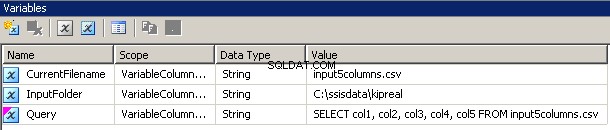
Jag skapade 3 variabler, alla av typen sträng:CurrentFileName, InputFolder och Query.
- InputFolder är fastanslutet till källmappen. I mitt exempel är det
C:\ssisdata\Kipreal - CurrentFileName är namnet på en fil. Under designtiden var det
input5columns.csvmen det kommer att ändras under körning. - Fråga är ett uttryck
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
Anslutningshanterare
Konfigurera en anslutning till indatafilen med JET OLEDB-drivrutinen. Efter att ha skapat den enligt beskrivningen i den länkade artikeln döpte jag om den till FileOLEDB och satte ett uttryck på ConnectionManager för "Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";"
Kontrollflöde
Mitt kontrollflöde ser ut som en dataflödesuppgift kapslad i en Foreach-filuppräkning
Foreach File Enumerator
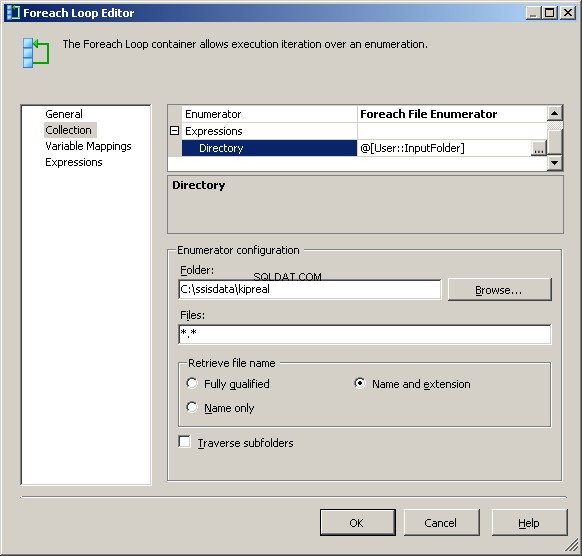
My Foreach File Enumerator är konfigurerad att arbeta på filer. Jag lägger ett uttryck i katalogen för @[User::InputFolder] Observera att vid det här laget, om värdet på den mappen behöver ändras, kommer den att uppdateras korrekt i både anslutningshanteraren och filuppräkningen. I "Hämta filnamn" istället för standardinställningen "Fullständigt kvalificerad", välj "Namn och tillägg"
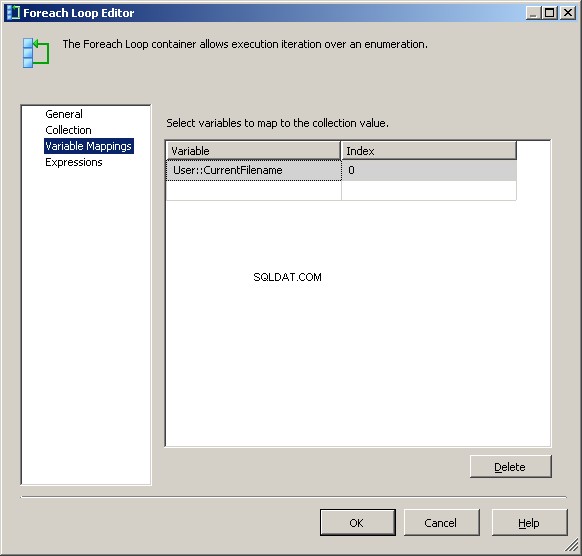
Tilldela värdet till vår @[User::CurrentFileName] på fliken Variable Mappings. variabel
Vid denna tidpunkt kommer varje iteration av loopen att ändra värdet på @[User::Query för att återspegla det aktuella filnamnet.
Dataflöde
Detta är faktiskt den enklaste biten. Använd en OLE DB-källa och koppla den enligt anvisningarna.
Använd FileOLEDB-anslutningshanteraren och ändra dataåtkomstläget till "SQL-kommando från variabel." Använd @[User::Query] variabel där, klicka på OK och du är redo att arbeta. 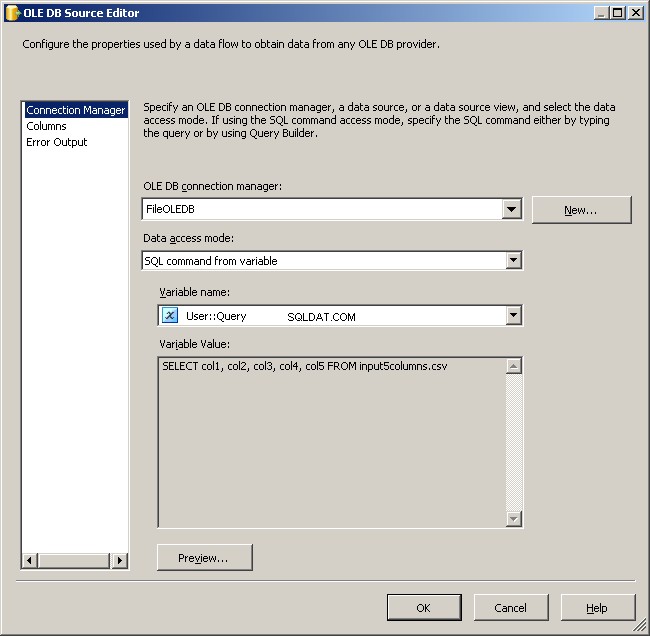
Exempel på data
Jag skapade två exempelfiler input5columns.csv och input7columns.csv Alla kolumner av 5 är i 7 men 7 har dem i en annan ordning (col2 är ordningsposition 2 och 6). Jag negerade alla värden i 7 för att göra det lätt uppenbart vilken fil som opereras på.
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
och
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
Att köra paketet resulterar i dessa två skärmbilder
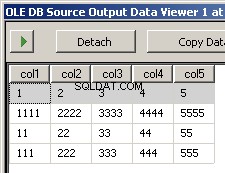
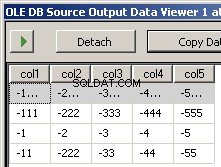
Vad saknas
Jag vet inte om något sätt att tala om för den frågebaserade metoden att det är OK om en kolumn inte finns. Om det finns en unik nyckel antar jag att du kan definiera din fråga så att den bara har de kolumner som måste vara där och sedan utföra uppslagningar mot filen för att försöka få fram de kolumner som borde att vara där och inte misslyckas med uppslagningen om kolumnen inte finns. Ganska klumpig dock.