Introduktion
I den här artikeln kommer vi att diskutera hur olika typer av index i SQL Server-minnesoptimerade tabeller påverkar prestanda. Vi kommer att undersöka exempel på hur olika indextyper kan påverka prestandan hos minnesoptimerade tabeller.
För att göra ämnesdiskussionen enklare kommer vi att använda oss av ett ganska stort exempel. För enkelhetens skull kommer det här exemplet att innehålla olika repliker av en enda tabell, mot vilka vi kör olika frågor. Dessa repliker kommer att använda olika index, eller inga index alls (förutom, naturligtvis, primärnycklarna – PKs).
Observera att det faktiska syftet med denna artikel inte är att jämföra prestanda mellan diskbaserade och minnesoptimerade tabeller i SQL Server i sig. Syftet är att undersöka hur index påverkar prestanda i minnesoptimerade tabeller. Men för att få en fullständig bild av experimenten tillhandahålls även tidpunkter för motsvarande diskbaserade tabellfrågor och hastighetshöjningarna beräknas med den mest optimala konfigurationen av diskbaserade tabeller som baslinjer.
Scenario
Exempeldata för vårt scenario är baserad på en enda tabell definierad som följande:
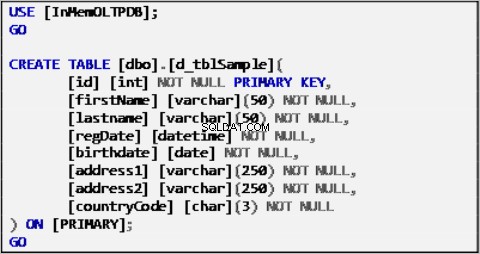
Anteckning 1:Exempeltabell för datakälla.
Tabellen ovan fylldes i med exempeldata och kommer att fungera som datakälla för resten av tabellerna.
Så baserat på tabellen ovan skapar vi följande 9 tabellvarianter och fyller i dem med samma exempeldata:
- 3 diskbaserade tabeller:
- d_tblSample1
- Klustrat index i kolumnen "id" – primärnyckel (PK)
- d_tblSample2
- Klustrat index i kolumnen "id" (PK)
- Icke-klustrade index i kolumnen "countryCode"
- d_tblSample3
- Klustrat index i kolumnen "id" (PK)
- Icke-klustrade index i kolumnen "regDate"
- Icke-klustrade index i kolumnen "countryCode"
- d_tblSample1
- 3 minnesoptimerade tabeller (uppsättning 1:Hashindex):
- m1_tblSample1
- Icke-klustrat hashindex i kolumnen "id" – primärnyckel (PK)
- m1_tblSample2
- Icke-klustrat hashindex i kolumnen "id" (PK)
- Hashindex i kolumnen "countryCode"
- m1_tblSample3
- Icke-klustrat hashindex i kolumnen "id" (PK)
- Hashindex i kolumnen "regDate"
- Hashindex i kolumnen "countryCode"
- 3 minnesoptimerade tabeller (uppsättning 2:icke-klustrade index):
- m2_tblSample1
- Icke-klustrade index i kolumnen "id" – primärnyckel (PK)
- m2_tblSample2
- Icke-klustrat index i kolumnen "id" (PK)
- Icke-klustrade index i kolumnen "countryCode"
- m2_tblSample3
- Icke-klustrat index i kolumnen "id" (PK)
- Icke-klustrade index i kolumnen "regDate"
- Icke-klustrade index i kolumnen "countryCode"
- m2_tblSample1
- m1_tblSample1
I listorna nedan kan du hitta definitionerna för ovanstående tabeller.
Scenariologiken är att vi utför olika databasoperationer mot varianter av samma tabell (men med olika index), och observerar hur prestandan påverkas i varje enskilt fall.
Definitioner
Diskbaserade tabeller
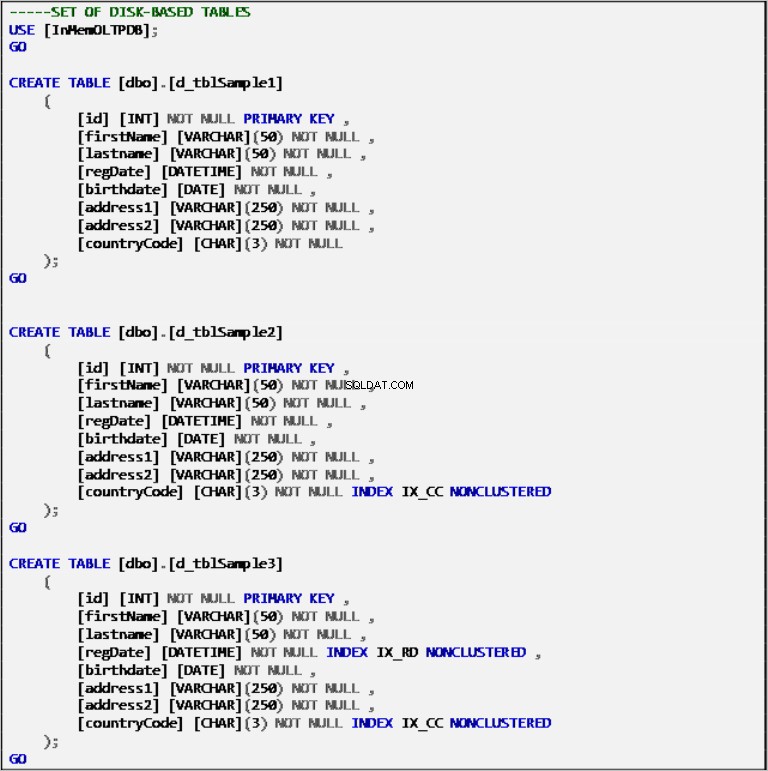
Lista 2:Definition av diskbaserade tabeller.
