Tabellindexeringsstrategi är en av de viktigaste nycklarna för prestandajustering och optimering. I SQL Server skapas indexen (både, klustrade och icke-klustrade) med hjälp av en B-trädstruktur, där varje sida fungerar som en dubbellänkad listnod, med information om föregående och nästa sida. Denna B-trädstruktur, kallad Forward Scan, gör det lättare att läsa raderna från indexet genom att skanna eller söka dess sidor från början till slutet. Även om framåtsökningen är standard och mycket känd metod för indexskanning, ger SQL Server oss möjligheten att skanna indexraderna i B-trädstrukturen från slutet till början. Denna förmåga kallas bakåtsökning. I den här artikeln kommer vi att se hur detta händer och vad är för- och nackdelarna med bakåtsökningsmetoden.
SQL Server ger oss möjligheten att läsa data från tabellindexet genom att skanna indexets B-trädstrukturnoder från början till slutet med metoden Forward Scan, eller läsa B-trädstrukturnoderna från slutet till början med hjälp av Bakåtsökningsmetod. Som namnet indikerar utförs bakåtsökningen medan man läser motsatt ordningen för kolumnen som ingår i indexet, vilket utförs med alternativet DESC i sorteringssatsen ORDER BY T-SQL, som anger riktningen för skanningsoperationen.
I specifika situationer upptäcker SQL Server Engine att läsning av indexdata från slutet till början med bakåtsökningsmetoden är snabbare än att läsa den i sin normala ordning med sökningsmetoden framåt, vilket kan kräva en dyr sorteringsprocess av SQL Motor. Sådana fall inkluderar användningen av MAX() aggregatfunktionen och situationer när sorteringen av frågeresultatet är motsatt av indexordningen. Den största nackdelen med bakåtsökningsmetoden är att SQL Server Query Optimizer alltid väljer att köra den med seriell planexekvering, utan att kunna dra fördelar av de parallella exekveringsplanerna.
Antag att vi har följande tabell som kommer att innehålla information om företagets anställda. Tabellen kan skapas med CREATE TABLE T-SQL-satsen nedan:
SKAPA TABELL [dbo].[Företagsanställda]( [ID] [INT] IDENTITET (1,1) , [EmpID] [int] INTE NULL, [Emp_First_Name] [nvarchar](50) NULL, [Emp_Last_Name] [ nvarchar](50) NULL, [EmpDepID] [int] NOT NULL, [Emp_Status] [int] NOT NULL, [EMP_PhoneNumber] [nvarchar](50) NULL, [Emp_Adress] [nvarchar](max) NULL, [Emp_EmploymentDate] [DATETIME] NULL,PRIMÄRNYCKEL KLUNDERAD ( [ID] ASC)PÅ [PRIMÄR]))
Efter att ha skapat tabellen kommer vi att fylla den med 10K dummy-poster, med hjälp av INSERT-satsen nedan:
INSERT INTO [dbo].[Företagsanställda] ([EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status],[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_Emp_Em,[Emp_Emp_Em]' AAA','BBB',4,1,9624488779,'AMM','2006-10-15')GO 10000
Om vi kör nedanstående SELECT-sats för att hämta data från den tidigare skapade tabellen, kommer raderna att sorteras enligt ID-kolumnvärdena i stigande ordning, det vill säga samma ordning som den klustrade indexordningen:
VÄLJ [ID] ,[Emp_ID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status],[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] FRÅN [SQLShackDeployemoE] ] BESTÄLL AV [ID] ASC
När du sedan kontrollerar exekveringsplanen för den frågan, kommer en skanning att utföras på det klustrade indexet för att få sorterad data från indexet som visas i exekveringsplanen nedan:
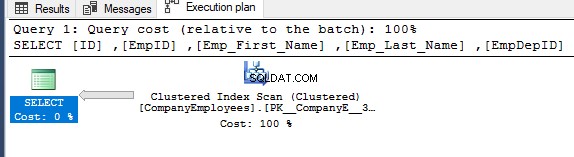
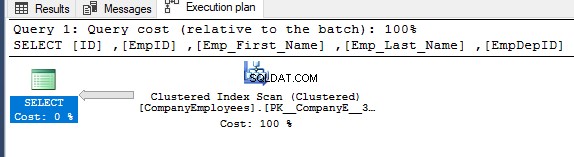
För att få riktningen för skanningen som utförs på det klustrade indexet, högerklicka på indexskanningsnoden för att bläddra i nodens egenskaper. Från egenskaperna för Clustered Index Scan-nod kommer egenskapen Scan Direction att visa riktningen för skanningen som utförs på indexet i den frågan, vilket är Forward Scan som visas i ögonblicksbilden nedan:
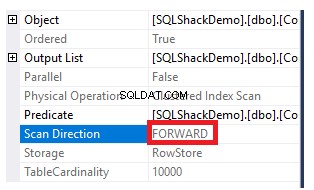
Indexskanningsriktningen kan också hämtas från XML-exekveringsplanen från egenskapen ScanDirection under IndexScan-noden, som visas nedan:

Antag att vi behöver hämta det maximala ID-värdet från tabellen CompanyEmployees som skapats tidigare, med hjälp av T-SQL-frågan nedan:
VÄLJ MAX([ID]) FRÅN [dbo].[Företagsanställda]
Granska sedan exekveringsplanen som genereras från exekvering av den frågan. Du kommer att se att en skanning kommer att utföras på det klustrade indexet som visas i exekveringsplanen nedan:
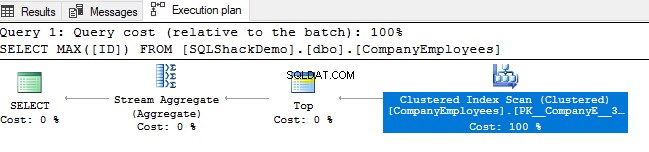
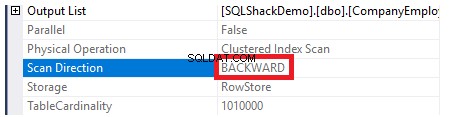
För att kontrollera riktningen för indexskanningen kommer vi att bläddra bland egenskaperna för Clustered Index Scan-noden. Resultatet kommer att visa oss att SQL Server Engine föredrar att skanna det klustrade indexet från slutet till början, vilket kommer att vara snabbare i det här fallet, för att få det maximala värdet av ID-kolumnen, på grund av det faktum att index är redan sorterat enligt ID-kolumnen, som visas nedan:
Dessutom, om vi försöker hämta tidigare skapade tabelldata med hjälp av följande SELECT-sats, kommer posterna att sorteras enligt ID-kolumnvärdena, men den här gången, motsatsen till den klustrade indexordningen, genom att specificera DESC-sorteringsalternativet i ORDER BY-klausul som visas nedan:
VÄLJ [ID] ,[Emp_ID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status],[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] FRÅN [SQLShackDeployemoE] ] BESTÄLL AV [ID] DESC
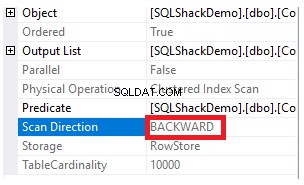
Om du kontrollerar exekveringsplanen som genererades efter exekvering av den tidigare SELECT-frågan, kommer du att se att en skanning kommer att utföras på det klustrade indexet för att få de begärda posterna i tabellen, som visas nedan:
Egenskaperna för Clustered Index Scan-noden kommer att visa att riktningen för skanningen som SQL Server Engine föredrar att ta är Backward Scan-riktningen, vilket är snabbare i det här fallet, på grund av att data sorteras motsatt den verkliga sorteringen av det klustrade indexet, med hänsyn till att indexet redan är sorterat i stigande ordning enligt ID-kolumnen, som visas nedan:
Prestandajämförelse
Antag att vi har nedanstående SELECT-satser som hämtar information om alla anställda som har anställts från och med 2010, två gånger; första gången kommer den returnerade resultatuppsättningen att sorteras i stigande ordning enligt ID-kolumnvärdena, och andra gången kommer den returnerade resultatuppsättningen att sorteras i fallande ordning enligt ID-kolumnvärdena med hjälp av T-SQL-satserna nedan:
VÄLJ [ID] ,[Emp_ID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status],[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] FRÅN [SQLShackDeployemoE] ] WHERE Emp_EmploymentDate>='2010-01-01' BESTÄLL MED [ID] ASC OPTION (MAXDOP 1) GÅ VÄLJ [ID] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ] ,[E, EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] FRÅN [SQLShackDemo].[dbo].[CompanyEmployees] WHERE Emp_EmploymentDate>='2010-01-01' BESTÄLLNING EFTER [ID] DESC ALTERNATIV 1) (MAX.Genom att kontrollera exekveringsplanerna som genereras genom att köra de två SELECT-frågorna, kommer resultatet att visa att en skanning kommer att utföras på det klustrade indexet i de två frågorna för att hämta data, men riktningen för skanningen i den första frågan kommer att vara Framåt Skanna på grund av ASC-datasortering och bakåtsökning i den andra frågan på grund av användning av DESC-datasortering, för att ersätta behovet av att omordna data igen, som visas nedan:
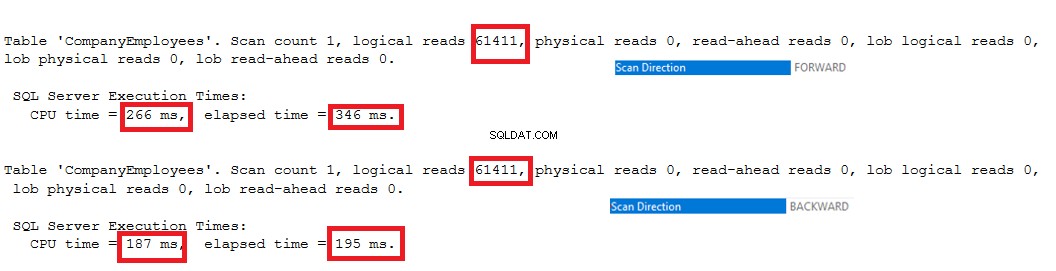
Dessutom, om vi kontrollerar IO- och TIME-exekveringsstatistiken för de två frågorna, kommer vi att se att båda frågorna utför samma IO-operationer och förbrukar nästan värden för exekveringen och CPU-tiden.
Dessa värden visar oss hur smart SQL Server Engine är när den väljer den lämpligaste och snabbaste indexskanningsriktningen för att hämta data för användaren, vilket är Forward Scan i det första fallet och Backward Scan i det andra fallet, vilket framgår av statistiken nedan. :
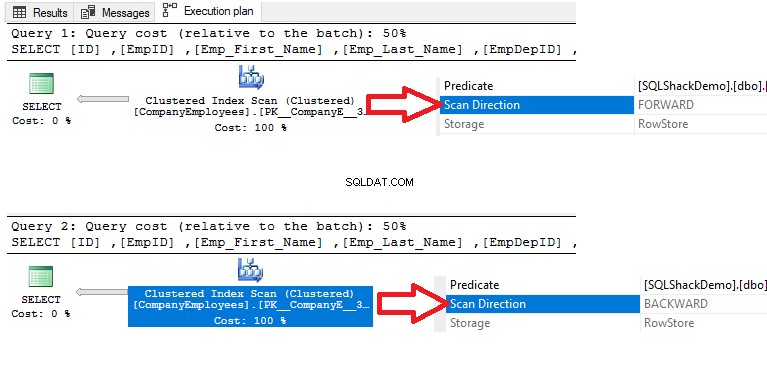
Låt oss besöka det tidigare MAX-exemplet igen. Antag att vi behöver hämta max-ID för de anställda som har anställts 2010 och senare. För detta kommer vi att använda följande SELECT-satser som kommer att sortera läst data enligt ID-kolumnvärdet med ASC-sortering i den första frågan och med DESC-sortering i den andra frågan:
VÄLJ MAX([Emp_EmploymentDate]) FRÅN [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate]>='2017-01-01' GRUPPER EFTER ID BESTÄLLNING AV [ID] ASC-ALTERNATIV (GODOP 1) VÄLJ MAX([Emp_EmploymentDate]) FRÅN [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate]>='2017-01-01' GRUPPER EFTER ID BESTÄLLNING EFTER [ID] DESC OPTION (MAXDOP 1) .>Du kommer att se från exekveringsplanerna som genereras från exekveringen av de två SELECT-satserna, att båda frågorna kommer att utföra en skanningsoperation på det klustrade indexet för att hämta det maximala ID-värdet, men i olika skanningsriktningar; Skanna framåt i den första frågan och Skanna bakåt i den andra frågan, på grund av sorteringsalternativen ASC och DESC, som visas nedan:
IO-statistiken som genereras av de två frågorna visar ingen skillnad mellan de två skanningsriktningarna. Men TIME-statistiken visar en stor skillnad mellan att beräkna radernas maximala ID när dessa rader skannas från början till slutet med metoden Forward Scan och att skanna den från slutet till början med Backward Scan-metoden. Det framgår tydligt av resultatet nedan att bakåtsökningsmetoden är den optimala skanningsmetoden för att få maximalt ID-värde:
Prestandaoptimering
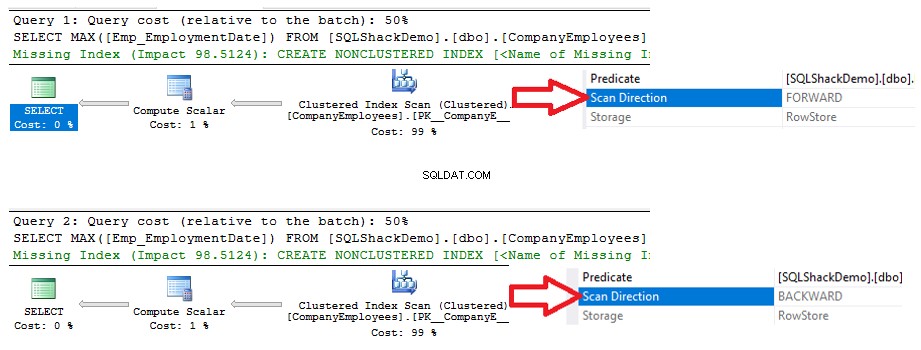
Som jag nämnde i början av den här artikeln är frågeindexering den viktigaste nyckeln i prestandajustering och optimeringsprocessen. Om vi i den föregående frågan lägger till ett icke-klustrat index i kolumnen EmploymentDate i tabellen CompanyEmployees, med hjälp av CREATE INDEX T-SQL-satsen nedan:
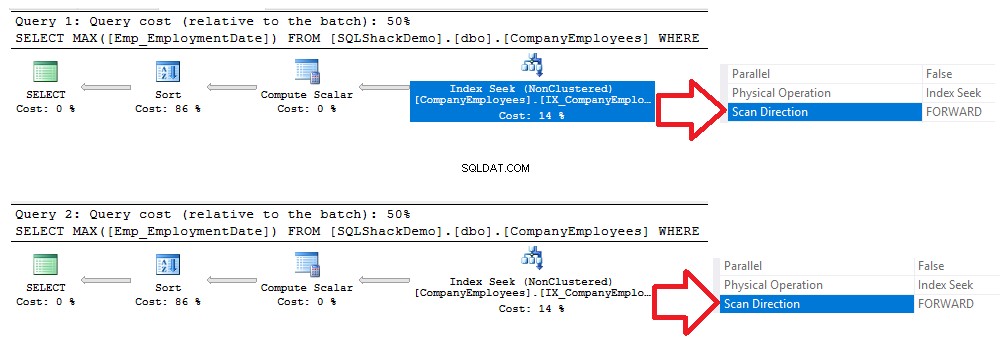
SKAPA INKLUSTERAT INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate)Därefter kommer vi att köra samma tidigare frågor som visas nedan:SELECT MAX([Emp_EmploymentDate]) FROM] [SQLShackdEemployeE])FROM] [SQLShackdEmE]Deploye[SQLShackmE]Deploye[SQLShackmE] ='2017-01-01' GRUPPERAR EFTER ID BESTÄLLNING AV [ID] ASC-ALTERNATIV (MAXDOP 1) GÅ VÄLJ MAX([Emp_EmploymentDate]) FRÅN [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate]> -01-01' GRUPPER EFTER ID BESTÄLLNING AV [ID] DESC ALTERNATIV (MAXDOP 1) GÅGenom att kontrollera exekveringsplanerna som genereras efter exekvering av de två frågorna kommer du att se att en sökning kommer att utföras på det nyskapade icke-klustrade indexet, och båda frågorna kommer att skanna indexet från början till slutet med hjälp av Forward Scan-metoden, utan att behöva att utföra en bakåtsökning för att påskynda datahämtningen, även om vi använde sorteringsalternativet DESC i den andra frågan. Detta inträffade på grund av att man sökte indexet direkt utan att behöva utföra en fullständig indexskanning, som visas i jämförelsen av exekveringsplanerna nedan:
Samma resultat kan härledas från IO- och TIME-statistiken som genererats från de två föregående frågorna, där de två frågorna kommer att förbruka samma mängd exekveringstid, CPU- och IO-operationer, med en mycket liten skillnad, som visas i statistiköversikten nedan :
Användbara länkar:


- Klustrade och icke-klustrade index beskrivs
- Skapa icke-klustrade index
- SQL-serverprestandajustering:Skanna bakåt av ett index
Användbart verktyg:
dbForge Index Manager – praktiskt SSMS-tillägg för att analysera status för SQL-index och åtgärda problem med indexfragmentering.