Detta är den första artikeln i en serie artiklar om In-Memory OLTP. Det hjälper dig att förstå hur den nya Hekaton-motorn fungerar internt. Vi kommer att fokusera på detaljer om minnesoptimerade tabeller och index. Det här är artikeln på nybörjarnivå, vilket innebär att du inte behöver vara en SQL Server-expert, men du behöver ha en del grundläggande kunskaper om den traditionella SQL Server-motorn.
Introduktion
SQL Server 2014 In-Memory OLTP-motorn (Hekaton-projektet) skapades från grunden för att utnyttja terabyte tillgängligt minne och ett stort antal bearbetningskärnor. In-Memory OLTP tillåter användare att arbeta med minnesoptimerade tabeller och index, och inbyggt kompilerade lagrade procedurer. Du kan använda den tillsammans med de diskbaserade tabellerna och indexen och T-SQL-lagrade procedurer som SQL Server alltid har tillhandahållit.
In-Memory OLTP-motorns interna funktioner och funktioner skiljer sig markant från standardrelationsmotorn. Du måste revidera nästan allt du visste om hur flera samtidiga processer hanteras.
SQL Server-motorn är optimerad för diskbaserad lagring. Den läser in 8KB datasidor i minnet för bearbetning och skriver 8KB datasidor tillbaka till disken efter modifieringar. Naturligtvis fixar SQL Server främst ändringarna på disken i transaktionsloggen. Att läsa 8 KB datasidor från disk och skriva tillbaka det kan generera mycket I/O och leder till en högre latenskostnad. Även när data i buffertcachen är SQL-servern utformad för att anta att den inte är det, vilket leder till ineffektiv CPU-användning.
Med tanke på begränsningarna hos traditionella diskbaserade lagringsstrukturer började SQL Server-teamet bygga en databasmotor optimerad för stora huvudminnen och processorer med flera kärnor. Teamet satte upp följande mål:
- Optimerad för data som lagrades helt i minnet men som också var hållbar vid omstarter av SQL Server
- Fullt integrerad i den befintliga SQL Server-motorn
- Mycket hög prestanda för OLTP-operationer
- Utformad för moderna processorer
SQL Server In-Memory OLTP uppfyller alla dessa mål.
Om OLTP i minnet
SQL Server 2014 In-Memory OLTP tillhandahåller ett antal tekniker för att arbeta med minnesoptimerade tabeller, tillsammans med de diskbaserade tabellerna. Till exempel låter den dig komma åt data i minnet med hjälp av standardgränssnitt som T-SQL och SSMS. Följande illustration visar minnesoptimerade tabeller och index, som en del av In-Memory OLTP (till vänster) och de diskbaserade tabellerna (till vänster) som kräver att läsa och skriva 8KB datasidor. In-Memory OLTP stöder också inbyggt kompilerade lagrade procedurer och tillhandahåller en ny in-memory OLTP-kompilator.
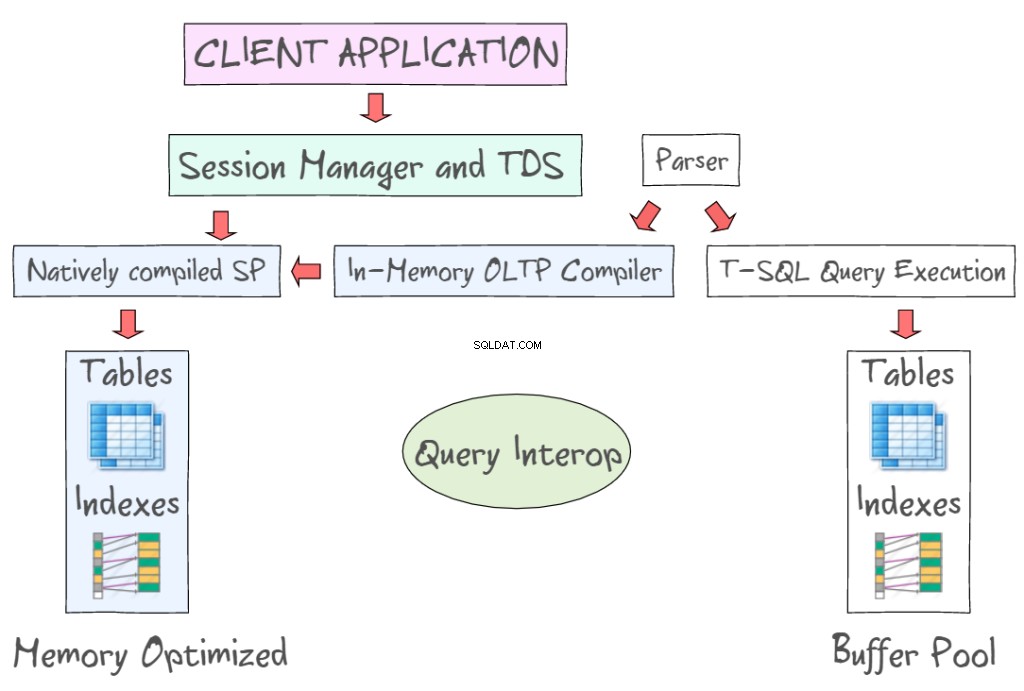
Query Interop tillåter tolkning av T-SQL för att referera till minnesoptimerade tabeller. Om en transaktion refererar till både minnesoptimerade och diskbaserade tabeller, kan den hänvisas till som s cross-container-transaktion. Klientappen använder Tabular Data Stream – ett applikationslagerprotokoll som används för att överföra data mellan en databasserver och en klient. Den designades och utvecklades ursprungligen av Sybase Inc. för deras Sybase SQL Server relationsdatabasmotor 1984, och senare av Microsoft i Microsoft SQL Server.