Minnesoptimerade tabeller (uppsättning 1:Hashindex)

Lista 3:Minnesoptimerade tabeller – set 1 (hashindex).
Minnesoptimerade tabeller (uppsättning 2:icke-klustrade index)

Anteckning 4:Minnesoptimerade tabeller – uppsättning 2 (icke-klustrade index).
Sedan fyller vi i alla ovanstående tabeller med samma exempeldata, vilket är totalt 5 miljoner poster i varje tabell.
Här är resultatet av räknekommandot för varje uppsättning tabeller:
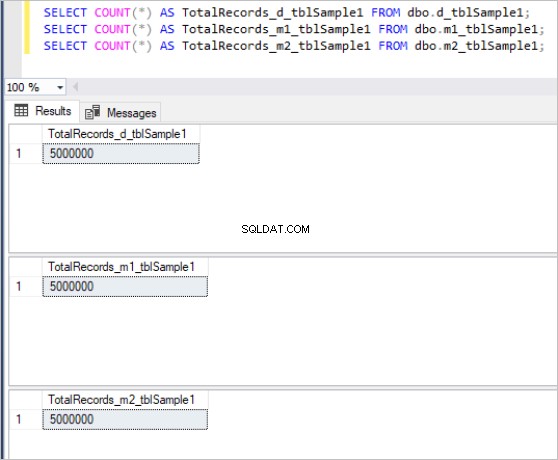
Figur 1:Totalt antal poster för första uppsättningen tabeller.
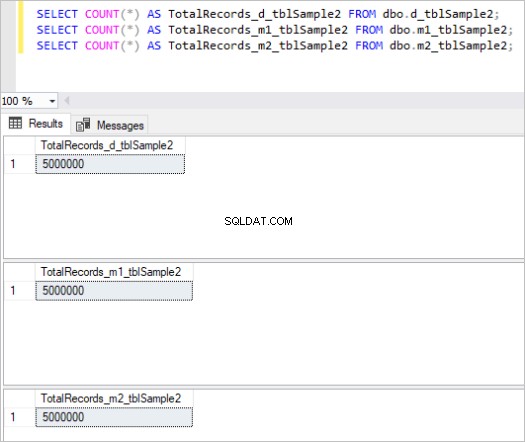
Figur 2:Totalt antal poster för den andra uppsättningen tabeller.
Figur 3:Totalt antal poster för tredje uppsättningen tabeller.
Frågor och scenariekörningar
Nu ska vi köra en uppsättning frågor mot ovanstående tabeller och se hur varje tabell presterar.
Dessa frågor utför följande operationer:
- Fråga 1:Aggregation (GROUP BY)
- Fråga 2:Indexsökning på jämställdhetspredikat
- Fråga 3:Indexsökning på predikat för jämlikhet och ojämlikhet
Planen är att utföra frågorna enligt nedan:
Fråga 1 – Utförande mot följande tabeller:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (inget index på målkolumner)
- m2_tblSample1 (inget index på målkolumner)
Fråga 2 – Utförande mot följande tabeller:
- d_tblSample2
- m1_tblSample2
- m2_tblSample2
- m1_tblSample1 (inget index på målkolumner)
- m2_tblSample1 (inget index på målkolumner)
Fråga 3 – Utförande mot följande tabeller:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (inget index på målkolumner)
- m2_tblSample1 (inget index på målkolumner)
Obs :Även om definitionen för d_tblSample1 diskbaserad tabell ingår i tabelldefinitionerna ovan, den används inte i frågorna i den här artikeln. Anledningen är att i varje scenario används den mest optimala möjliga konfigurationen för den diskbaserade tabellen, eftersom vi vill att vår baslinje ska vara så snabb som möjligt när vi jämför den med prestanda för minnesoptimerade tabeller. För detta ändamål, d_tblSample1 Tabellen presenteras bara i informationssyfte.
