Vad är frågeoptimering i SQL Server? Det är ett stort ämne. Varje teknik eller problem behöver en separat artikel för att täcka baserna. Men när du precis har börjat höja ditt spel i nivå med frågor behöver du något enklare att lita på. Detta är målet med den här artikeln.
Du kan säga att dina frågor är optimala, allt fungerar bra och användarna är nöjda. Prestanda är naturligtvis inte allt. Resultaten ska också vara korrekta. Oavsett om det är en koppling, en underfråga, en synonym, en CTE, en vy eller vad som helst, måste det fungera acceptabelt.
Och i slutet av dagen kan du gå hem med dina användare. Du vill inte sitta kvar på kontoret och fixa de långsamma frågorna över natten.
Innan vi börjar, låt mig försäkra dig om att resan inte kommer att bli svår. Det här blir bara en primer. Vi kommer att ha exempel som inte kommer att vara alltför främmande för dig också. Slutligen, när du är redo för en djupare studie kommer vi att presentera några länkar som du kan kolla in.
Låt oss börja.
1. SQL-frågeoptimering startar från design och arkitektur
Överraskad? SQL-frågeoptimering är inte en eftertanke eller ett plåster när något går sönder. Din fråga körs så snabbt som din design tillåter. Vi pratar om normaliserade tabeller, rätt datatyper, användning av index, arkivering av gamla data och alla de bästa metoderna du kan tänka dig.
En bra databasdesign fungerar i synergi med rätt hårdvara och SQL Server-inställningar. Designade du den för att fungera smidigt i flera år och fortfarande kännas ny? Det är en stor dröm, men vi har bara en viss (vanligtvis – kort) tid på oss att tänka på det.
Det kommer inte att vara perfekt på dag 1 i produktionen, men vi borde ha täckt baserna. Vi kommer att minimera tekniska skulder. Om du arbetar med ett team är det bra jämfört med en enmansshow. Du kan täcka mycket av klockorna och visselpiporna.
Men vad händer om databasen körs live och du träffar prestandaväggen? Här är några tips och tricks för optimering av SQL-frågor.
2. Hitta problematiska frågor med SQL Server Standard Report
När du kodar är det lätt att upptäcka en lång rad kod eller en lagrad procedur. Du kan felsöka det rad för rad. Linjen som släpar är den som ska fixas.
Men vad händer om din helpdesk kastade ett dussin biljetter för att det går långsamt? Användare kan inte fastställa den exakta platsen i koden, och det kan inte heller helpdesk. Tiden är din värsta fiende.
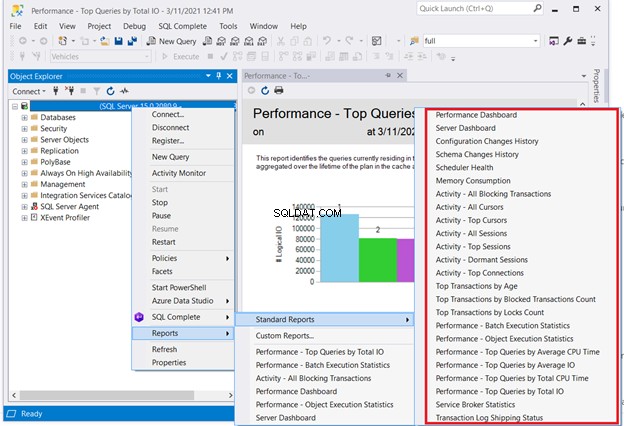
En lösning som inte kräver kodning är att kontrollera SQL Servers standardrapporter. Högerklicka på den nödvändiga servern i SQL Server Management Studio> Rapporter> Standardrapporter . Vår intressepunkt kan vara Prestanda Dashboard eller Performance – Top Queries by Total I/O . Välj den första frågan som ger dåligt resultat. Starta sedan SQL-frågaoptimeringen eller SQL-prestandajusteringen därifrån.
3. SQL Query Tuning med STATISTICS IO
Efter att ha hittat frågan i fråga kan du börja kontrollera logiska läsningar i STATISTICS IO. Detta är ett av SQL-frågeoptimeringsverktygen.
Det finns några I/O-punkter, men du bör fokusera på logiska läsningar. Ju högre de logiska läsningarna är, desto mer problematisk är frågeprestandan.