Minnesoptimerade tabeller
När du kommer åt diskbaserade tabeller kan de nödvändiga data redan finnas i minnet även om det inte är det. Om data inte finns i minnet måste SQL Server läsa den från disken. Den mest grundläggande skillnaden när du använder minnesoptimerade tabeller är att hela tabellen och dess index lagras i minnet hela tiden . Samtidiga dataoperationer kräver ingen låsning eller låsning.
Medan en användare modifierar data i minnet, utför SQL Server vissa disk I/O för alla tabeller som måste vara hållbara, annars sett, där vi behöver en tabell för att behålla data i minnet vid tidpunkten för en serverkrasch eller omstart.
Radbaserad lagringsstruktur
En annan betydande skillnad är den underliggande lagringsstrukturen. De diskbaserade tabellerna är optimerade för blockadresserbara disklagring, medan minnesoptimerade tabeller är optimerade för byteadresserbara minneslagring.
SQL Server håller datarader på 8K-datasidor, med utrymmesallokering från omfattningar för diskbaserade tabeller. Datasidan är den grundläggande enheten för disk- och minneslagring. När du läser och skriver data från disk, läser och skriver SQL Server endast relevanta datasidor. En datasida kommer bara att innehålla data från en tabell eller ett index. Ansökningsprocesser ändrar rader på olika datasidor efter behov. Senare, under CHECKPOINT-operationen, fixar SQL Server först loggposterna till disken och skriver sedan alla smutsiga sidor till disken. Denna operation orsakar ofta många slumpmässiga fysiska I/O.
För minnesoptimerade tabeller finns det inga datasidor, liksom inga omfattningar. Det finns bara datarader som skrivs till minnet sekventiellt, i den ordning som transaktionerna inträffade. Varje rad innehåller en indexpekare till nästa rad. All I/O är skanning i minnet av dessa strukturer. Det finns ingen idé om att datarader skrivs till en viss plats som tillhör ett specificerat objekt. Även om du inte behöver tro att minnesoptimerade tabeller lagras som den oorganiserade uppsättningen datarader (liknande diskbaserade heaps). Varje CREATE TABLE-sats för en minnesoptimerad tabell skapar minst ett index som SQL Server använder för att länka samman alla datarader i den tabellen.
Varje enskild datarad består av radrubriken och nyttolasten som är den faktiska kolumndatan. Rubriken lagrar information om satsen som skapade raden, pekare för varje index på måltabellen och tidsstämpelvärden. Tidsstämpel anger den tid då en transaktion infogade och raderade en rad. SQL Server-poster uppdateras genom att infoga en ny radversion och markera den gamla versionen som raderad. Flera versioner av samma rad kan finnas vid varje given tidpunkt. Detta tillåter samtidig åtkomst till samma rad under datamodifieringen. SQL Server visar radversionen som är relevant för varje transaktion enligt den tidpunkt då transaktionen startade i förhållande till tidsstämplarna för radversionen. Detta är kärnan i den nya multiversionskontrollen för samtidighet mekanism för tabeller i minnet.
Oracle har förresten ett utmärkt kontrollsystem för flera versioner. I grund och botten fungerar det enligt följande:
- Användare A startar en transaktion och uppdaterar 1000 rader med något värde vid tidpunkten T1.
- Användare B läser samma 1000 rader vid tidpunkt T2.
- Användare A uppdaterar rad 565 med värdet Y (det ursprungliga värdet var X).
- Användare B når rad 565 och upptäcker att en transaktion är i drift sedan tid T1.
- Databasen returnerar den oförändrade posten från loggarna. Det returnerade värdet är det värde som begicks vid tidpunkten mindre än eller lika med T2.
- Om posten inte kunde hämtas från redo-loggarna betyder det att databasen inte är korrekt inställd. Mer utrymme måste tilldelas loggarna.
- De returnerade resultaten är alltid desamma med avseende på starttiden för transaktionen. Så inom transaktionen uppnås läskonsistensen.