Nedan hittar du T-SQL-skripten för de tre frågorna tillsammans med mekanismerna för exekveringstidsmätning.

Anteckning 5:Fråga 1 – Aggregation (med index).
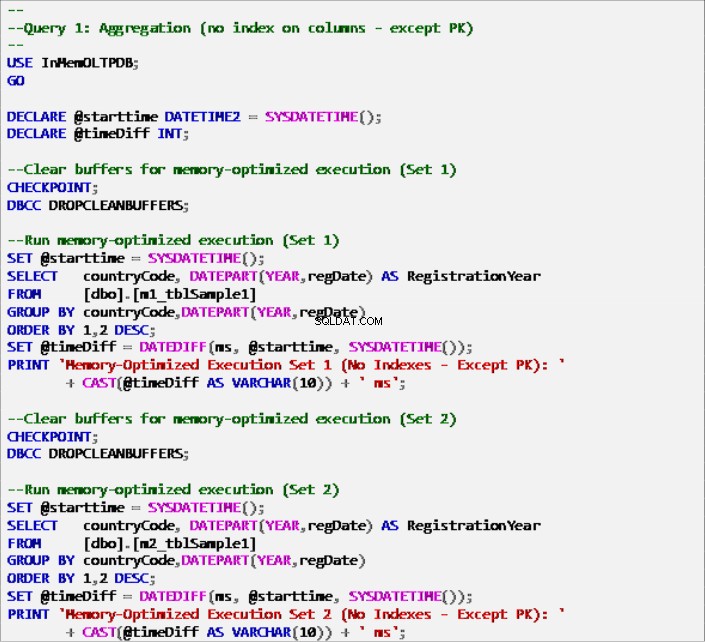
Anteckning 6:Fråga 1 – Aggregation (utan index – förutom primärnyckel).
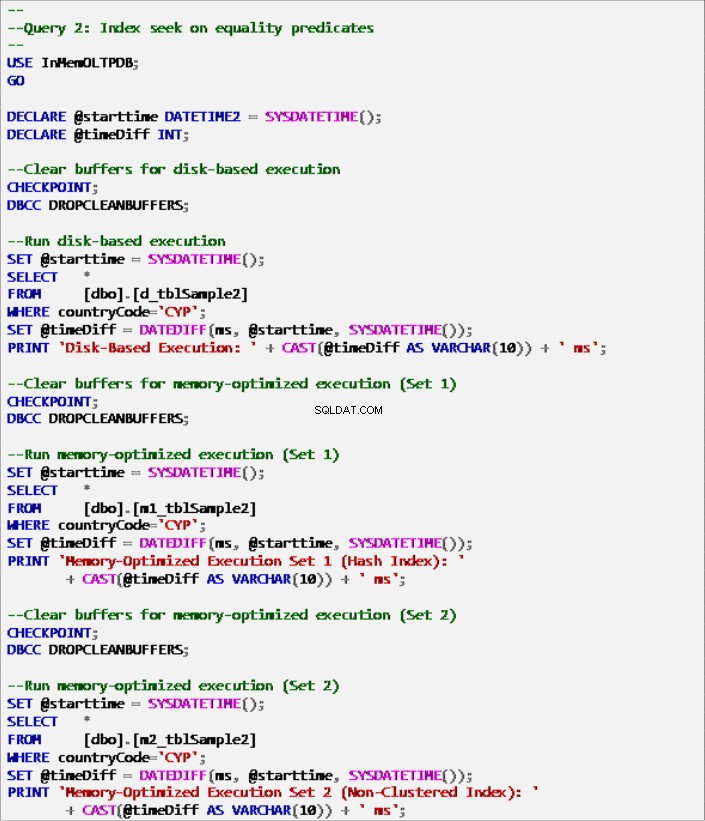
Anteckning 7:Fråga 2 – Indexsökning på jämlikhetspredikat (med index).

Anteckning 8:Fråga 2 – Indexsökning på jämlikhetspredikat (utan index – förutom primärnyckel).
