Att lagra ~3,5 TB data och infoga cirka 1K/sek 24x7, och även fråga med en hastighet som inte anges, det är möjligt med SQL Server, men det finns fler frågor:
- vilka tillgänglighetskrav har du för detta? 99,999 % drifttid, eller räcker 95 %?
- vilka tillförlitlighetskrav har du? Kostar det dig 1 miljoner USD om du saknar en insats?
- vilka återvinningskrav har du? Om du tappar en dags data, spelar det någon roll?
- vilka konsekvenskrav har du? Behöver en skrivning garanteras vara synlig vid nästa läsning?
Om du behöver alla dessa krav som jag lyfte fram, kommer belastningen du föreslår att kosta miljoner i hårdvara och licensiering på ett relationssystem, vilket system som helst, oavsett vilka jippon du försöker (skärning, partitionering etc). Ett nosql-system skulle, enligt själva definitionen, inte uppfylla alla dessa krav.
Så uppenbarligen har du redan lättat på några av dessa krav. Det finns en trevlig visuell guide som jämför nosql-erbjudandena baserat på "välj 2 av 3"-paradigmet på Visual Guide to NoSQL Systems:
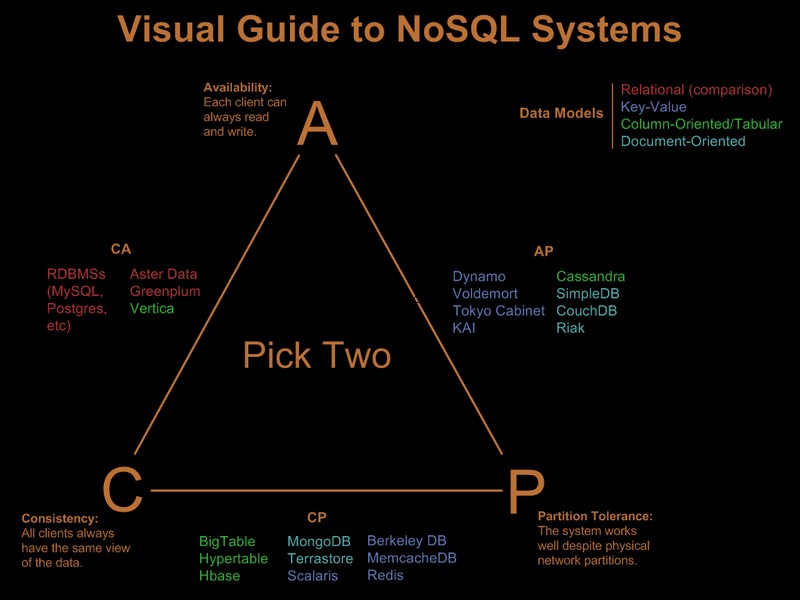
Efter OP-kommentaruppdatering
Med SQL Server skulle detta vara en enkel implementering:
- en enda tabellnyckel (GUID, tid). Ja, kommer att bli fragmenterad, men är fragmentering påverkar läs framåt och läs framåt behövs bara för betydande avståndsskanningar. Eftersom du bara frågar efter specifik GUID och datumintervall kommer fragmentering inte att spela någon större roll. Ja, är en bred nyckel, så sidor utan blad kommer att ha dålig nyckeldensitet. Ja, det kommer att leda till dålig fyllningsfaktor. Och ja, siddelningar kan förekomma. Trots dessa problem, med tanke på kraven, är fortfarande det bästa klustrade nyckelvalet.
- partitionera tabellen efter tid så att du kan implementera effektiv radering av utgångna poster via ett automatiskt skjutfönster. Förstärk detta med en online-indexpartition som återuppbyggdes den senaste månaden för att eliminera den dåliga fyllningsfaktorn och fragmenteringen som introducerades av GUID-klustringen.
- aktivera sidkomprimering. Eftersom de klustrade nyckelgrupperna först efter GUID, kommer alla poster i ett GUID att ligga bredvid varandra, vilket ger sidkomprimering en god chans att distribuera ordbokskomprimering.
- du behöver en snabb IO-sökväg för loggfilen. Du är intresserad av hög genomströmning, inte med låg latens för att en logg ska kunna hålla jämna steg med 1K-inlägg/sekund, så strippning är ett måste.
Partitionering och sidkomprimering kräver var och en en Enterprise Edition SQL Server, de fungerar inte på Standard Edition och båda är ganska viktiga för att uppfylla kraven.
Som en sidoanteckning, om posterna kommer från en front-end webbserverfarm, skulle jag lägga Express på varje webbserver och istället för INSERT på baksidan, skulle jag SEND informationen till baksidan, med hjälp av en lokal anslutning/transaktion på Expressen samlokaliserad med webbservern. Detta ger en mycket mycket bättre tillgänglighetshistoria till lösningen.
Så här är hur jag skulle göra det i SQL Server. Den goda nyheten är att de problem du kommer att möta är väl förstådda och lösningarna är kända. det betyder inte nödvändigtvis att detta är bättre än vad du kan uppnå med Cassandra, BigTable eller Dynamo. Jag låter någon som är mer kunnig i saker som inte är SQL-ish att argumentera för sin sak.
Observera att jag aldrig nämnde programmeringsmodellen, .Net-stöd och så. Jag tror ärligt talat att de är irrelevanta i stora utbyggnader. De gör enorm skillnad i utvecklingsprocessen, men när de väl har implementerats spelar det ingen roll hur snabb utvecklingen var, om ORM-overheaden dödar prestandan :)