Genom att reducera följande tre faktorer kan du snabba upp prestandajusteringsfrågorna i SQL:
- hög logisk läsning,
- hög LOB logisk läsning,
- eller höga logiska WorkTable/WorkFile-läsningar.
För att få information om logiska läsningar, aktivera STATISTICS IO i frågefönstret för SQL Server Management Studio.
SÄTT PÅ STATISTIK IO
Du kan få utdata på fliken Meddelanden efter att frågan är klar. Figur 2 visar exempelutdata:
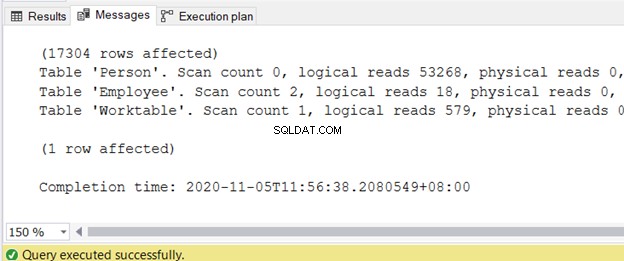
Jag har skrivit en separat artikel om att minska logiska läsningar i 3 Nasty I/O Statistics som fördröjer SQL Query Performance. Se den för de exakta stegen och kodexemplen med höga logiska läsningar och sätt att minska dem.
4. SQL-frågejustering med exekveringsplaner
Enbart logisk läsning ger dig inte hela bilden. Den serie av steg som väljs av frågeoptimeraren kommer att berätta historien om din resultatuppsättning. Hur börjar det hela efter att du har kört frågan?
Figur 3 nedan är ett diagram över vad som händer efter att du triggar exekveringen tills du får resultatet.
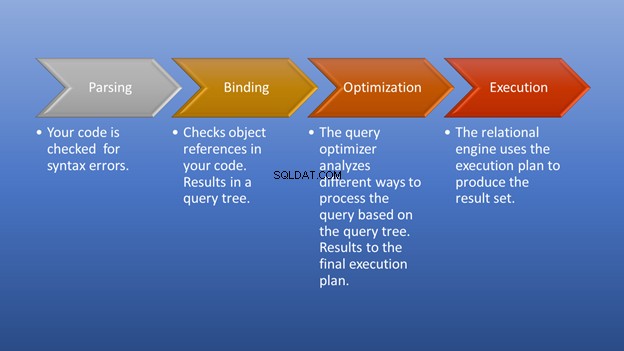
Parsning och bindning kommer att ske på ett ögonblick. Den fantastiska delen är optimeringsstadiet, som är vårt fokus. I detta skede spelar frågeoptimeraren en avgörande roll för att välja den bästa möjliga exekveringsplanen. Även om den här delen behöver vissa resurser, sparar den mycket tid när den väljer en effektiv genomförandeplan. Detta sker dynamiskt, eftersom databasen förändras över tiden. På så sätt kan programmeraren fokusera på hur man formar slutresultatet.
Varje plan som frågeoptimeraren anser har sin frågekostnad. Bland många alternativ kommer optimeraren att välja planen med den mest rimliga kostnaden. Obs :Rimlig kostnad är inte lika med den lägsta kostnaden. Den måste också överväga vilken plan som ger de snabbaste resultaten. Planen med lägsta kostnad är inte alltid den snabbaste. Till exempel kan optimeraren välja att använda flera processorkärnor. Vi kallar detta parallellt utförande. Detta kommer att förbruka mer resurser men går snabbare jämfört med seriell exekvering.
En annan punkt att tänka på är statistik. Frågeoptimeraren förlitar sig på den för att skapa exekveringsplaner. Om statistiken är föråldrad, förvänta dig inte det bästa beslutet från frågeoptimeraren.
När planen är beslutad och utförandet fortskrider kommer du att se resultatet. Vad nu?
Inspektera frågeexekveringsplanen i SQL Server
När du skapar en fråga vill du först se resultatet. Resultaten måste vara korrekta. När det är så är du klar.
Är det så?
Om du har ont om tid, och jobbet står på spel, kan du gå med på det. Dessutom kan du alltid komma tillbaka. Men om andra problem uppstår kan du glömma dem om och om igen. Och sedan kommer det förflutnas spöke att jaga dig.
Nu, vad är det bästa att göra efter att ha fått rätt resultat?
Inspektera Faktisk utförandeplan eller Live Query Statistics !