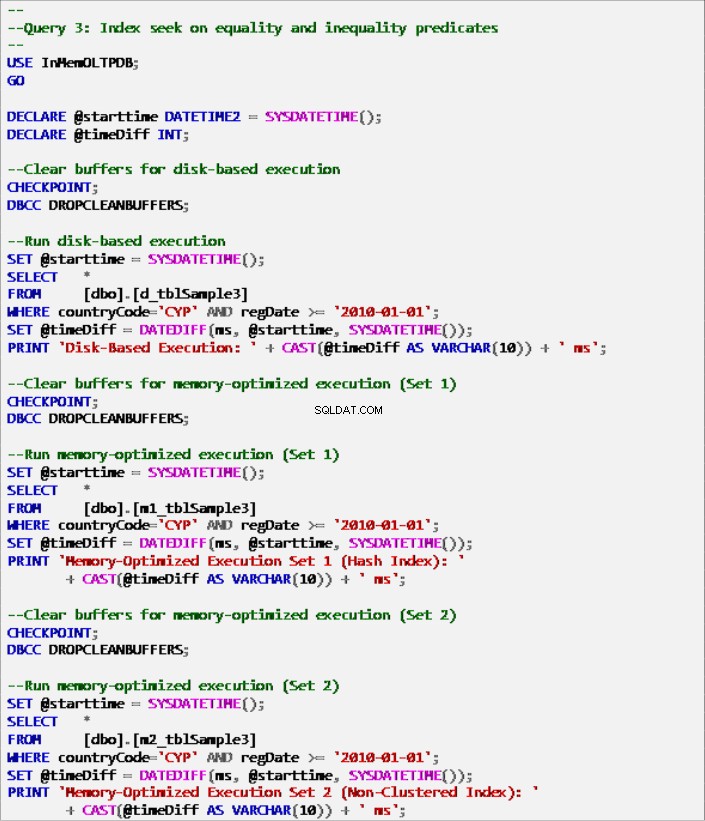
Anteckning 9:Fråga 3 – Indexsökning om jämlikhet och ojämlikhet predikat (med index).

Lista 10:Fråga 3 – Indexsökning på jämlikhets- och ojämlikhetspredikat (utan index – förutom primärnyckel).
Skärmbilderna nedan visar resultatet av varje frågekörning:
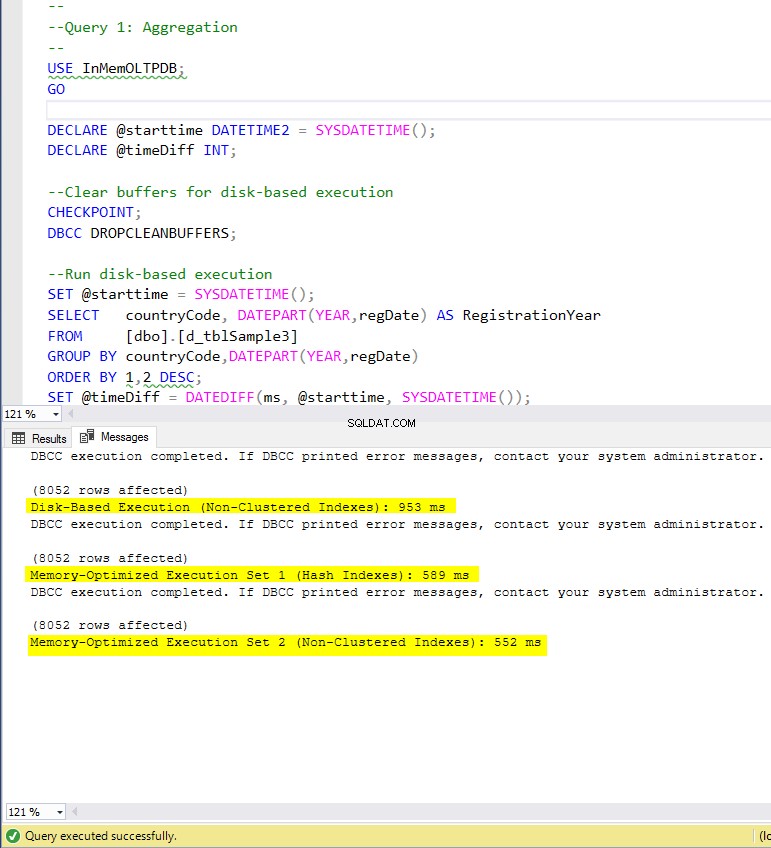
Figur 4:Exekveringstid för fråga 1 (med index).
