Ett exempel där detta kan göra skillnad är att det kan förhindra en prestandaoptimering som undviker att lägga till radversionsinformation i tabeller med efterutlösare.
Detta täcks av Paul White här
Den faktiska storleken på data som lagras är oväsentlig – det är potentialstorleken som spelar roll.
På samma sätt om man använder minnesoptimerade tabeller sedan 2016 har det varit möjligt att använda LOB-kolumner eller kombinationer av kolumnbredder som potentiellt skulle kunna överskrida inrow-gränsen men med en straffavgift.
(Max) kolumner lagras alltid utanför rad. För andra kolumner, om dataradstorleken i tabelldefinitionen kan överstiga 8 060 byte, skickar SQL Server de största kolumnerna med variabel längd utanför raden. Återigen, det beror inte på mängden data du lagrar där.
Detta kan ha en stor negativ effekt på minnesförbrukning och prestanda
Ett annat fall där överdeklarering av kolumnbredder kan göra stor skillnad är om tabellen någonsin kommer att bearbetas med SSIS. Minnet som allokeras för kolumner med variabel längd (icke BLOB) är fixerat för varje rad i ett exekveringsträd och är enligt kolumnernas deklarerade maximala längd, vilket kan leda till ineffektiv användning av minnesbuffertar (exempel). Även om SSIS-paketutvecklaren kan deklarera en mindre kolumnstorlek än källan görs denna analys bäst i förväg och tillämpas där.
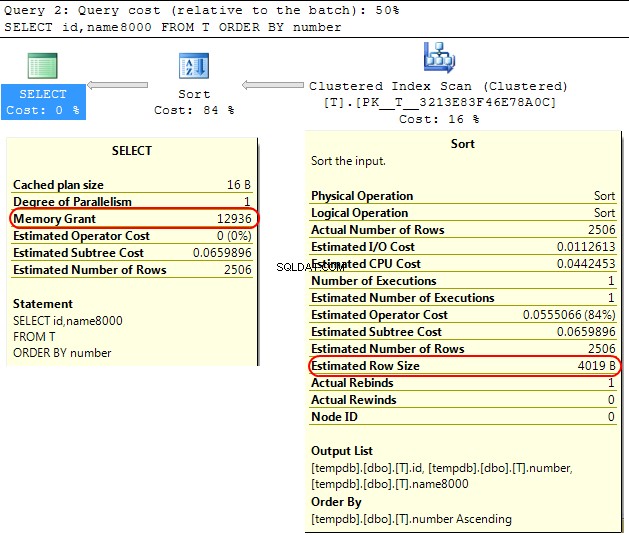
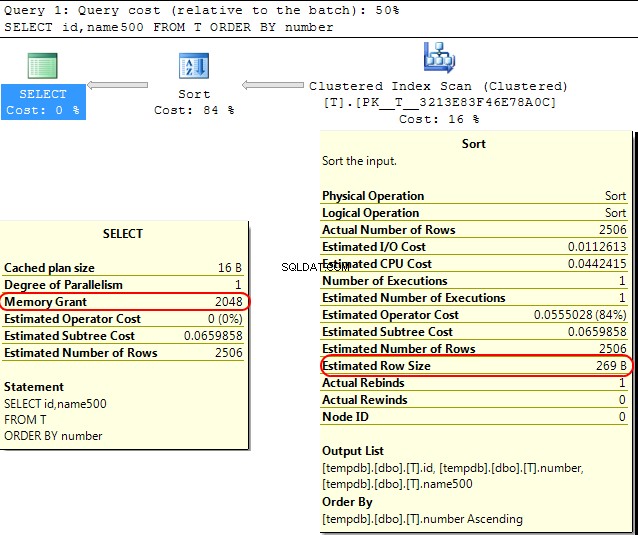
Tillbaka i själva SQL Server-motorn är ett liknande fall att när man beräknar minnesanslaget att allokera för SORT operationer SQL Server antar att varchar(x) kolumner kommer i genomsnitt att förbruka x/2 byte.
Om de flesta av dina varchar kolumner är fylligare än så, detta kan leda till sort operationer som spills till tempdb .
I ditt fall om din varchar kolumner deklareras som 8000 byte men har faktiskt innehåll mycket mindre än att din fråga kommer att tilldelas minne som den inte kräver, vilket är uppenbart ineffektivt och kan leda till väntan på minnesanslag.
Detta tas upp i del 2 av SQL Workshops Webcast 1 som kan laddas ner härifrån eller se nedan.
use tempdb;
CREATE TABLE T(
id INT IDENTITY(1,1) PRIMARY KEY,
number int,
name8000 VARCHAR(8000),
name500 VARCHAR(500))
INSERT INTO T
(number,name8000,name500)
SELECT number, name, name /*<--Same contents in both cols*/
FROM master..spt_values
SELECT id,name500
FROM T
ORDER BY number
SELECT id,name8000
FROM T
ORDER BY number