Det senare är bra om din fråga går långsamt och du vill se vad som händer varje sekund när raderna bearbetas.
Ibland kommer situationen att tvinga dig att inspektera planen omedelbart. Börja genom att trycka på Control-M eller klicka på Inkludera faktisk exekveringsplan från verktygsfältet i SQL Server Management Studio. Om du föredrar dbForge Studio för SQL Server, gå till Frågeprofil – den ger samma information + några ringklockor och visselpipor som du inte kan hitta i SSMS.
Vi har sett den faktiska utförandeplanen . Låt oss gå vidare.
Finns det ett index som saknas eller indexrekommendationer?
Ett saknat index är lätt att upptäcka – du får varningen direkt.
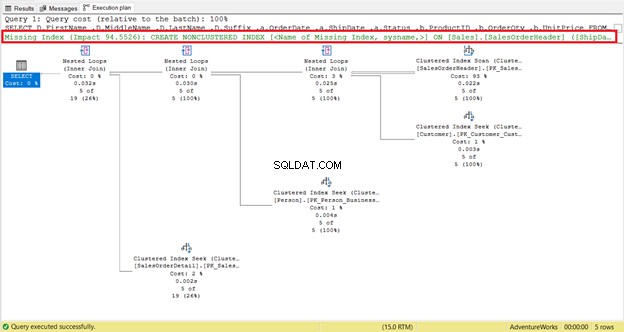
För att få en omedelbar kod för att skapa indexet, högerklicka på Index saknas meddelande (rött ruta). Välj sedan Indexinformation saknas . Ett nytt frågefönster med koden för att skapa det saknade indexet visas. Skapa indexet.
Denna del är lätt att följa. Det är en bra utgångspunkt för att uppnå snabbare utförande. Men i vissa fall blir det ingen effekt. Varför? Vissa kolumner som behövs för din fråga finns inte i indexet. Därför kommer den att återgå till en Clustered Index Scan.
Du måste inspektera exekveringsplanen igen efter att du har skapat indexet för att se om Inkluderade kolumner behövs. Justera sedan indexet därefter och kör din fråga igen. Efter det, kontrollera genomförandeplanen igen.
Men vad händer om det inte saknas något index?
Läs genomförandeplanen
Du behöver veta några grundläggande saker för att komma igång:
- Operatorer
- Egenskaper
- Läsriktning
- Varningar
OPERATÖRER
Frågeoptimeraren använder någon sorts miniprogram som kallas operatorer. Du har sett några av dem i figur 4 – Clustered Index Seek , Clustered Index Scan , Inkapslade loopar och Välj .
För att få en heltäckande lista med namn, ikoner och beskrivningar kan du kontrollera denna referens från Microsoft.
EGENSKAPER
Grafiska diagram räcker inte för att förstå vad som händer bakom kulisserna. Du måste gräva djupare i varje operatörs egenskaper. Till exempel, Clustered Index Scan i figur 4 har följande egenskaper:
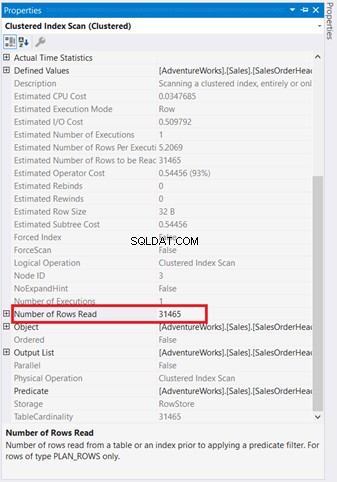
Om du undersöker det noggrant, Clustered Index Scan operatören är hemsk. Som figur 5 visar, läser den 31 465 rader, men slutresultatet är bara 5 rader. Det är därför det finns en indexrekommendation i figur 4 för att minska antalet lästa rader. Den logiska läsningen av frågan är också hög och detta förklarar varför.
För att veta mer om dessa egenskaper, kolla in listan över vanliga operatörsfastigheter och planegenskaper.
LÄSRIKTNING
I allmänhet är det som att läsa japansk manga - från höger till vänster. Följ pilarna som pekar åt vänster. Här är ett enkelt exempel från dbForge Studio för SQL Server.