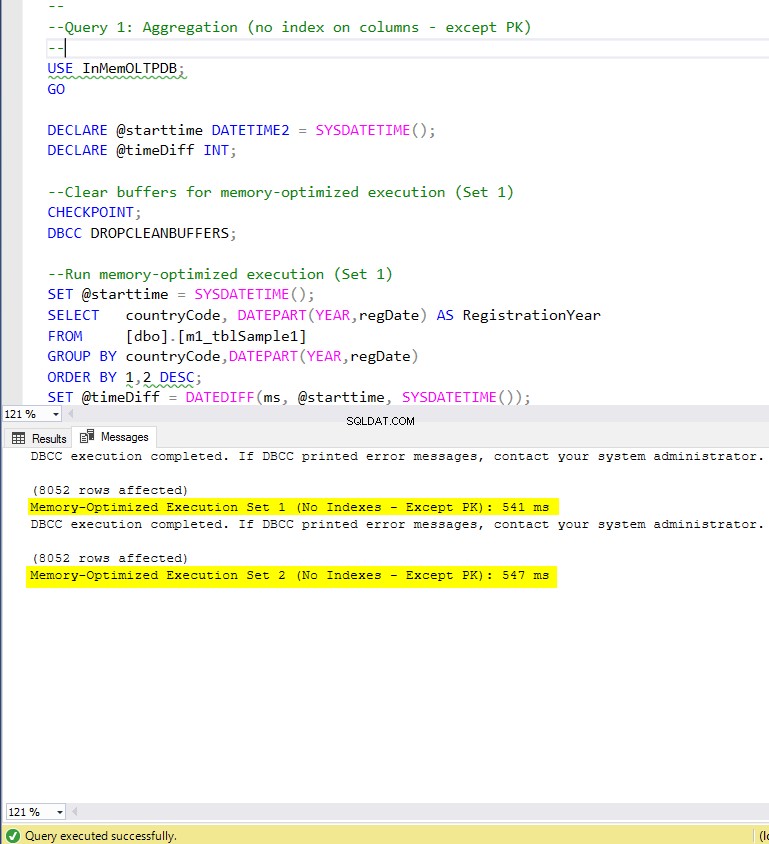
Figur 5:Exekveringstid för fråga 1 (utan index – förutom PK).
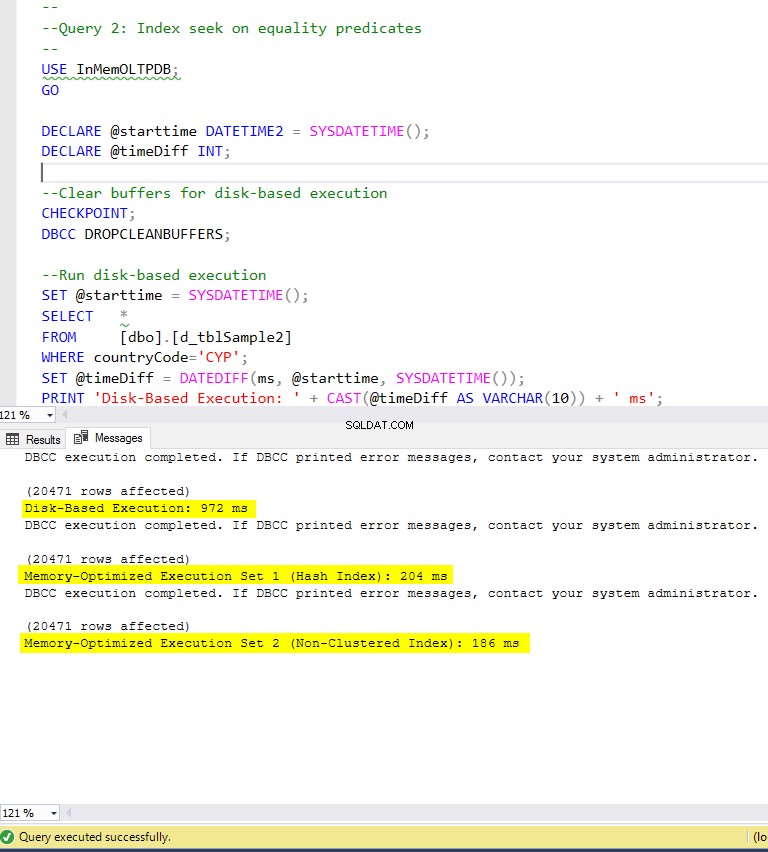
Figur 6:Exekveringstid för fråga 2 (med index).
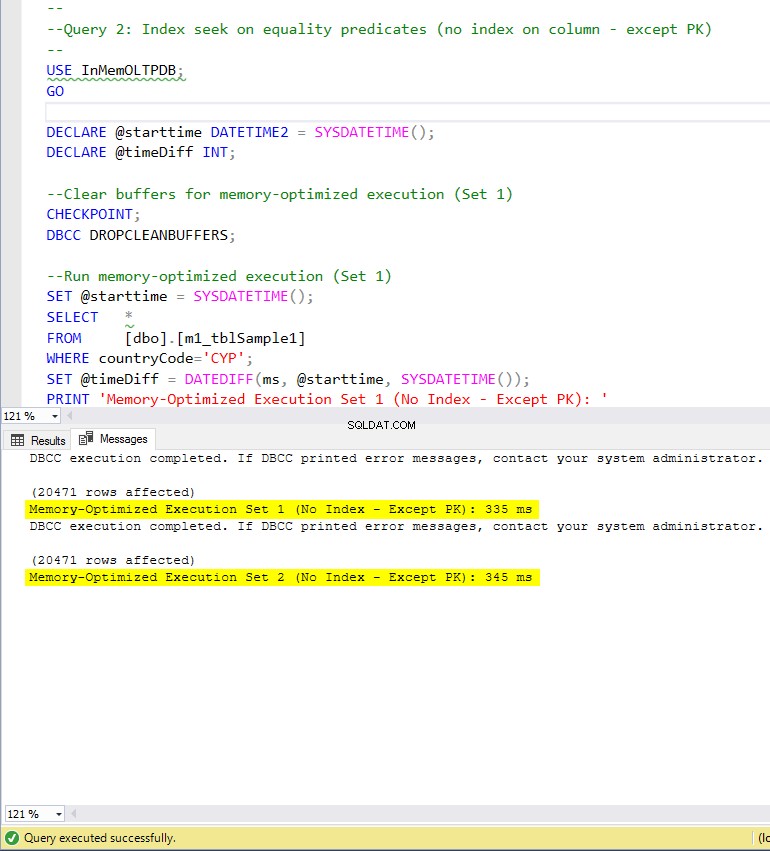
Figur 7:Exekveringstid för fråga 2 (utan index – förutom PK).