Intebyggt kompilerade tabeller
Den sista stora skillnaden är att de i minnet optimerade tabellerna är naturligt kompilerade . När en användare skapar en minnesoptimerad tabell eller index, lagrar SQL Server strukturen för varje tabell (tillsammans med alla index) i metadata. Senare använder SQL Server denna metadata för att kompilera till DDL en uppsättning modersmålsrutiner för åtkomst till tabellen. Sådana DDL är associerade med databasen men är faktiskt inte en del av den.
Med andra ord lagrar SQL Server i minnet inte bara tabeller och index utan även DDL för att komma åt och ändra dessa strukturer. När en tabell väl har ändrats måste SQL Server återskapa all DDL för tabelloperationer. Det är därför du inte kan ändra en tabell när den väl har skapats. Dessa operationer är osynliga för användarna.
Natively kompilerade lagrade procedurer
Bästa prestanda uppnås samtidigt som man använder inbyggt kompilerade lagrade procedurer för att komma åt inbyggda kompilerade tabeller. Sådana procedurer innehåller processorinstruktioner och kan exekveras direkt av CPU utan ytterligare kompilering. Det finns dock vissa begränsningar för T-SQL-konstruktionerna för de inbyggt kompilerade lagrade procedurerna (jämfört med traditionellt tolkad kod). En annan viktig punkt är att inbyggt kompilerade lagrade procedurer endast kan komma åt minnesoptimerade tabeller.
Inga lås
In-Memory OLTP är ett låsfritt system. Detta är möjligt eftersom SQL Server aldrig ändrar någon befintlig rad. UPDATE-operationen skapar den nya versionen och markerar den tidigare versionen som borttagen. Sedan infogar den en ny radversion med ny data inuti.
Index
Som du kanske har gissat skiljer sig index mycket från de traditionella. In-memory-optimerade tabeller har inga sidor. SQL Server använder index för att länka alla rader som hör till en tabell till en enda struktur. Vi kan inte använda CREATE INDEX-satsen för att skapa ett index för den i minnet optimerade tabellen. När du har skapat den PRIMÄRA KEY på en kolumn, skapar SQL Server automatiskt ett unikt index på den kolumnen. Egentligen är det det enda tillåtna unika indexet. Du kan skapa maximalt åtta index på en minnesoptimerad tabell.
I analogi med tabeller håller SQL Server minnesoptimerade index i minnet. SQL Server loggar dock aldrig operationer på index. SQL Server underhåller index automatiskt under tabelländringar.
Minnesoptimerade tabeller stöder två typer av index:hashindex och intervallindex . Båda är icke-klustrade strukturer.
hashindexet är en ny typ av index, designad speciellt för minnesoptimerade tabeller. Det är extremt användbart för att utföra sökningar på specifika värden. Själva indexet lagras som en hashtabell. Det är en uppsättning hash-hinkar, där varje hink är en pekare till en enda rad.
intervallindexet (icke-klustrade) är användbart för att hämta värdeintervall.
Återställning
Den grundläggande återställningsmekanismen för en databas med minnesoptimerade tabeller är densamma som återställningsmekanismen för databaser med diskbaserade tabeller. Återställning av minnesoptimerade tabeller inkluderar dock steget att ladda de minnesoptimerade tabellerna i minnet innan databasen är tillgänglig för användaråtkomst.
När SQL Server startar om går varje databas igenom följande faser av återställningsprocessen:analys , gör om och ångra .
I analysfasen identifierar In-Memory OLTP-motorn kontrollpunktsinventeringen som ska laddas och förladdar dess systemtabellsloggposter. Det kommer också att bearbeta vissa filallokeringsloggposter.
I redo-fasen laddas data från data- och deltafilparen in i minnet. Sedan uppdateras data från den aktiva transaktionsloggen baserat på den senaste hållbara kontrollpunkten och tabellerna i minnet fylls i och indexen byggs om. Under denna fas körs diskbaserad och minnesoptimerad tabellåterställning samtidigt.
Ångra-fasen behövs inte för minnesoptimerade tabeller eftersom In-Memory OLTP inte registrerar några oengagerade transaktioner för minnesoptimerade tabeller.
När alla operationer är klara är databasen tillgänglig för åtkomst.
Sammanfattning
I den här artikeln tog vi en snabb titt på SQL Server In-Memory OLTP-motorn. Vi har lärt oss att minnesoptimerade strukturer lagras i minnet. Applikationsprocesser kan hitta de data som krävs genom att komma åt dessa strukturer i minnet utan behov av disk I/O. I följande artiklar kommer vi att ta en titt på hur man skapar och får åtkomst till In-Memory OLTP-databaser och tabeller.
Mer läsning
In-Memory OLTP:Vad är nytt i SQL Server 2016
Använda index i SQL Server-minnesoptimerade tabeller