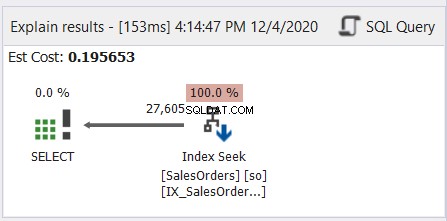
Som figur 6 visar pekar pilen åt vänster från indexsökoperatorn till SELECT-operatorn.
Men att läsa från höger till vänster kanske inte alltid stämmer. Se figur 7 med ett exempel från SSMS:
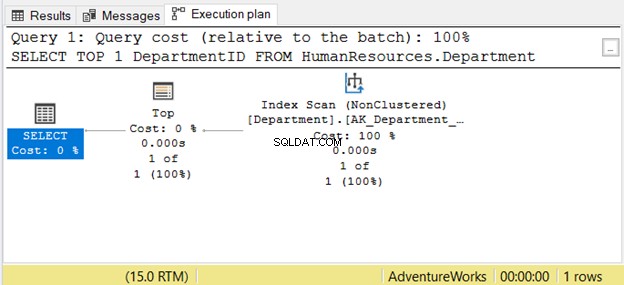
Om du läser den från höger till vänster ser du att indexskanningen operatörens utdata är 1 av 1 rad. Hur kunde den veta bara en rad att hämta? Det är på grund av Topp operatör. Detta kommer att förvirra oss om vi läser det från höger till vänster.
För att förstå det här fallet bättre, läs det som "SELECT-operatorn använder Top för att hämta 1 rad med Index Scan". Det är från vänster till höger.
Vad ska vi använda? Höger till vänster eller vänster till höger?
Det är typ båda - beroende på vad som hjälper dig att förstå planen.
Medan pilen ger oss riktningen för dataflödet, ger dess tjocklek oss några tips om storleken på datan. Låt oss hänvisa till figur 4 igen.
Clustered Index Scan gå till Inkapslade loop har en tjockare pil jämfört med de andra. Egenskaper information om Indexsökning i figur 5 berätta varför den är tjock (31 465 rader avlästa för ett slutresultat på 5 rader).
VARNINGAR
En varningsikon som visas i operatören för genomförandeplanen talar om för oss att något dåligt har hänt i den operatören. Detta kan hindra din SQL-frågaoptimering genom att förbruka mer resurser.
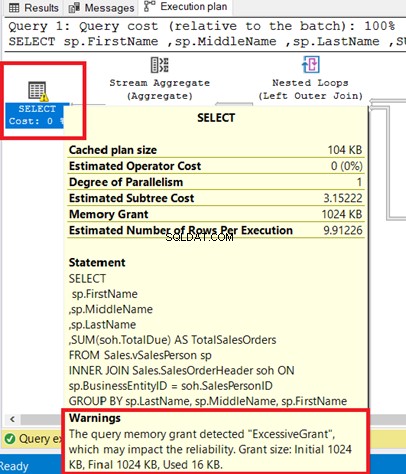
Du kan se varningen i SELECT-operatorn. Om du håller muspekaren till den operatören visas varningsmeddelandet. Ett Excessive Grant har orsakat denna varning.
Excessive Grant händer när mindre minne används än vad som reserverats för frågan. Mer information finns i den här Microsoft-dokumentationen.
Figur 8 visar frågan som används som en INNER JOIN av en vy till en tabell. Du kan ta bort varningen genom att sammanfoga bastabeller istället för vyn.
Nu när du har en grundläggande idé om att läsa genomförandeplaner, hur definierar du vad som gör din fråga långsam?
Känn till de 5 gemensamma planoperatörsfelen
Fördröjningen i utförandet av din fråga är som ett brott. Du måste jaga och arrestera dessa skurkar.
1. Clustered eller Non-Clustered Index Scan
Den första skurk som alla lär sig om är Clustered eller Icke-klustrad indexsökning . Dess allmänna kunskap inom SQL-frågeoptimering att skanningar är dåliga och sökningar är bra. Vi har sett en i figur 4. På grund av det saknade indexet kan Clustered Index Scan läser 31 465 för att få 5 rader.
Det är dock inte alltid så. Tänk på två frågor på samma tabell i figur 9. En kommer att ha en sökning och en annan har en skanning.