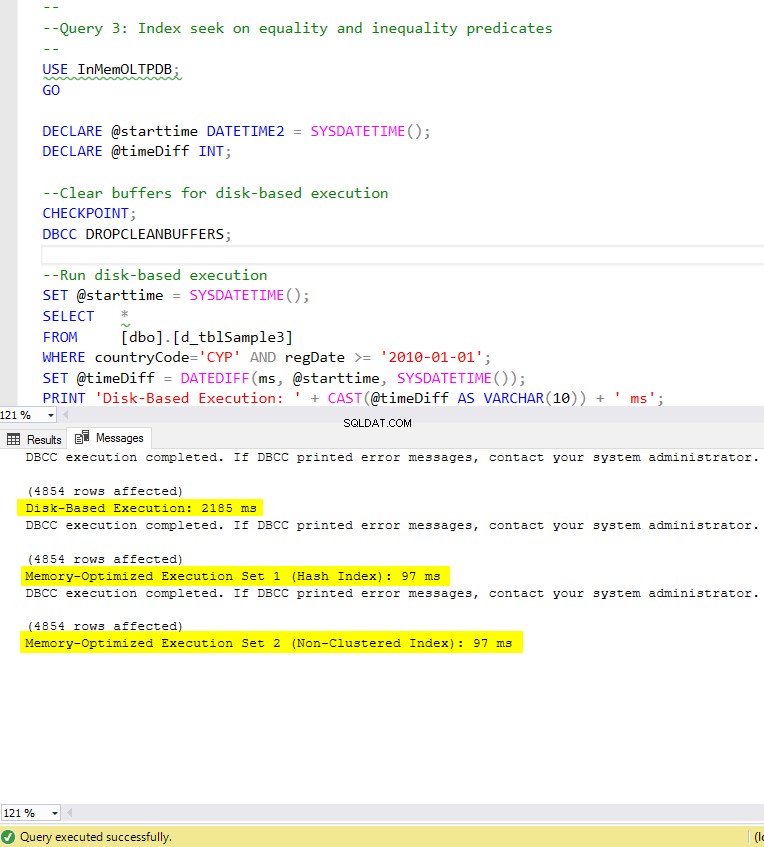
Figur 8:Exekveringstid för fråga 3 (med index).
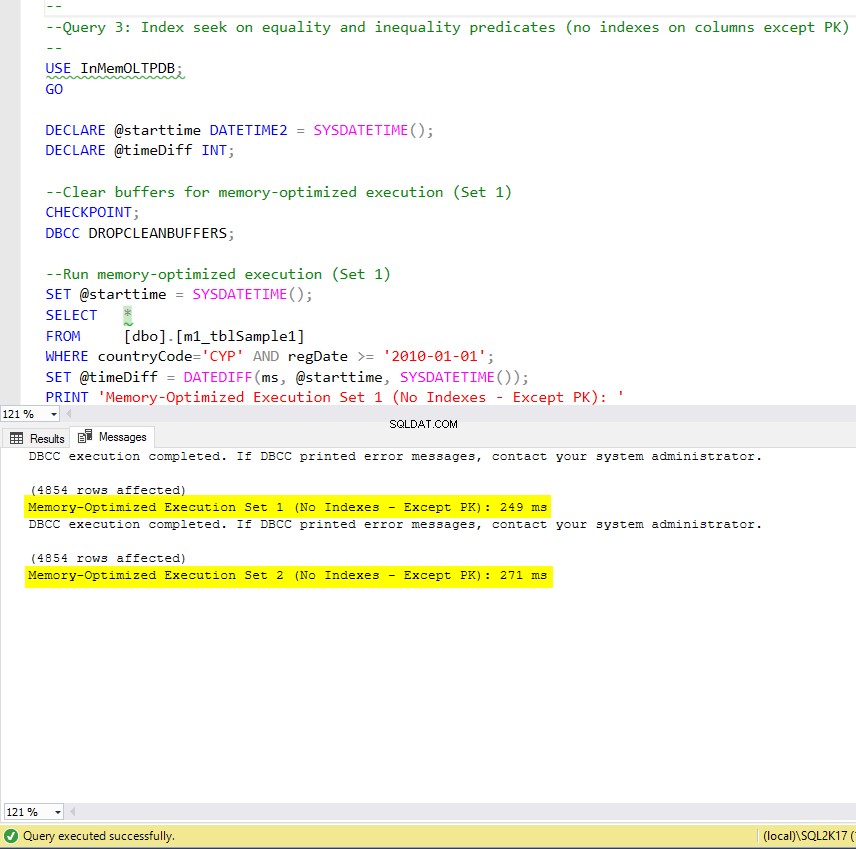
Figur 9:Exekveringstid för fråga 3 (utan index – förutom PK).