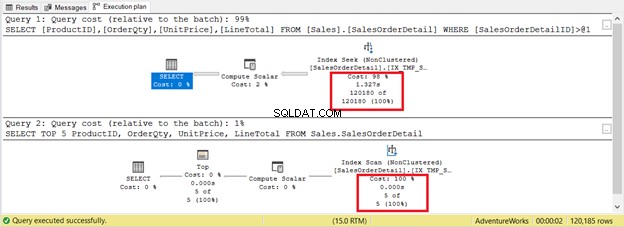
Om du bara baserar kriterierna på antalet poster vinner indexskanningen med endast 5 poster mot 120 180. Indexsökningen kommer att ta längre tid att utföra.
Här är ett annat exempel där antingen skanna eller söka nästan inte spelar någon roll. De returnerar samma 6 poster från samma tabell. De logiska avläsningarna är desamma och den förflutna tiden är noll i båda fallen. Tabellen är mycket liten med endast 6 poster. Inkludera den faktiska genomförandeplanen och kör satserna nedan.
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
Spara sedan exekveringsplanen för jämförelse senare. Högerklicka på exekveringsplanen> Spara exekveringsplan som .
Kör nu frågan nedan.
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
Högerklicka sedan på exekveringsplanen och välj Jämför Showplan . Välj sedan filen du sparade tidigare. Du bör ha samma utdata som i figur 10 nedan.
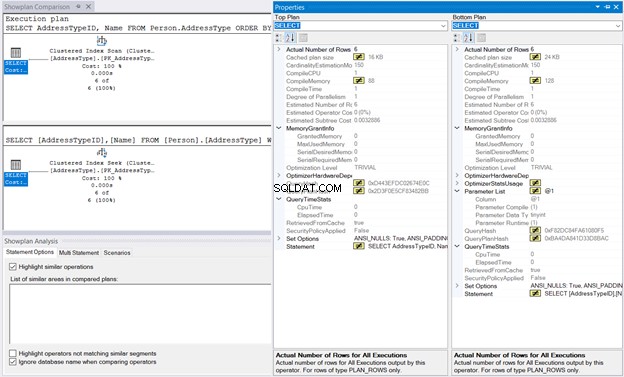
MemoryGrant och QueryTimeStats är samma. CompileMemory på 128 kB används i Clustered Index Seek jämfört med 88KB av Clustered Index Scan är nästan försumbar. Utan dessa siffror att jämföra kommer utförandet att kännas likadant.
2. Undviker tabellskanningar
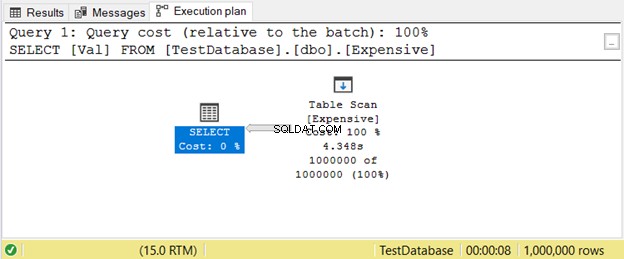
Detta händer när du inte har ett index. Istället för att söka värden med hjälp av ett index kommer SQL Server att skanna rader en efter en tills den får det du behöver i din fråga. Detta kommer att släpa mycket på stora bord. Den enkla lösningen är att lägga till lämpligt index.
Här är ett exempel på en genomförandeplan med Table Scan operatorn i figur 11.
3. Hantera sorteringsprestanda
Eftersom det kommer från namnet ändrar det ordningen på raderna. Detta kan bli en dyr operation.
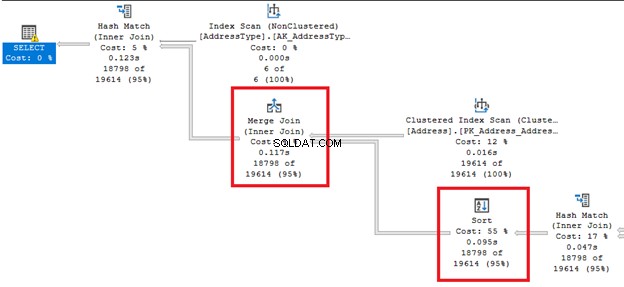
Titta på de feta pillinjerna från höger och vänster om Sortera operatör. Eftersom frågeoptimeraren bestämde sig för att göra en sammanfogning , en sort krävs. Observera också att den har den högsta procentuella kostnaden av alla operatörer (55%).
Sortering kan vara mer besvärligt om SQL Server behöver beställa rader flera gånger. Du kan undvika den här operatorn om din tabell är försorterad baserat på frågekravet. Eller så kan du dela upp en enda fråga i flera.
4. Eliminera nyckeluppslag
I figur 4 tidigare rekommenderade SQL Server att lägga till ett annat index. Jag gjorde det, men det gav mig inte exakt vad jag ville ha. Istället gav det mig en indexsökning till det nya indexet parat med en nyckelsökning operatör.
Så det nya indexet lade till ett extra steg.
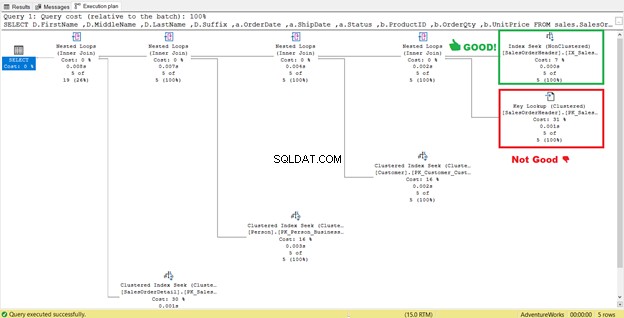
Vad innebär denna nyckelsökning operatör gör?
Frågeprocessorn använde ett nytt icke-klustrat index inrutat i grönt i figur 13. Eftersom vår fråga kräver kolumner som inte finns i det nya indexet, måste den hämta dessa data med hjälp av en nyckelsökning från det klustrade indexet. Hur vet vi detta? Håll muspekaren till Nyckelsökning avslöjar några av dess egenskaper och bevisar vår poäng.
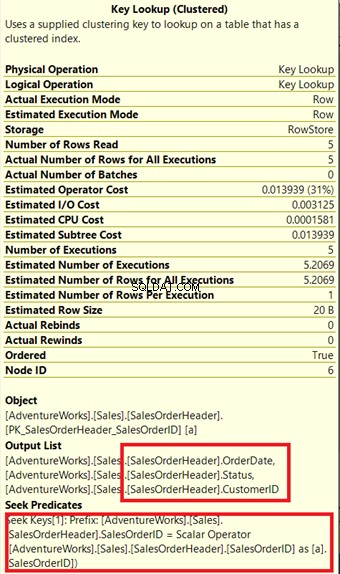
Lägg märke till utdatalistan i figur 14. Vi måste hämta tre kolumner med PK_SalesOrderHeader_SalesOrderID klustrade index. För att ta bort detta måste du inkludera dessa kolumner i det nya indexet. Här är den nya planen när dessa kolumner är med.
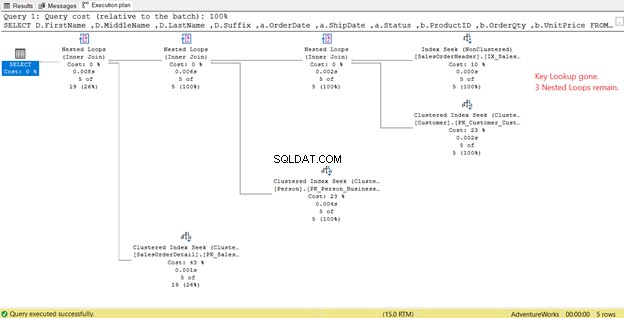
I figur 14 såg vi fyra Inkapslade loopar . Den fjärde behövs för den tillagda nyckelsökningen . Men efter att ha lagt till 3 kolumner som Inkluderade kolumner i det nya indexet, bara 3 Inkapslade slingor kvar och Nyckelsökning är borttagen. Vi behöver inga extra steg.
5. Parallellism i SQL Server Execution Plan
Hittills har du sett avrättningsplaner i serieutförande. Men här är planen som utnyttjar parallellt genomförande. Detta innebär att mer än en processor används av frågeoptimeraren för att köra frågan. När vi använder parallell exekvering ser vi Parallellism operatörer i planen, och andra förändringar också.
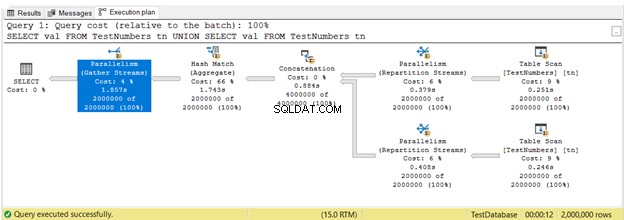
I figur 16, 3 Parallellism operatörer användes. Observera också att Table Scan operatörsikonen är lite annorlunda. Detta händer när parallell exekvering används.