Låt oss nu sammanfatta resultaten som erhållits ovan. Följande tabell visar de uppmätta körtiderna för alla ovanstående frågor och tabell/indexkombinationer.
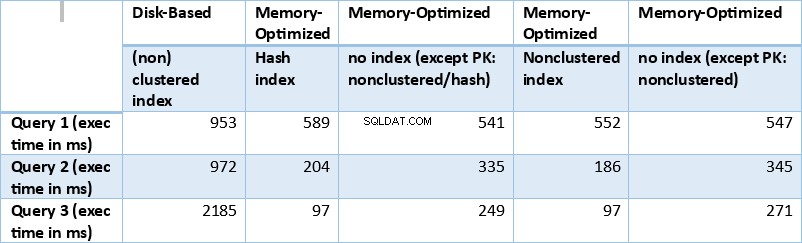
Tabell 1:Sammanfattning av exekveringstider (ms) för alla frågor.
Diskussion
Om vi undersöker exekveringsresultaten som sammanfattas i tabellen ovan kan vi dra vissa slutsatser. Låt oss plotta varje frågeresultat i en graf. Graferna nedan illustrerar exekveringstiderna, såväl som snabbheten för de minnesoptimerade tabellerna över de diskbaserade tabellerna.
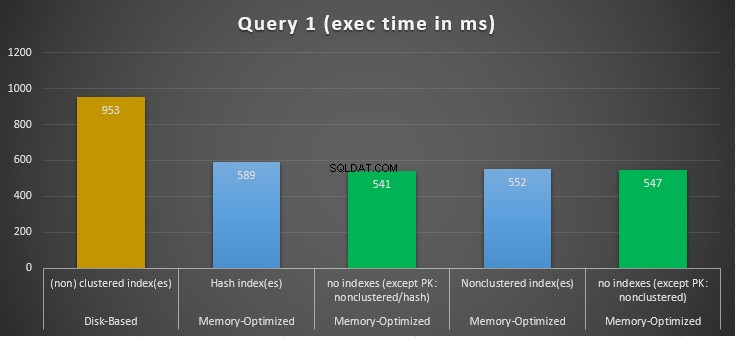
Figur 10:Jämförelse av exekveringstider för fråga 1.
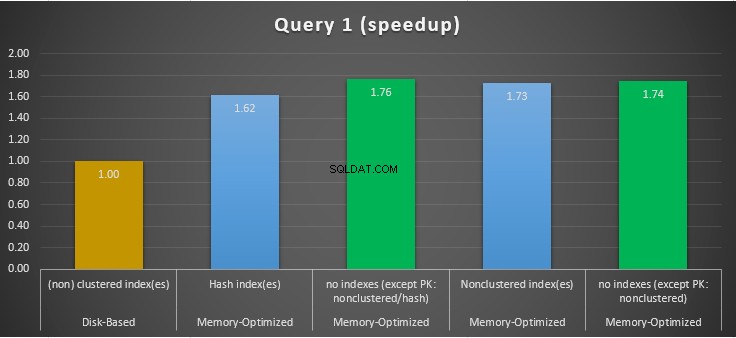
Figur 11:Fråga 1 Speedup-jämförelse.
När det gäller fråga 1, som var en GROUP BY-aggregation, kan vi se att båda versionerna (index vs inga index) av minnesoptimerade tabeller, presterar nästan likadant med en hastighetsuppgång över den diskbaserade tabellen (aktiverad med index) mellan 1,62 och 1,76 gånger snabbare.
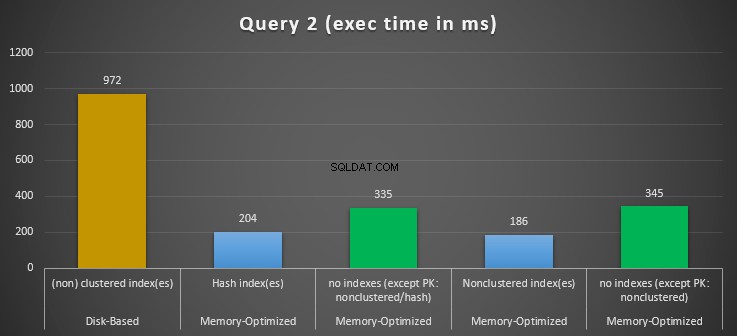
Figur 12:Jämförelse av exekveringstider för fråga 2.