Parallellism är inte dåligt i sig. Det ökar hastigheten på frågor genom att använda fler processorkärnor. Den använder dock mer CPU-resurser. När många av dina frågor använder parallellism, saktar det ner servern. Du kanske vill kontrollera kostnadströskeln för parallellitetsinställning i din SQL Server.
5. Bästa tillvägagångssätt för SQL-frågeoptimering
Hittills har vi sysslat med SQL-frågeoptimering med metoder som avslöjar problem som är svåra att upptäcka. Men det finns sätt att upptäcka det i kod. Här är några kodlukter i SQL.
Med SELECT *
Har bråttom? Då kan det vara lättare att skriva * än att ange kolumnnamn. Det finns dock en hake. Kolumner du inte behöver fördröjer din fråga.
Det finns bevis. Exempelfrågan jag använde för figur 15 är denna:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Vi har redan optimerat det. Men låt oss ändra det till SELECT *
USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Det är kortare okej, men kontrollera genomförandeplanen nedan:
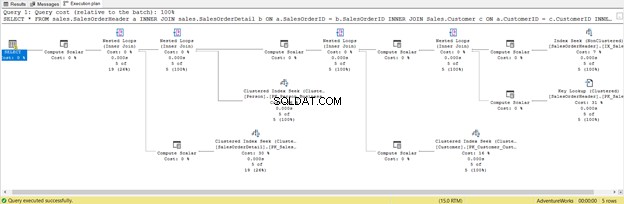
Detta är konsekvensen av att inkludera alla kolumner, även de du inte behöver. Den returnerade Nyckelsökning och massor av Compute Scalar . Kort sagt, denna fråga har en stor belastning och kommer att släpa efter som ett resultat. Lägg också märke till varningen i SELECT-operatorn. Det fanns inte där förut. Vilket slöseri!
Funktioner i en WHERE-klausul eller JOIN
En annan kodlukt har en funktion i WHERE-satsen. Tänk på att följande 2 SELECT-satser har samma resultatuppsättning. Skillnaden ligger i WHERE-satsen.
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
Den första SELECT-satsen använder YEAR- och MONTH-datumfunktionerna för att indikera leveransdatum inom juli 2011. Den andra SELECT-satsen använder BETWEEN-operatorn med datumbokstav.
Den första SELECT-satsen kommer att ha en exekveringsplan som liknar figur 4 men utan indexrekommendationen. Den andra kommer att ha en bättre utförandeplan som liknar figur 15.
Den som är bättre optimerad är uppenbar.
Användning av jokertecken
Hur vilda kan jokertecken påverka vår SQL-frågeoptimering? Låt oss ta ett exempel.
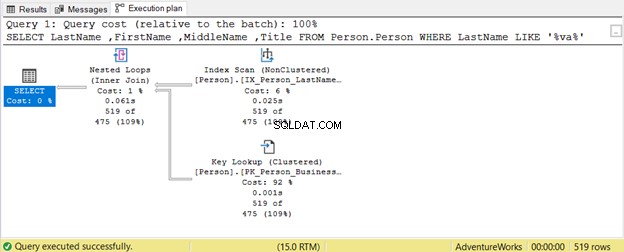
Frågan försöker leta efter en närvaro av en sträng inom Efternamn i vilken position som helst. Därför Efternamn LIKE '%va%' . Detta är ineffektivt på stora tabeller eftersom rader kommer att inspekteras en efter en för närvaron av den strängen. Det är därför en indexskanning är använd. Eftersom inget index innehåller Titel kolumn, en nyckelsökning används också.
Detta kan fixas genom design.
Kräver uppringningsappen det? Eller kommer det att räcka med att använda LIKE 'va%'?
SOM "va%" använder en indexsökning eftersom tabellen har ett index på efternamn , förnamn och mellannamn .
Kan du också lägga till fler filter i WHERE-satsen för att minska posternas läsning?
Dina svar på dessa frågor hjälper dig att åtgärda den här frågan.
Implicit konvertering
SQL Server gör implicit konvertering bakom kulisserna för att stämma av datatyper när man jämför värden. Det är till exempel bekvämt att tilldela ett nummer till en strängkolumn utan citattecken. Men det finns en hake. Effekten är liknande när du använder en funktion i en WHERE-sats.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
NationalIDNumner är NVARCHAR(15) men är likställt med ett tal. Det kommer att köras framgångsrikt på grund av implicit konvertering. Men lägg märke till utförandeplanen i figur 19 nedan.
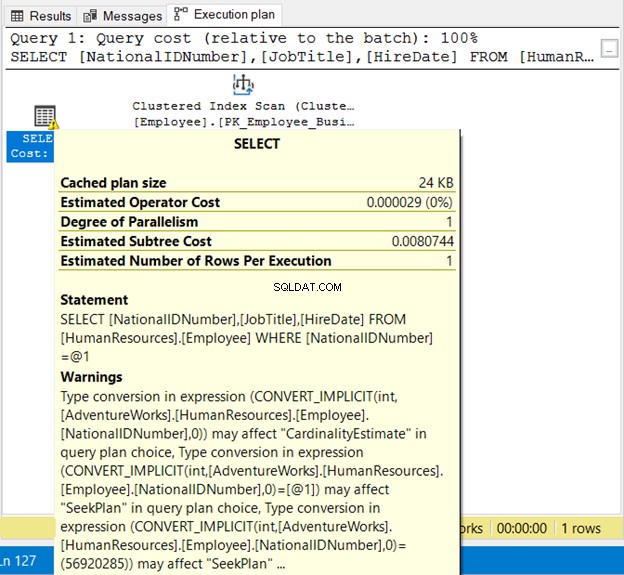
Vi ser 2 dåliga saker här. Först, varningen. Sedan Indexsökning . Indexsökningen skedde på grund av implicit konvertering. Se därför till att omge strängar inom citattecken eller testa bokstavliga värden med samma datatyp som kolumnen.
SQL Query Optimization Takeaways
Det är allt. Gjorde grunderna för SQL-frågeoptimering att du kände dig lite redo för dina frågor? Låt oss ha en sammanfattning.
- Om du vill att dina frågor ska optimeras, börja med en bra databasdesign.
- Om databasen redan är i produktion, upptäck de problematiska frågorna med SQL Server-standardrapporter.
- Läs om hur stor inverkan den långsamma frågan har med logiska läsningar från STATISTICS IO.
- Gräv djupare i historien om din långsamma fråga med exekveringsplaner.
- Titta på 4 kodlukter som saktar ner dina frågor.
Det finns andra SQL-frågeoptimeringstips för att få en långsam fråga att köras snabbt. Som jag sa i början, detta är ett stort ämne. Så låt oss veta i kommentarsektionen vad vi mer missat.
Och om du gillar det här inlägget, dela det på dina favoritplattformar för sociala medier.
Mer SQL-frågeoptimering från tidigare artiklar
Om du behöver fler exempel, här är några användbara inlägg relaterade till frågeoptimeringstekniker i SQL Server.
- Är undersökningar dåliga för prestanda? Kolla in Den enkla guiden om hur du använder underfrågor i SQL Server .
- Använda HierarchyID vs. förälder/underordnad design – vilket är snabbare? Besök Hur man använder SQL Server HierarchyID genom enkla exempel .
- Kan grafdatabasfrågor överträffa sina relationella motsvarigheter i ett rekommendationssystem i realtid? Kolla in Hur man använder SQL Server Graph Database-funktioner .
- Vilket är snabbare:COALESCE eller ISNULL? Ta reda på det i Bästa svaren på 5 brännande frågor om SQL COALESCE-funktion .
- VÄLJ FRÅN vy kontra VÄLJ FRÅN bastabeller – vilken går snabbare? Besök topp 3 tips du behöver veta för att skriva snabbare SQL-vyer .
- CTE vs. tillfälliga tabeller vs. underfrågor. Vet vilken som kommer att vinna i Allt du behöver veta om SQL CTE på ett ställe .
- Använda SQL SUBSTRING i en WHERE-sats – en prestationsfälla? Se om det är sant med exempel i Hur man analyserar strängar som ett proffs med SQL SUBSTRING()-funktionen?
- SQL UNION ALL är snabbare än UNION. Ta reda på varför i SQL UNION Cheat Sheet med 10 enkla och användbara tips .