Figur 13:Fråga 2 Speedup Comparison.
När det gäller fråga 2, som involverade en indexsökning på likhetspredikat, kan vi se att de minnesoptimerade tabellerna med index presterade mycket bättre än de minnesoptimerade tabellerna utan index. Dessutom observerar vi att den minnesoptimerade tabellen med icke-klustrade index i kolumnen som används som predikat presterade bättre än den med hashindex.
Så för fråga 2 är vinnaren den minnesoptimerade tabellen med det icke-klustrade indexet, som har en total hastighet på 5,23 gånger snabbare än diskbaserad exekvering.
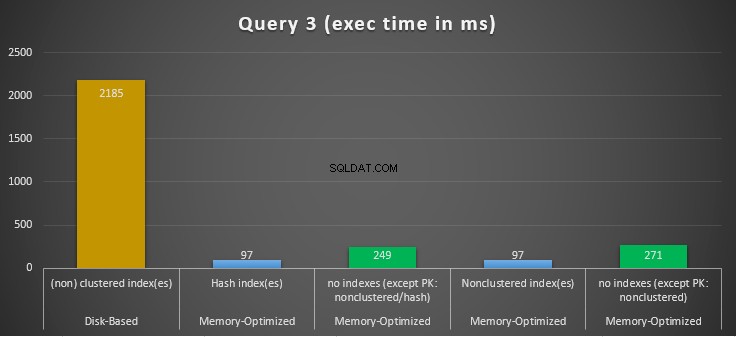
Figur 14:Jämförelse av exekveringstider för fråga 3.
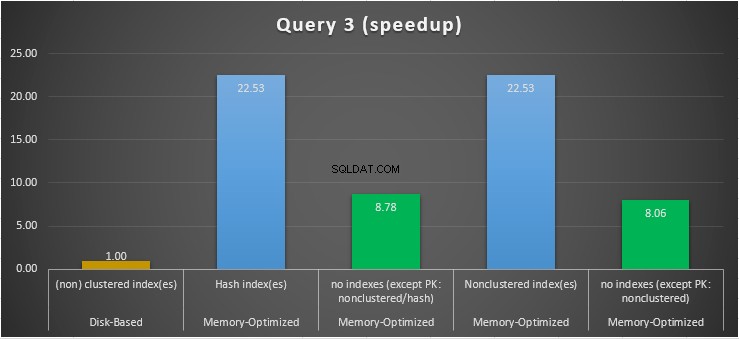
Figur 15:Jämförelse av snabbhet i fråga 3.
När det gäller fråga 3, som involverade en indexsökning på jämlikhet och ojämlikhetspredikat kombinerat, kan vi se att de minnesoptimerade tabellerna med index presterade mycket bättre än de minnesoptimerade tabellerna utan index. Dessutom observerar vi att den minnesoptimerade tabellen med icke-klustrade index i kolumnen som används som predikat fungerade på samma sätt som den med hashindex.
För detta ändamål kan vi se att båda minnesoptimerade tabellerna som använder index i kolumnerna som används som predikat, presterade snabbare än de utan index och uppnådde en hastighet på 22,53 gånger snabbare över diskbaserad körning.
Slutsats
I den här artikeln undersökte vi användningen av index i minnesoptimerade tabeller i SQL Server. Vi använde som baslinje för varje fråga, den bästa möjliga diskbaserade tabellkonfigurationen, och sedan jämförde vi prestandan för tre frågor mot de diskbaserade tabellerna och 4 varianter av minnesoptimerade tabeller. Två av fyra minnesoptimerade tabeller använde index (hash/icke-klustrade) och de andra två använde inga index, förutom de som användes för primärnycklarna.
Den övergripande slutsatsen är att du alltid måste undersöka hur index påverkar prestanda, inte bara för minnesoptimerade tabeller utan även för diskbaserade, och när du identifierar att de förbättrar prestanda, för att använda dem. Resultaten av exemplen i denna artikel visar att om du använder rätt index i minnesoptimerade tabeller kan du uppnå mycket bättre prestanda för frågor som liknar de som används i den här artikeln jämfört med att bara använda minnesoptimerade tabeller utan index .
Referenser och ytterligare läsning:
- Microsoft Docs:Minnesoptimerade tabeller
- Microsoft Docs:Riktlinjer för användning av index på minnesoptimerade tabeller
- Microsoft Docs:Indexer på minnesoptimerade tabeller
Användbart verktyg:
dbForge Index Manager – praktiskt SSMS-tillägg för att analysera status för SQL-index och åtgärda problem med indexfragmentering.